 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRedSage: A Cybersecurity Generalist LLM
Jan 29, 2026Cybersecurity operations demand assistant LLMs that support diverse workflows without exposing sensitive data. Existing solutions either rely on proprietary APIs with privacy risks or on open models lacking domain adaptation. To bridge this gap, we curate 11.8B tokens of cybersecurity-focused continual pretraining data via large-scale web filtering and manual collection of high-quality resources, spanning 28.6K documents across frameworks, offensive techniques, and security tools. Building on this, we design an agentic augmentation pipeline that simulates expert workflows to generate 266K multi-turn cybersecurity samples for supervised fine-tuning. Combined with general open-source LLM data, these resources enable the training of RedSage, an open-source, locally deployable cybersecurity assistant with domain-aware pretraining and post-training. To rigorously evaluate the models, we introduce RedSage-Bench, a benchmark with 30K multiple-choice and 240 open-ended Q&A items covering cybersecurity knowledge, skills, and tool expertise. RedSage is further evaluated on established cybersecurity benchmarks (e.g., CTI-Bench, CyberMetric, SECURE) and general LLM benchmarks to assess broader generalization. At the 8B scale, RedSage achieves consistently better results, surpassing the baseline models by up to +5.59 points on cybersecurity benchmarks and +5.05 points on Open LLM Leaderboard tasks. These findings demonstrate that domain-aware agentic augmentation and pre/post-training can not only enhance cybersecurity-specific expertise but also help to improve general reasoning and instruction-following. All models, datasets, and code are publicly available.
Analysing the Robustness of Vision-Language-Models to Common Corruptions
Apr 21, 2025
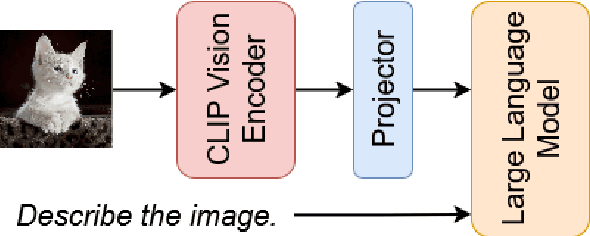
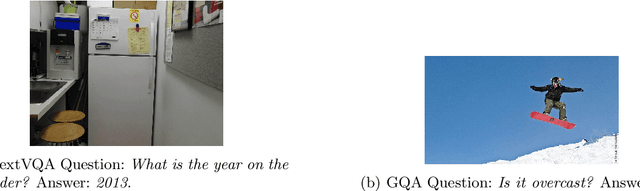
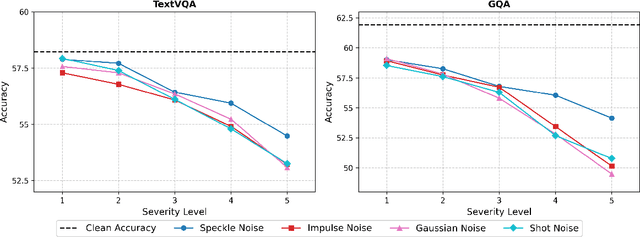
Vision-language models (VLMs) have demonstrated impressive capabilities in understanding and reasoning about visual and textual content. However, their robustness to common image corruptions remains under-explored. In this work, we present the first comprehensive analysis of VLM robustness across 19 corruption types from the ImageNet-C benchmark, spanning four categories: noise, blur, weather, and digital distortions. We introduce two new benchmarks, TextVQA-C and GQA-C, to systematically evaluate how corruptions affect scene text understanding and object-based reasoning, respectively. Our analysis reveals that transformer-based VLMs exhibit distinct vulnerability patterns across tasks: text recognition deteriorates most severely under blur and snow corruptions, while object reasoning shows higher sensitivity to corruptions such as frost and impulse noise. We connect these observations to the frequency-domain characteristics of different corruptions, revealing how transformers' inherent bias toward low-frequency processing explains their differential robustness patterns. Our findings provide valuable insights for developing more corruption-robust vision-language models for real-world applications.
