 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBRepCLIP: Contrastive Multimodal Pretraining on BRep Primitives for CAD Understanding
Jun 03, 2026Learning representations of CAD models is a largely open problem. While 3D representation learning has flourished around point clouds and meshes, the native format of CAD - boundary representations BReps, which encodes exact parametric surfaces, curves, and their topology, has received little attention as a representation learning substrate. We introduce BRepCLIP, the first framework to align BRep geometry with language and image embeddings through contrastive pretraining. We model each CAD object as a sequence of face and edge tokens with separate discrete vocabularies for surface and curve geometry, augmented with spatial and semantic descriptors that capture surface types (e.g., cylindrical, torus, NURBS) and curve primitives (e.g., line, arc, B-spline). A transformer encoder aggregates these tokens into a global BRep embedding, aligned with CLIP's text and image encoders via a joint contrastive objective. BRepCLIP generates more discriminative and semantically grounded embeddings than existing point-based alternatives, improving Top-1 retrieval over OpenShape by 40.4%, 22.0%, and 23.9% on ABC, CADParser, and Automate, respectively, and improving zero-shot classification on FabWave by 15% in Top-1 score. We further demonstrate its utility as a CAD-aware similarity metric for evaluating text and image-conditioned CAD generation, establishing the importance of structure-aware pretraining for multimodal CAD understanding. Project page is available at https://muhammadusama100.github.io/BrepClip2026/
Convergence Without Understanding: When Language Models Agree on Representations but Disagree on Reasoning
May 22, 2026Large language models trained under diverse objectives and architectures have been shown to develop increasingly similar internal representations, an observation formalized as the Platonic Representation Hypothesis. Whether this representational convergence extends to the reasoning processes that operate over shared representations remains untested. We evaluate representational similarity across 16 language models from 8 families (1.5B to 72B parameters) on 800 reasoning problems spanning mathematics, science, commonsense, and truthfulness, stratifying by problem difficulty, computational stage, and causal relevance. Our analysis reveals three dissociations: a difficulty inversion, where models converge more on problems they collectively fail (Centered Kernel Alignment [CKA] = 0.897) than on those they solve (CKA = 0.830); a generation gap, where pre-decision representations align (CKA = 0.875) while post-decision representations diverge (CKA = 0.274); and epiphenomenal correctness, where shared information is decodable across models (66% transfer accuracy) but exerts minimal causal influence on predictions (1.5% to 5.5% flip rate across ablation protocols). These results indicate that representational convergence in language models reflects shared input processing constraints rather than shared reasoning strategies, with direct implications for ensemble design, interpretability transfer, and evaluations of model similarity. Code is available at https://github.com/Usama1002/convergence-without-understanding.
Physics-in-the-Loop: A Hybrid Agentic Architecture for Validated CAD Engineering Design
May 19, 2026Large Language Models (LLMs) can generate Computer-Aided Design (CAD), yet lack physical comprehension required for reliable engineering design. Instead of attempting to implicitly learn physical laws from data, we propose a Hybrid Agentic-Physical Architecture that embeds validated knowledge-based engineering tools directly into the decision making loop of autonomous AI agents. In this framework, engineering design is formulated as a closed-loop, sequential decision making process guided by explicit physical verification. Based on a load case, dedicated agents iteratively plan, generate, evaluate, and revise engineering designs using knowledge-based tools as a feedback signal. We introduce a benchmark dataset and metrics for assessing functional validity in generative CAD. Our system generates more complex and physically verified designs, with a 4.2 increase in structural complexity and improving compile rate by 3.5% compared to similar agentic methods. The codebase, prompts and dataset will be made publicly available to support reproducibility and future research.
Design of a six wheel suspension and a three-axis linear actuation mechanism for a laser weeding robot
Dec 11, 2025Mobile robots are increasingly utilized in agriculture to automate labor-intensive tasks such as weeding, sowing, harvesting and soil analysis. Recently, agricultural robots have been developed to detect and remove weeds using mechanical tools or precise herbicide sprays. Mechanical weeding is inefficient over large fields, and herbicides harm the soil ecosystem. Laser weeding with mobile robots has emerged as a sustainable alternative in precision farming. In this paper, we present an autonomous weeding robot that uses controlled exposure to a low energy laser beam for weed removal. The proposed robot is six-wheeled with a novel double four-bar suspension for higher stability. The laser is guided towards the detected weeds by a three-dimensional linear actuation mechanism. Field tests have demonstrated the robot's capability to navigate agricultural terrains effectively by overcoming obstacles up to 15 cm in height. At an optimal speed of 42.5 cm/s, the robot achieves a weed detection rate of 86.2\% and operating time of 87 seconds per meter. The laser actuation mechanism maintains a minimal mean positional error of 1.54 mm, combined with a high hit rate of 97\%, ensuring effective and accurate weed removal. This combination of speed, accuracy, and efficiency highlights the robot's potential for significantly enhancing precision farming practices.
