 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePromptception: How Sensitive Are Large Multimodal Models to Prompts?
Sep 04, 2025Despite the success of Large Multimodal Models (LMMs) in recent years, prompt design for LMMs in Multiple-Choice Question Answering (MCQA) remains poorly understood. We show that even minor variations in prompt phrasing and structure can lead to accuracy deviations of up to 15% for certain prompts and models. This variability poses a challenge for transparent and fair LMM evaluation, as models often report their best-case performance using carefully selected prompts. To address this, we introduce Promptception, a systematic framework for evaluating prompt sensitivity in LMMs. It consists of 61 prompt types, spanning 15 categories and 6 supercategories, each targeting specific aspects of prompt formulation, and is used to evaluate 10 LMMs ranging from lightweight open-source models to GPT-4o and Gemini 1.5 Pro, across 3 MCQA benchmarks: MMStar, MMMU-Pro, MVBench. Our findings reveal that proprietary models exhibit greater sensitivity to prompt phrasing, reflecting tighter alignment with instruction semantics, while open-source models are steadier but struggle with nuanced and complex phrasing. Based on this analysis, we propose Prompting Principles tailored to proprietary and open-source LMMs, enabling more robust and fair model evaluation.
UniMed-CLIP: Towards a Unified Image-Text Pretraining Paradigm for Diverse Medical Imaging Modalities
Dec 13, 2024



Vision-Language Models (VLMs) trained via contrastive learning have achieved notable success in natural image tasks. However, their application in the medical domain remains limited due to the scarcity of openly accessible, large-scale medical image-text datasets. Existing medical VLMs either train on closed-source proprietary or relatively small open-source datasets that do not generalize well. Similarly, most models remain specific to a single or limited number of medical imaging domains, again restricting their applicability to other modalities. To address this gap, we introduce UniMed, a large-scale, open-source multi-modal medical dataset comprising over 5.3 million image-text pairs across six diverse imaging modalities: X-ray, CT, MRI, Ultrasound, Pathology, and Fundus. UniMed is developed using a data-collection framework that leverages Large Language Models (LLMs) to transform modality-specific classification datasets into image-text formats while incorporating existing image-text data from the medical domain, facilitating scalable VLM pretraining. Using UniMed, we trained UniMed-CLIP, a unified VLM for six modalities that significantly outperforms existing generalist VLMs and matches modality-specific medical VLMs, achieving notable gains in zero-shot evaluations. For instance, UniMed-CLIP improves over BiomedCLIP (trained on proprietary data) by an absolute gain of +12.61, averaged over 21 datasets, while using 3x less training data. To facilitate future research, we release UniMed dataset, training codes, and models at https://github.com/mbzuai-oryx/UniMed-CLIP.
XDT-CXR: Investigating Cross-Disease Transferability in Zero-Shot Binary Classification of Chest X-Rays
Aug 21, 2024



This study explores the concept of cross-disease transferability (XDT) in medical imaging, focusing on the potential of binary classifiers trained on one disease to perform zero-shot classification on another disease affecting the same organ. Utilizing chest X-rays (CXR) as the primary modality, we investigate whether a model trained on one pulmonary disease can make predictions about another novel pulmonary disease, a scenario with significant implications for medical settings with limited data on emerging diseases. The XDT framework leverages the embedding space of a vision encoder, which, through kernel transformation, aids in distinguishing between diseased and non-diseased classes in the latent space. This capability is especially beneficial in resource-limited environments or in regions with low prevalence of certain diseases, where conventional diagnostic practices may fail. However, the XDT framework is currently limited to binary classification, determining only the presence or absence of a disease rather than differentiating among multiple diseases. This limitation underscores the supplementary role of XDT to traditional diagnostic tests in clinical settings. Furthermore, results show that XDT-CXR as a framework is able to make better predictions compared to other zero-shot learning (ZSL) baselines.