STING-BEE: Towards Vision-Language Model for Real-World X-ray Baggage Security Inspection
Apr 03, 2025Advancements in Computer-Aided Screening (CAS) systems are essential for improving the detection of security threats in X-ray baggage scans. However, current datasets are limited in representing real-world, sophisticated threats and concealment tactics, and existing approaches are constrained by a closed-set paradigm with predefined labels. To address these challenges, we introduce STCray, the first multimodal X-ray baggage security dataset, comprising 46,642 image-caption paired scans across 21 threat categories, generated using an X-ray scanner for airport security. STCray is meticulously developed with our specialized protocol that ensures domain-aware, coherent captions, that lead to the multi-modal instruction following data in X-ray baggage security. This allows us to train a domain-aware visual AI assistant named STING-BEE that supports a range of vision-language tasks, including scene comprehension, referring threat localization, visual grounding, and visual question answering (VQA), establishing novel baselines for multi-modal learning in X-ray baggage security. Further, STING-BEE shows state-of-the-art generalization in cross-domain settings. Code, data, and models are available at https://divs1159.github.io/STING-BEE/.
Video-Panda: Parameter-efficient Alignment for Encoder-free Video-Language Models
Dec 24, 2024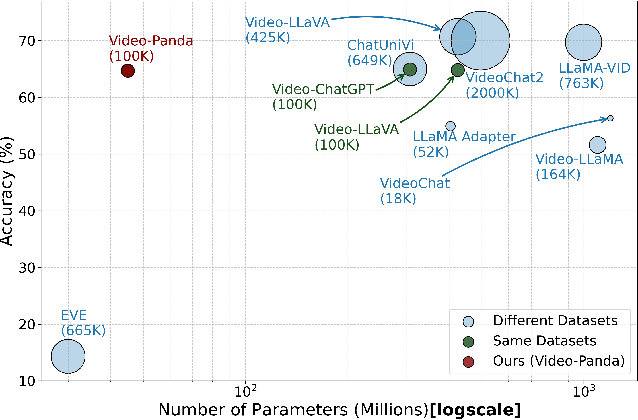
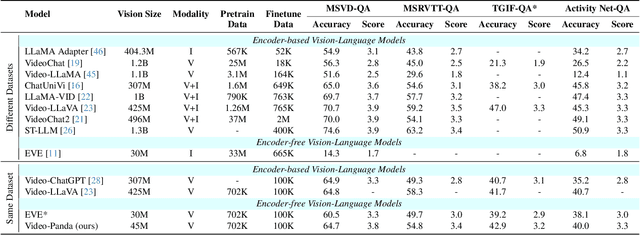
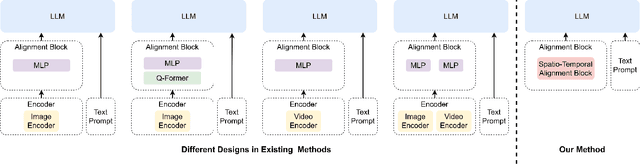
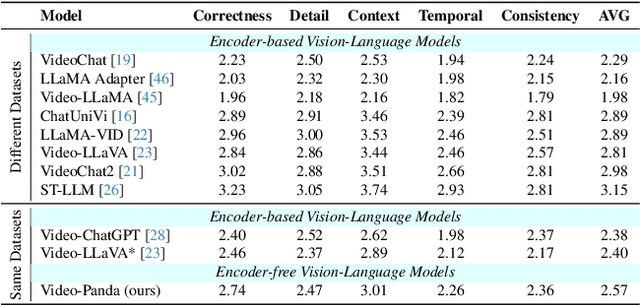
We present an efficient encoder-free approach for video-language understanding that achieves competitive performance while significantly reducing computational overhead. Current video-language models typically rely on heavyweight image encoders (300M-1.1B parameters) or video encoders (1B-1.4B parameters), creating a substantial computational burden when processing multi-frame videos. Our method introduces a novel Spatio-Temporal Alignment Block (STAB) that directly processes video inputs without requiring pre-trained encoders while using only 45M parameters for visual processing - at least a 6.5$\times$ reduction compared to traditional approaches. The STAB architecture combines Local Spatio-Temporal Encoding for fine-grained feature extraction, efficient spatial downsampling through learned attention and separate mechanisms for modeling frame-level and video-level relationships. Our model achieves comparable or superior performance to encoder-based approaches for open-ended video question answering on standard benchmarks. The fine-grained video question-answering evaluation demonstrates our model's effectiveness, outperforming the encoder-based approaches Video-ChatGPT and Video-LLaVA in key aspects like correctness and temporal understanding. Extensive ablation studies validate our architectural choices and demonstrate the effectiveness of our spatio-temporal modeling approach while achieving 3-4$\times$ faster processing speeds than previous methods. Code is available at \url{https://github.com/jh-yi/Video-Panda}.