NURBGen: High-Fidelity Text-to-CAD Generation through LLM-Driven NURBS Modeling
Nov 15, 2025



Generating editable 3D CAD models from natural language remains challenging, as existing text-to-CAD systems either produce meshes or rely on scarce design-history data. We present NURBGen, the first framework to generate high-fidelity 3D CAD models directly from text using Non-Uniform Rational B-Splines (NURBS). To achieve this, we fine-tune a large language model (LLM) to translate free-form texts into JSON representations containing NURBS surface parameters (\textit{i.e}, control points, knot vectors, degrees, and rational weights) which can be directly converted into BRep format using Python. We further propose a hybrid representation that combines untrimmed NURBS with analytic primitives to handle trimmed surfaces and degenerate regions more robustly, while reducing token complexity. Additionally, we introduce partABC, a curated subset of the ABC dataset consisting of individual CAD components, annotated with detailed captions using an automated annotation pipeline. NURBGen demonstrates strong performance on diverse prompts, surpassing prior methods in geometric fidelity and dimensional accuracy, as confirmed by expert evaluations. Code and dataset will be released publicly.
Deep Reinforcement Learning-Based DRAM Equalizer Parameter Optimization Using Latent Representations
Jul 03, 2025



Equalizer parameter optimization for signal integrity in high-speed Dynamic Random Access Memory systems is crucial but often computationally demanding or model-reliant. This paper introduces a data-driven framework employing learned latent signal representations for efficient signal integrity evaluation, coupled with a model-free Advantage Actor-Critic reinforcement learning agent for parameter optimization. The latent representation captures vital signal integrity features, offering a fast alternative to direct eye diagram analysis during optimization, while the reinforcement learning agent derives optimal equalizer settings without explicit system models. Applied to industry-standard Dynamic Random Access Memory waveforms, the method achieved significant eye-opening window area improvements: 42.7\% for cascaded Continuous-Time Linear Equalizer and Decision Feedback Equalizer structures, and 36.8\% for Decision Feedback Equalizer-only configurations. These results demonstrate superior performance, computational efficiency, and robust generalization across diverse Dynamic Random Access Memory units compared to existing techniques. Core contributions include an efficient latent signal integrity metric for optimization, a robust model-free reinforcement learning strategy, and validated superior performance for complex equalizer architectures.
Analysing the Robustness of Vision-Language-Models to Common Corruptions
Apr 21, 2025
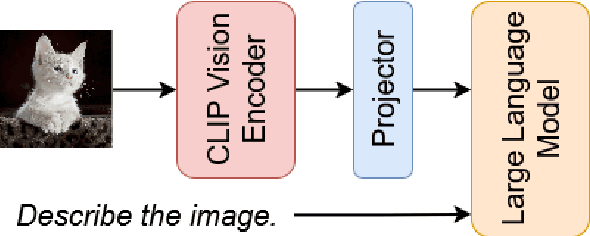
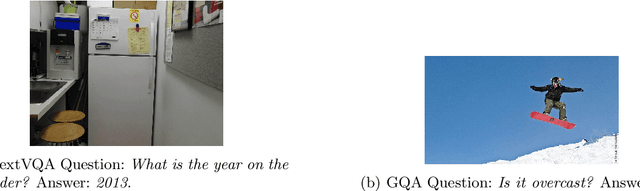
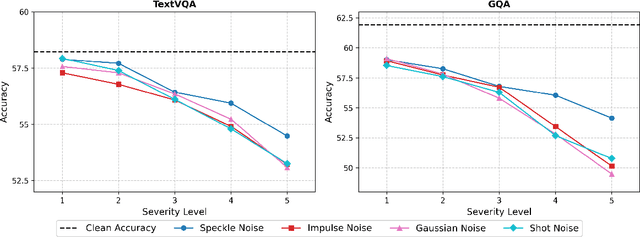
Vision-language models (VLMs) have demonstrated impressive capabilities in understanding and reasoning about visual and textual content. However, their robustness to common image corruptions remains under-explored. In this work, we present the first comprehensive analysis of VLM robustness across 19 corruption types from the ImageNet-C benchmark, spanning four categories: noise, blur, weather, and digital distortions. We introduce two new benchmarks, TextVQA-C and GQA-C, to systematically evaluate how corruptions affect scene text understanding and object-based reasoning, respectively. Our analysis reveals that transformer-based VLMs exhibit distinct vulnerability patterns across tasks: text recognition deteriorates most severely under blur and snow corruptions, while object reasoning shows higher sensitivity to corruptions such as frost and impulse noise. We connect these observations to the frequency-domain characteristics of different corruptions, revealing how transformers' inherent bias toward low-frequency processing explains their differential robustness patterns. Our findings provide valuable insights for developing more corruption-robust vision-language models for real-world applications.