How Good is my Video LMM? Complex Video Reasoning and Robustness Evaluation Suite for Video-LMMs
May 08, 2024



Recent advancements in Large Language Models (LLMs) have led to the development of Video Large Multi-modal Models (Video-LMMs) that can handle a wide range of video understanding tasks. These models have the potential to be deployed in real-world applications such as robotics, AI assistants, medical surgery, and autonomous vehicles. The widespread adoption of Video-LMMs in our daily lives underscores the importance of ensuring and evaluating their robust performance in mirroring human-like reasoning and interaction capabilities in complex, real-world contexts. However, existing benchmarks for Video-LMMs primarily focus on general video comprehension abilities and neglect assessing their reasoning capabilities over complex videos in the real-world context, and robustness of these models through the lens of user prompts as text queries. In this paper, we present the Complex Video Reasoning and Robustness Evaluation Suite (CVRR-ES), a novel benchmark that comprehensively assesses the performance of Video-LMMs across 11 diverse real-world video dimensions. We evaluate 9 recent models, including both open-source and closed-source variants, and find that most of the Video-LMMs, especially open-source ones, struggle with robustness and reasoning when dealing with complex videos. Based on our analysis, we develop a training-free Dual-Step Contextual Prompting (DSCP) technique to enhance the performance of existing Video-LMMs. Our findings provide valuable insights for building the next generation of human-centric AI systems with advanced robustness and reasoning capabilities. Our dataset and code are publicly available at: https://mbzuai-oryx.github.io/CVRR-Evaluation-Suite/.
Complex Video Reasoning and Robustness Evaluation Suite for Video-LMMs
May 06, 2024Recent advancements in Large Language Models (LLMs) have led to the development of Video Large Multi-modal Models (Video-LMMs) that can handle a wide range of video understanding tasks. These models have the potential to be deployed in real-world applications such as robotics, AI assistants, medical imaging, and autonomous vehicles. The widespread adoption of Video-LMMs in our daily lives underscores the importance of ensuring and evaluating their robust performance in mirroring human-like reasoning and interaction capabilities in complex, real-world contexts. However, existing benchmarks for Video-LMMs primarily focus on general video comprehension abilities and neglect assessing their reasoning capabilities over complex videos in the real-world context, and robustness of these models through the lens of user prompts as text queries. In this paper, we present the Complex Video Reasoning and Robustness Evaluation Suite (CVRR-ES), a novel benchmark that comprehensively assesses the performance of Video-LMMs across 11 diverse real-world video dimensions. We evaluate 9 recent models, including both open-source and