Distillation-free Scaling of Large SSMs for Images and Videos
Sep 18, 2024



State-space models (SSMs), exemplified by S4, have introduced a novel context modeling method by integrating state-space techniques into deep learning. However, they struggle with global context modeling due to their data-independent matrices. The Mamba model addressed this with data-dependent variants via the S6 selective-scan algorithm, enhancing context modeling, especially for long sequences. However, Mamba-based architectures are difficult to scale with respect to the number of parameters, which is a major limitation for vision applications. This paper addresses the scalability issue of large SSMs for image classification and action recognition without requiring additional techniques like knowledge distillation. We analyze the distinct characteristics of Mamba-based and Attention-based models, proposing a Mamba-Attention interleaved architecture that enhances scalability, robustness, and performance. We demonstrate that the stable and efficient interleaved architecture resolves the scalability issue of Mamba-based architectures for images and videos and increases robustness to common artifacts like JPEG compression. Our thorough evaluation on the ImageNet-1K, Kinetics-400 and Something-Something-v2 benchmarks demonstrates that our approach improves the accuracy of state-of-the-art Mamba-based architectures by up to $+1.7$.
GroupMamba: Parameter-Efficient and Accurate Group Visual State Space Model
Jul 18, 2024



Recent advancements in state-space models (SSMs) have showcased effective performance in modeling long-range dependencies with subquadratic complexity. However, pure SSM-based models still face challenges related to stability and achieving optimal performance on computer vision tasks. Our paper addresses the challenges of scaling SSM-based models for computer vision, particularly the instability and inefficiency of large model sizes. To address this, we introduce a Modulated Group Mamba layer which divides the input channels into four groups and applies our proposed SSM-based efficient Visual Single Selective Scanning (VSSS) block independently to each group, with each VSSS block scanning in one of the four spatial directions. The Modulated Group Mamba layer also wraps the four VSSS blocks into a channel modulation operator to improve cross-channel communication. Furthermore, we introduce a distillation-based training objective to stabilize the training of large models, leading to consistent performance gains. Our comprehensive experiments demonstrate the merits of the proposed contributions, leading to superior performance over existing methods for image classification on ImageNet-1K, object detection, instance segmentation on MS-COCO, and semantic segmentation on ADE20K. Our tiny variant with 23M parameters achieves state-of-the-art performance with a classification top-1 accuracy of 83.3% on ImageNet-1K, while being 26% efficient in terms of parameters, compared to the best existing Mamba design of same model size. Our code and models are available at: https://github.com/Amshaker/GroupMamba.