Estimating City-wide operating mode Distribution of Light-Duty Vehicles: A Neural Network-based Approach
Mar 28, 2025



Driving cycles are a set of driving conditions and are crucial for the existing emission estimation model to evaluate vehicle performance, fuel efficiency, and emissions, by matching them with average speed to calculate the operating modes, such as braking, idling, and cruising. While existing emission estimation models, such as the Motor Vehicle Emission Simulator (MOVES), are powerful tools, their reliance on predefined driving cycles can be limiting, as these cycles often do not accurately represent regional driving conditions, making the models less effective for city-wide analyses. To solve this problem, this paper proposes a modular neural network (NN)-based framework to estimate operating mode distributions bypassing the driving cycle development phase, utilizing macroscopic variables such as speed, flow, and link infrastructure attributes. The proposed method is validated using a well-calibrated microsimulation model of Brookline MA, the United States. The results indicate that the proposed framework outperforms the operating mode distribution calculated by MOVES based on default driving cycles, providing a closer match to the actual operating mode distribution derived from trajectory data. Specifically, the proposed model achieves an average RMSE of 0.04 in predicting operating mode distribution, compared to 0.08 for MOVES. The average error in emission estimation across pollutants is 8.57% for the proposed method, lower than the 32.86% error for MOVES. In particular, for the estimation of CO2, the proposed method has an error of just 4%, compared to 35% for MOVES. The proposed model can be utilized for real-time emissions monitoring by providing rapid and accurate emissions estimates with easily accessible inputs.
EnergyFormer: Energy Attention with Fourier Embedding for Hyperspectral Image Classification
Mar 11, 2025Hyperspectral imaging (HSI) provides rich spectral-spatial information across hundreds of contiguous bands, enabling precise material discrimination in applications such as environmental monitoring, agriculture, and urban analysis. However, the high dimensionality and spectral variability of HSI data pose significant challenges for feature extraction and classification. This paper presents EnergyFormer, a transformer-based framework designed to address these challenges through three key innovations: (1) Multi-Head Energy Attention (MHEA), which optimizes an energy function to selectively enhance critical spectral-spatial features, improving feature discrimination; (2) Fourier Position Embedding (FoPE), which adaptively encodes spectral and spatial dependencies to reinforce long-range interactions; and (3) Enhanced Convolutional Block Attention Module (ECBAM), which selectively amplifies informative wavelength bands and spatial structures, enhancing representation learning. Extensive experiments on the WHU-Hi-HanChuan, Salinas, and Pavia University datasets demonstrate that EnergyFormer achieves exceptional overall accuracies of 99.28\%, 98.63\%, and 98.72\%, respectively, outperforming state-of-the-art CNN, transformer, and Mamba-based models. The source code will be made available at https://github.com/mahmad000.
Hybrid State-Space and GRU-based Graph Tokenization Mamba for Hyperspectral Image Classification
Feb 10, 2025



Hyperspectral image (HSI) classification plays a pivotal role in domains such as environmental monitoring, agriculture, and urban planning. However, it faces significant challenges due to the high-dimensional nature of the data and the complex spectral-spatial relationships inherent in HSI. Traditional methods, including conventional machine learning and convolutional neural networks (CNNs), often struggle to effectively capture these intricate spectral-spatial features and global contextual information. Transformer-based models, while powerful in capturing long-range dependencies, often demand substantial computational resources, posing challenges in scenarios where labeled datasets are limited, as is commonly seen in HSI applications. To overcome these challenges, this work proposes GraphMamba, a hybrid model that combines spectral-spatial token generation, graph-based token prioritization, and cross-attention mechanisms. The model introduces a novel hybridization of state-space modeling and Gated Recurrent Units (GRU), capturing both linear and nonlinear spatial-spectral dynamics. GraphMamba enhances the ability to model complex spatial-spectral relationships while maintaining scalability and computational efficiency across diverse HSI datasets. Through comprehensive experiments, we demonstrate that GraphMamba outperforms existing state-of-the-art models, offering a scalable and robust solution for complex HSI classification tasks.