closed-source variants, and find that most of the Video-LMMs, {especially open-source ones,} struggle with robustness and reasoning when dealing with complex videos. Based on our analysis, we develop a training-free Dual-Step Contextual Prompting (DSCP) technique to enhance the performance of existing Video-LMMs. Our findings provide valuable insights for building the next generation of human-centric AI systems with advanced robustness and reasoning capabilities. Our dataset and code are publicly available at: https://mbzuai-oryx.github.io/CVRR-Evaluation-Suite/.
Learning to Prompt with Text Only Supervision for Vision-Language Models
Jan 04, 2024
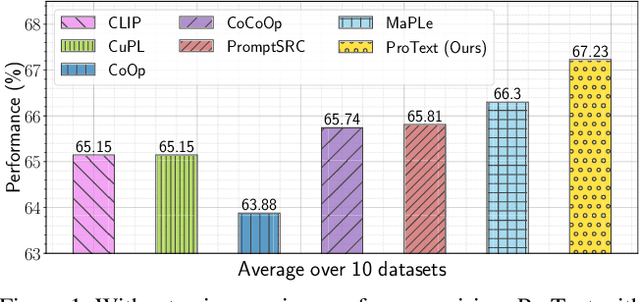
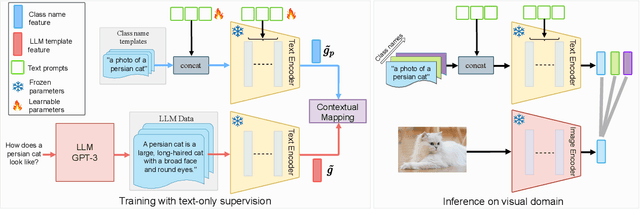
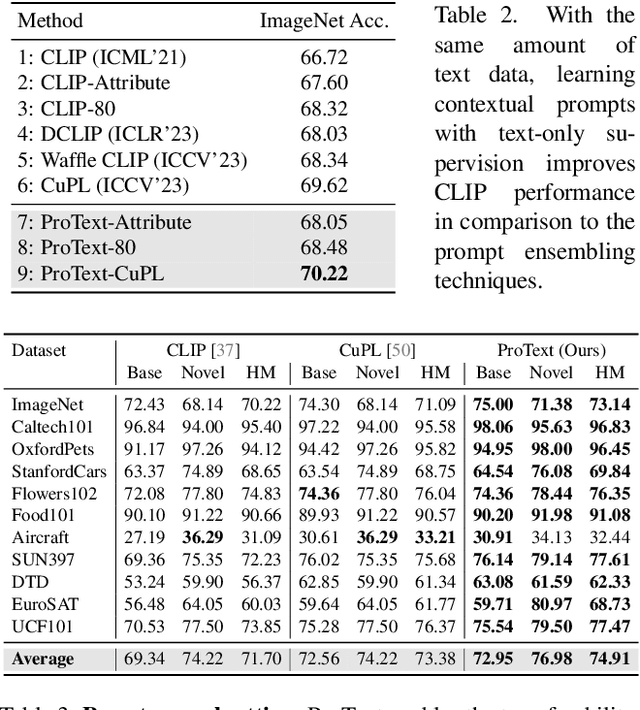
Foundational vision-language models such as CLIP are becoming a new paradigm in vision, due to their excellent generalization abilities. However, adapting these models for downstream tasks while maintaining their generalization remains a challenge. In literature, one branch of methods adapts CLIP by learning prompts using visual information. While effective, most of these works require labeled data which is not practical, and often struggle to generalize towards new datasets due to over-fitting on the source data. An alternative approach resorts to training-free methods by generating class descriptions from large language models (LLMs) and perform prompt ensembling. However, these methods often generate class specific prompts that cannot be transferred to other classes, which incur higher costs by generating LLM descriptions for each class separately. In this work, we propose to combine the strengths of these both streams of methods by learning prompts using only text data derived from LLMs. As supervised training of prompts is not trivial due to absence of images, we develop a training approach that allows prompts to extract rich contextual knowledge from LLM data. Moreover, with LLM contextual data mapped within the learned prompts, it enables zero-shot transfer of prompts to new classes and datasets potentially cutting the LLM prompt engineering cost. To the best of our knowledge, this is the first work that learns generalized prompts using text only data. We perform extensive evaluations on 4 benchmarks where our method improves over prior ensembling works while being competitive to those utilizing labeled images. Our code and pre-trained models are available at https://github.com/muzairkhattak/ProText.
Align Your Prompts: Test-Time Prompting with Distribution Alignment for Zero-Shot Generalization
Nov 02, 2023