Efficient Video Object Segmentation via Modulated Cross-Attention Memory
Mar 26, 2024



Recently, transformer-based approaches have shown promising results for semi-supervised video object segmentation. However, these approaches typically struggle on long videos due to increased GPU memory demands, as they frequently expand the memory bank every few frames. We propose a transformer-based approach, named MAVOS, that introduces an optimized and dynamic long-term modulated cross-attention (MCA) memory to model temporal smoothness without requiring frequent memory expansion. The proposed MCA effectively encodes both local and global features at various levels of granularity while efficiently maintaining consistent speed regardless of the video length. Extensive experiments on multiple benchmarks, LVOS, Long-Time Video, and DAVIS 2017, demonstrate the effectiveness of our proposed contributions leading to real-time inference and markedly reduced memory demands without any degradation in segmentation accuracy on long videos. Compared to the best existing transformer-based approach, our MAVOS increases the speed by 7.6x, while significantly reducing the GPU memory by 87% with comparable segmentation performance on short and long video datasets. Notably on the LVOS dataset, our MAVOS achieves a J&F score of 63.3% while operating at 37 frames per second (FPS) on a single V100 GPU. Our code and models will be publicly available at: https://github.com/Amshaker/MAVOS.
Video-GroundingDINO: Towards Open-Vocabulary Spatio-Temporal Video Grounding
Dec 31, 2023Video grounding aims to localize a spatio-temporal section in a video corresponding to an input text query. This paper addresses a critical limitation in current video grounding methodologies by introducing an Open-Vocabulary Spatio-Temporal Video Grounding task. Unlike prevalent closed-set approaches that struggle with open-vocabulary scenarios due to limited training data and predefined vocabularies, our model leverages pre-trained representations from foundational spatial grounding models. This empowers it to effectively bridge the semantic gap between natural language and diverse visual content, achieving strong performance in closed-set and open-vocabulary settings. Our contributions include a novel spatio-temporal video grounding model, surpassing state-of-the-art results in closed-set evaluations on multiple datasets and demonstrating superior performance in open-vocabulary scenarios. Notably, the proposed model outperforms state-of-the-art methods in closed-set settings on VidSTG (Declarative and Interrogative) and HC-STVG (V1 and V2) datasets. Furthermore, in open-vocabulary evaluations on HC-STVG V1 and YouCook-Interactions, our model surpasses the recent best-performing models by $4.26$ m_vIoU and $1.83\%$ accuracy, demonstrating its efficacy in handling diverse linguistic and visual concepts for improved video understanding. Our codes will be released at https://github.com/TalalWasim/Video-GroundingDINO.
Hardware Resilience Properties of Text-Guided Image Classifiers
Dec 05, 2023



This paper presents a novel method to enhance the reliability of image classification models during deployment in the face of transient hardware errors. By utilizing enriched text embeddings derived from GPT-3 with question prompts per class and CLIP pretrained text encoder, we investigate their impact as an initialization for the classification layer. Our approach achieves a remarkable $5.5\times$ average increase in hardware reliability (and up to $14\times$) across various architectures in the most critical layer, with minimal accuracy drop ($0.3\%$ on average) compared to baseline PyTorch models. Furthermore, our method seamlessly integrates with any image classification backbone, showcases results across various network architectures, decreases parameter and FLOPs overhead, and follows a consistent training recipe. This research offers a practical and efficient solution to bolster the robustness of image classification models against hardware failures, with potential implications for future studies in this domain. Our code and models are released at https://github.com/TalalWasim/TextGuidedResilience.
