 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysics-Informed Geometric Operators to Support Surrogate, Dimension Reduction and Generative Models for Engineering Design
Jul 10, 2024In this work, we propose a set of physics-informed geometric operators (GOs) to enrich the geometric data provided for training surrogate/discriminative models, dimension reduction, and generative models, typically employed for performance prediction, dimension reduction, and creating data-driven parameterisations, respectively. However, as both the input and output streams of these models consist of low-level shape representations, they often fail to capture shape characteristics essential for performance analyses. Therefore, the proposed GOs exploit the differential and integral properties of shapes--accessed through Fourier descriptors, curvature integrals, geometric moments, and their invariants--to infuse high-level intrinsic geometric information and physics into the feature vector used for training, even when employing simple model architectures or low-level parametric descriptions. We showed that for surrogate modelling, along with the inclusion of the notion of physics, GOs enact regularisation to reduce over-fitting and enhance generalisation to new, unseen designs. Furthermore, through extensive experimentation, we demonstrate that for dimension reduction and generative models, incorporating the proposed GOs enriches the training data with compact global and local geometric features. This significantly enhances the quality of the resulting latent space, thereby facilitating the generation of valid and diverse designs. Lastly, we also show that GOs can enable learning parametric sensitivities to a great extent. Consequently, these enhancements accelerate the convergence rate of shape optimisers towards optimal solutions.
Controllable One-Shot Face Video Synthesis With Semantic Aware Prior
Apr 27, 2023The one-shot talking-head synthesis task aims to animate a source image to another pose and expression, which is dictated by a driving frame. Recent methods rely on warping the appearance feature extracted from the source, by using motion fields estimated from the sparse keypoints, that are learned in an unsupervised manner. Due to their lightweight formulation, they are suitable for video conferencing with reduced bandwidth. However, based on our study, current methods suffer from two major limitations: 1) unsatisfactory generation quality in the case of large head poses and the existence of observable pose misalignment between the source and the first frame in driving videos. 2) fail to capture fine yet critical face motion details due to the lack of semantic understanding and appropriate face geometry regularization. To address these shortcomings, we propose a novel method that leverages the rich face prior information, the proposed model can generate face videos with improved semantic consistency (improve baseline by $7\%$ in average keypoint distance) and expression-preserving (outperform baseline by $15 \%$ in average emotion embedding distance) under equivalent bandwidth. Additionally, incorporating such prior information provides us with a convenient interface to achieve highly controllable generation in terms of both pose and expression.
T-METASET: Task-Aware Generation of Metamaterial Datasets by Diversity-Based Active Learning
Feb 21, 2022

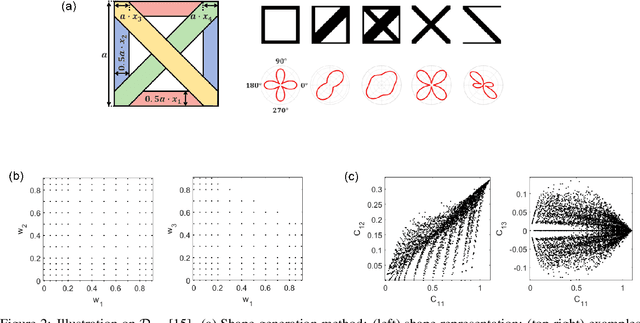
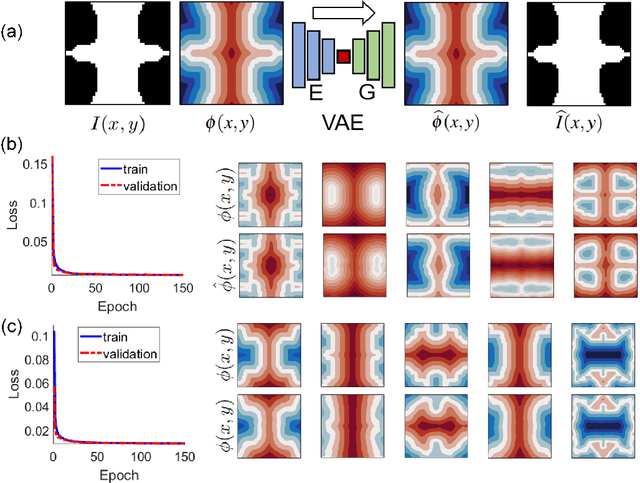
Inspired by the recent success of deep learning in diverse domains, data-driven metamaterials design has emerged as a compelling design paradigm to unlock the potential of multiscale architecture. However, existing model-centric approaches lack principled methodologies dedicated to high-quality data generation. Resorting to space-filling design in shape descriptor space, existing metamaterial datasets suffer from property distributions that are either highly imbalanced or at odds with design tasks of interest. To this end, we propose t-METASET: an intelligent data acquisition framework for task-aware dataset generation. We seek a solution to a commonplace yet frequently overlooked scenario at early design stages: when a massive ($~\sim O(10^4)$) shape library has been prepared with no properties evaluated. The key idea is to exploit a data-driven shape descriptor learned from generative models, fit a sparse regressor as the start-up agent, and leverage diversity-related metrics to drive data acquisition to areas that help designers fulfill design goals. We validate the proposed framework in three hypothetical deployment scenarios, which encompass general use, task-aware use, and tailorable use. Two large-scale shape-only mechanical metamaterial datasets are used as test datasets. The results demonstrate that t-METASET can incrementally grow task-aware datasets. Applicable to general design representations, t-METASET can boost future advancements of not only metamaterials but data-driven design in other domains.