The promising zero-shot generalization of vision-language models such as CLIP has led to their adoption using prompt learning for numerous downstream tasks. Previous works have shown test-time prompt tuning using entropy minimization to adapt text prompts for unseen domains. While effective, this overlooks the key cause for performance degradation to unseen domains -- distribution shift. In this work, we explicitly handle this problem by aligning the out-of-distribution (OOD) test sample statistics to those of the source data using prompt tuning. We use a single test sample to adapt multi-modal prompts at test time by minimizing the feature distribution shift to bridge the gap in the test domain. Evaluating against the domain generalization benchmark, our method improves zero-shot top- 1 accuracy beyond existing prompt-learning techniques, with a 3.08% improvement over the baseline MaPLe. In cross-dataset generalization with unseen categories across 10 datasets, our method improves consistently across all datasets compared to the existing state-of-the-art. Our source code and models are available at https://jameelhassan.github.io/promptalign.
Video-FocalNets: Spatio-Temporal Focal Modulation for Video Action Recognition
Jul 16, 2023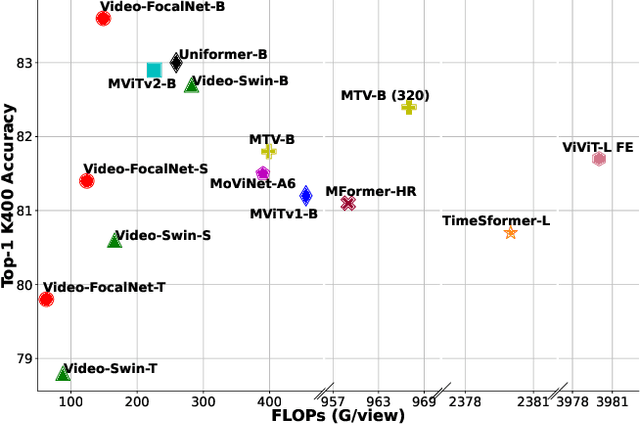
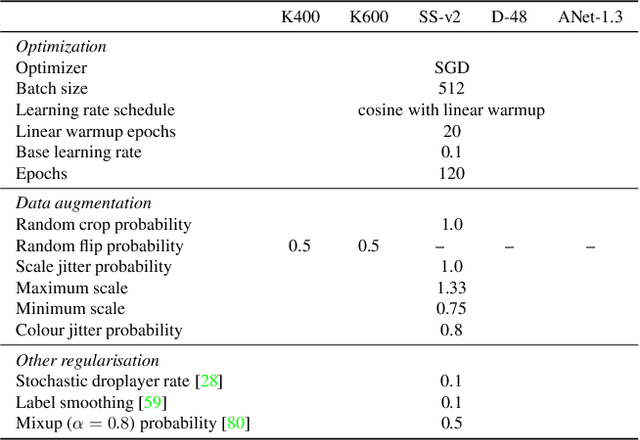
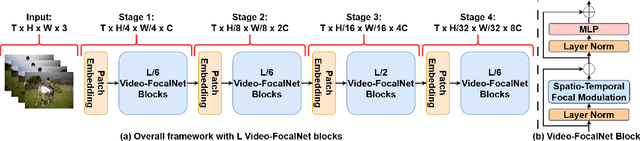
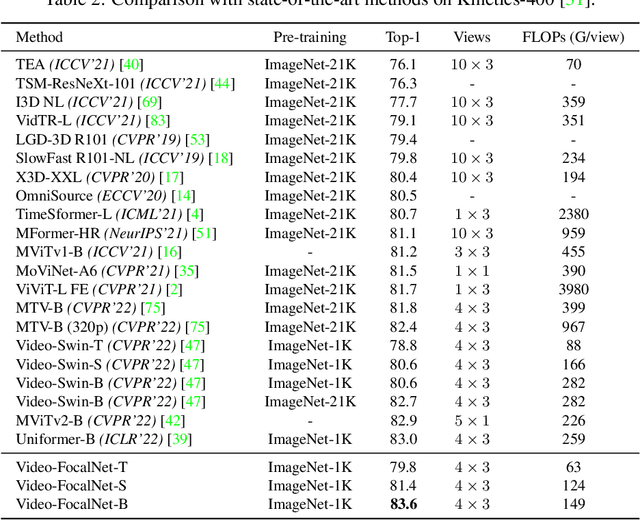
Recent video recognition models utilize Transformer models for long-range spatio-temporal context modeling. Video transformer designs are based on self-attention that can model global context at a high computational cost. In comparison, convolutional designs for videos offer an efficient alternative but lack long-range dependency modeling. Towards achieving the best of both designs, this work proposes Video-FocalNet, an effective and efficient architecture for video recognition that models both local and global contexts. Video-FocalNet is based on a spatio-temporal focal modulation architecture that reverses the interaction and aggregation steps of self-attention for better efficiency. Further, the aggregation step and the interaction step are both implemented using efficient convolution and element-wise multiplication operations that are computationally less expensive than their self-attention counterparts on video representations. We extensively explore the design space of focal modulation-based spatio-temporal context modeling and demonstrate our parallel spatial and temporal encoding design to be the optimal choice. Video-FocalNets perform favorably well against the state-of-the-art transformer-based models for video recognition on three large-scale datasets (Kinetics-400, Kinetics-600, and SS-v2) at a lower computational cost. Our code/models are released at https://github.com/TalalWasim/Video-FocalNets.
Self-regulating Prompts: Foundational Model Adaptation without Forgetting
Jul 13, 2023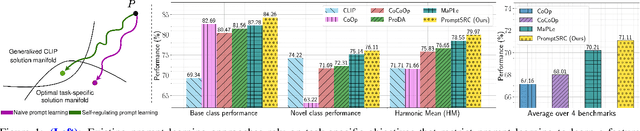
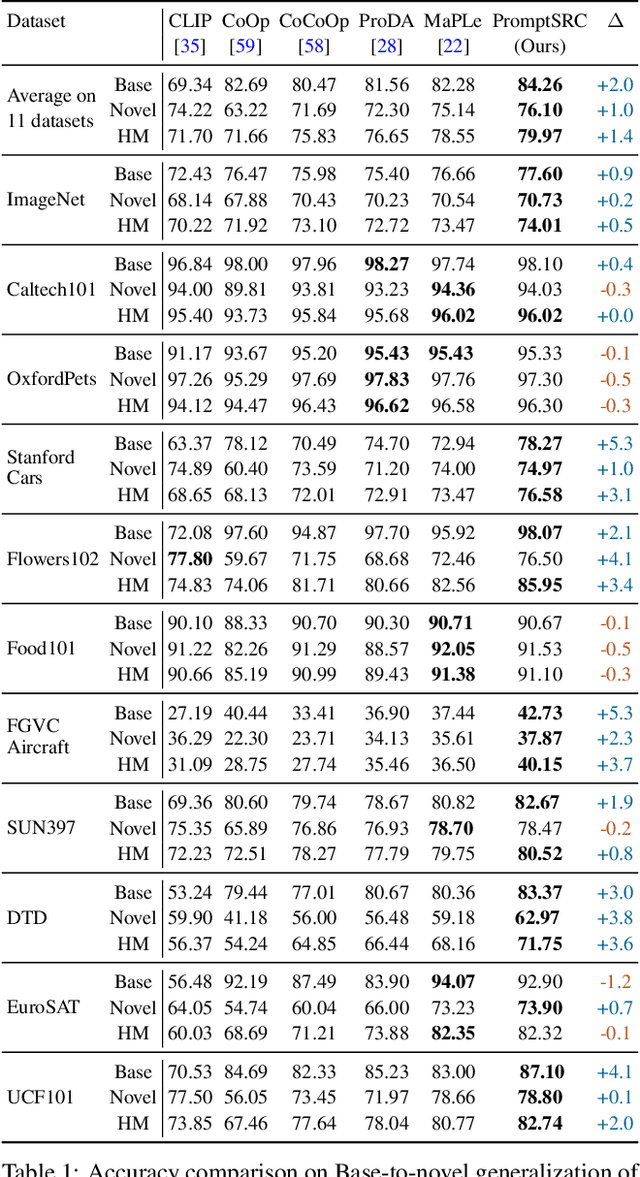
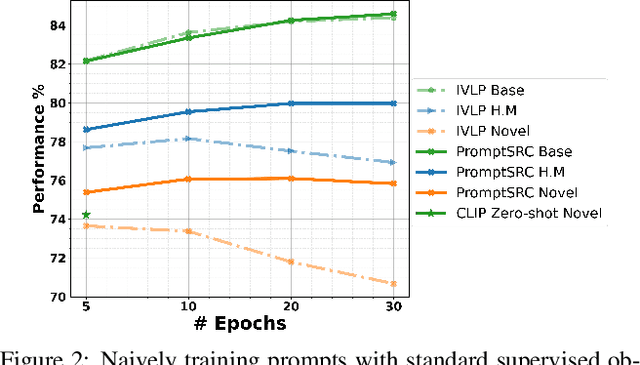