Video-FocalNets: Spatio-Temporal Focal Modulation for Video Action Recognition
Jul 16, 2023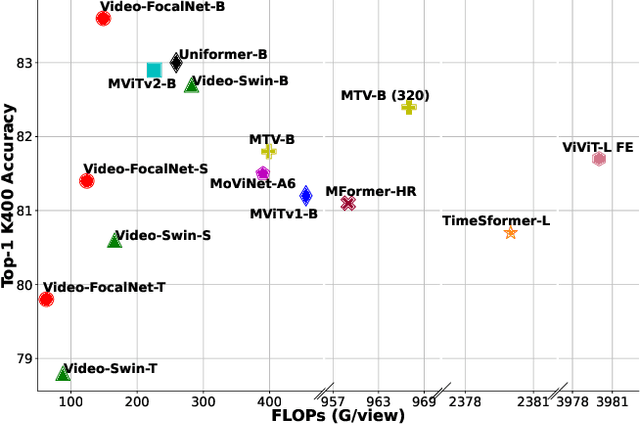
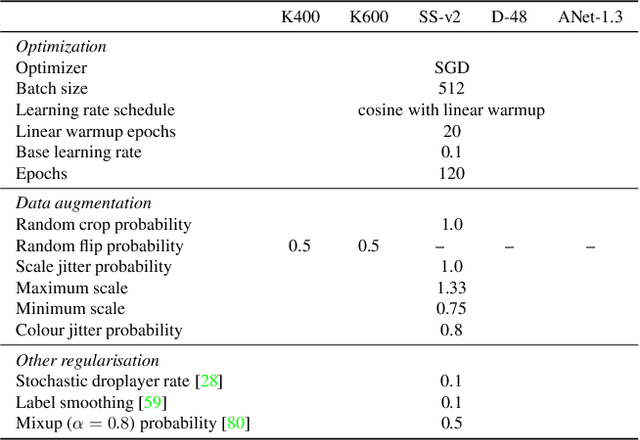
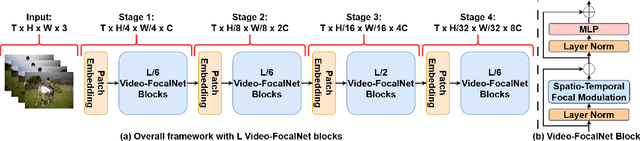
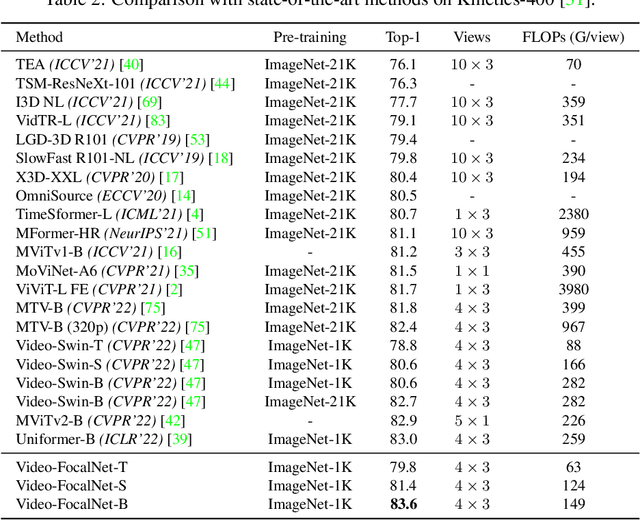
Recent video recognition models utilize Transformer models for long-range spatio-temporal context modeling. Video transformer designs are based on self-attention that can model global context at a high computational cost. In comparison, convolutional designs for videos offer an efficient alternative but lack long-range dependency modeling. Towards achieving the best of both designs, this work proposes Video-FocalNet, an effective and efficient architecture for video recognition that models both local and global contexts. Video-FocalNet is based on a spatio-temporal focal modulation architecture that reverses the interaction and aggregation steps of self-attention for better efficiency. Further, the aggregation step and the interaction step are both implemented using efficient convolution and element-wise multiplication operations that are computationally less expensive than their self-attention counterparts on video representations. We extensively explore the design space of focal modulation-based spatio-temporal context modeling and demonstrate our parallel spatial and temporal encoding design to be the optimal choice. Video-FocalNets perform favorably well against the state-of-the-art transformer-based models for video recognition on three large-scale datasets (Kinetics-400, Kinetics-600, and SS-v2) at a lower computational cost. Our code/models are released at https://github.com/TalalWasim/Video-FocalNets.