Deep Generative Models for Geometric Design Under Uncertainty
Dec 15, 2021
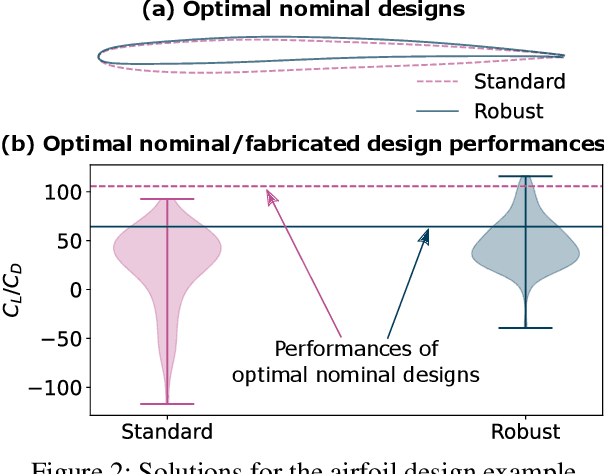
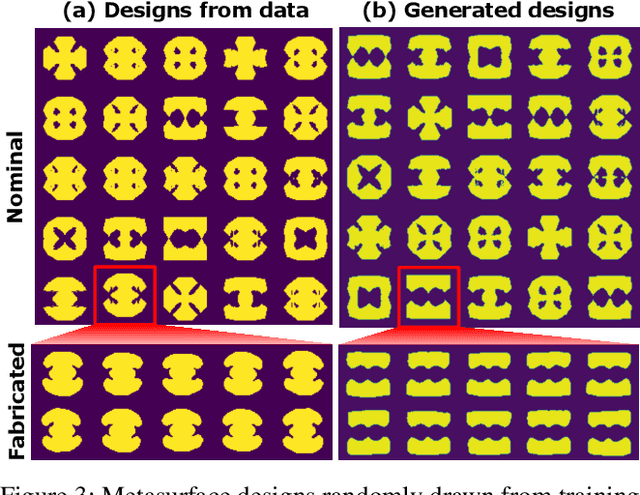
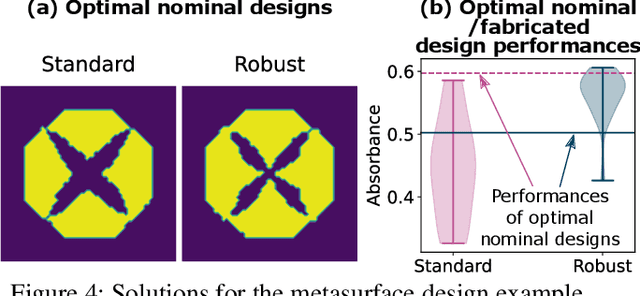
Deep generative models have demonstrated effectiveness in learning compact and expressive design representations that significantly improve geometric design optimization. However, these models do not consider the uncertainty introduced by manufacturing or fabrication. Past work that quantifies such uncertainty often makes simplified assumptions on geometric variations, while the "real-world" uncertainty and its impact on design performance are difficult to quantify due to the high dimensionality. To address this issue, we propose a Generative Adversarial Network-based Design under Uncertainty Framework (GAN-DUF), which contains a deep generative model that simultaneously learns a compact representation of nominal (ideal) designs and the conditional distribution of fabricated designs given any nominal design. We demonstrated the framework on two real-world engineering design examples and showed its capability of finding the solution that possesses better performances after fabrication.