Prompt learning has emerged as an efficient alternative for fine-tuning foundational models, such as CLIP, for various downstream tasks. Conventionally trained using the task-specific objective, i.e., cross-entropy loss, prompts tend to overfit downstream data distributions and find it challenging to capture task-agnostic general features from the frozen CLIP. This leads to the loss of the model's original generalization capability. To address this issue, our work introduces a self-regularization framework for prompting called PromptSRC (Prompting with Self-regulating Constraints). PromptSRC guides the prompts to optimize for both task-specific and task-agnostic general representations using a three-pronged approach by: (a) regulating {prompted} representations via mutual agreement maximization with the frozen model, (b) regulating with self-ensemble of prompts over the training trajectory to encode their complementary strengths, and (c) regulating with textual diversity to mitigate sample diversity imbalance with the visual branch. To the best of our knowledge, this is the first regularization framework for prompt learning that avoids overfitting by jointly attending to pre-trained model features, the training trajectory during prompting, and the textual diversity. PromptSRC explicitly steers the prompts to learn a representation space that maximizes performance on downstream tasks without compromising CLIP generalization. We perform extensive experiments on 4 benchmarks where PromptSRC overall performs favorably well compared to the existing methods. Our code and pre-trained models are publicly available at: https://github.com/muzairkhattak/PromptSRC.
Fine-tuned CLIP Models are Efficient Video Learners
Dec 06, 2022



Large-scale multi-modal training with image-text pairs imparts strong generalization to CLIP model. Since training on a similar scale for videos is infeasible, recent approaches focus on the effective transfer of image-based CLIP to the video domain. In this pursuit, new parametric modules are added to learn temporal information and inter-frame relationships which require meticulous design efforts. Furthermore, when the resulting models are learned on videos, they tend to overfit on the given task distribution and lack in generalization aspect. This begs the following question: How to effectively transfer image-level CLIP representations to videos? In this work, we show that a simple Video Fine-tuned CLIP (ViFi-CLIP) baseline is generally sufficient to bridge the domain gap from images to videos. Our qualitative analysis illustrates that the frame-level processing from CLIP image-encoder followed by feature pooling and similarity matching with corresponding text embeddings helps in implicitly modeling the temporal cues within ViFi-CLIP. Such fine-tuning helps the model to focus on scene dynamics, moving objects and inter-object relationships. For low-data regimes where full fine-tuning is not viable, we propose a `bridge and prompt' approach that first uses fine-tuning to bridge the domain gap and then learns prompts on language and vision side to adapt CLIP representations. We extensively evaluate this simple yet strong baseline on zero-shot, base-to-novel generalization, few-shot and fully supervised settings across five video benchmarks. Our code is available at https://github.com/muzairkhattak/ViFi-CLIP.