 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAOAM: Unified Object and Material Selection with Vision-Language Models
Jun 02, 2026Selection is a core operation in interactive image editing. To be practical, a user should be able to specify and disambiguate the desired selection region through either text or click-based interactions, and the system should support selecting not only objects but also other criteria, such as materials. Material-based selection is valuable for tasks like re-texturing surfaces or editing instances of a specific material. However, existing vision-language-model (VLM) based selection methods are object-centric and typically support a single interaction modality, limiting their applicability. In this work, we thus present Mask Any Object And Material (MAOAM), a unified selection framework that enables precise object and material-level selection across both text- and click-based interactions. MAOAM leverages a VLM with a segmentation head to produce pixel-accurate masks from user prompts: the VLM interprets the user's selection intent (object or material-level) and encodes visual entities, attributes, and spatial relations, while the segmentation head decodes the output token into a mask. A key challenge is the lack of material selection datasets with text annotations. We propose a scalable data generation pipeline: we collect real and synthetic images with material masks, and leverage VLMs to generate material descriptions with rich visual-semantics. We train MAOAM with a multi-task objective over click and text-based selection, along with an auxiliary VQA task derived from the material descriptions to facilitate deeper material understanding. Despite being trained with uni-modal prompts, our model exhibits an emergent improvement in selection when combining text and clicks at inference, enabling flexible image editing workflows. Experiments demonstrate accurate and coherent selections across diverse objects, materials, and interaction scenarios, highlighting robustness in practice.
Inline Critic Steers Image Editing
May 12, 2026Instruction-based image editing exhibits heterogeneous difficulty not only across cases but also across regions of an image, motivating refinement approaches that allocate correction to where the model struggles. Existing refinement signals arrive late, after a fully generated image or a completed denoising step. We ask whether such a signal can act within an ongoing forward pass. To investigate this, we probe a frozen image-editing model and find that although generation capability emerges only in the last few layers, the error pattern is already set in early layers (rank correlation \r{ho} = 0.83 with the final-layer error map). Based on this, we introduce Inline Critic, a learnable token that critiques a frozen model's predictions at its intermediate layers and steers its hidden states to refine generation during the forward pass. A three-stage recipe is proposed to stabilize the training from learning how to critique to steering generation. As a result, we achieve state of the art on GEdit-Bench (7.89), a +9.4 gain on RISEBench over the same backbone, and the strongest open-source result on KRIS-Bench (81.92, surpassing GPT-4o). We further provide analyses showing that the critic genuinely shapes the model's attention and prediction updates at subsequent layers.
SNCE: Geometry-Aware Supervision for Scalable Discrete Image Generation
Mar 16, 2026Recent advancements in discrete image generation showed that scaling the VQ codebook size significantly improves reconstruction fidelity. However, training generative models with a large VQ codebook remains challenging, typically requiring larger model size and a longer training schedule. In this work, we propose Stochastic Neighbor Cross Entropy Minimization (SNCE), a novel training objective designed to address the optimization challenges of large-codebook discrete image generators. Instead of supervising the model with a hard one-hot target, SNCE constructs a soft categorical distribution over a set of neighboring tokens. The probability assigned to each token is proportional to the proximity between its code embedding and the ground-truth image embedding, encouraging the model to capture semantically meaningful geometric structure in the quantized embedding space. We conduct extensive experiments across class-conditional ImageNet-256 generation, large-scale text-to-image synthesis, and image editing tasks. Results show that SNCE significantly improves convergence speed and overall generation quality compared to standard cross-entropy objectives.
LaViDa-R1: Advancing Reasoning for Unified Multimodal Diffusion Language Models
Feb 15, 2026Diffusion language models (dLLMs) recently emerged as a promising alternative to auto-regressive LLMs. The latest works further extended it to multimodal understanding and generation tasks. In this work, we propose LaViDa-R1, a multimodal, general-purpose reasoning dLLM. Unlike existing works that build reasoning dLLMs through task-specific reinforcement learning, LaViDa-R1 incorporates diverse multimodal understanding and generation tasks in a unified manner. In particular, LaViDa-R1 is built with a novel unified post-training framework that seamlessly integrates supervised finetuning (SFT) and multi-task reinforcement learning (RL). It employs several novel training techniques, including answer-forcing, tree search, and complementary likelihood estimation, to enhance effectiveness and scalability. Extensive experiments demonstrate LaViDa-R1's strong performance on a wide range of multimodal tasks, including visual math reasoning, reason-intensive grounding, and image editing.
Sparse-LaViDa: Sparse Multimodal Discrete Diffusion Language Models
Dec 16, 2025Masked Discrete Diffusion Models (MDMs) have achieved strong performance across a wide range of multimodal tasks, including image understanding, generation, and editing. However, their inference speed remains suboptimal due to the need to repeatedly process redundant masked tokens at every sampling step. In this work, we propose Sparse-LaViDa, a novel modeling framework that dynamically truncates unnecessary masked tokens at each inference step to accelerate MDM sampling. To preserve generation quality, we introduce specialized register tokens that serve as compact representations for the truncated tokens. Furthermore, to ensure consistency between training and inference, we design a specialized attention mask that faithfully matches the truncated sampling procedure during training. Built upon the state-of-the-art unified MDM LaViDa-O, Sparse-LaViDa achieves up to a 2x speedup across diverse tasks including text-to-image generation, image editing, and mathematical reasoning, while maintaining generation quality.
VGent: Visual Grounding via Modular Design for Disentangling Reasoning and Prediction
Dec 11, 2025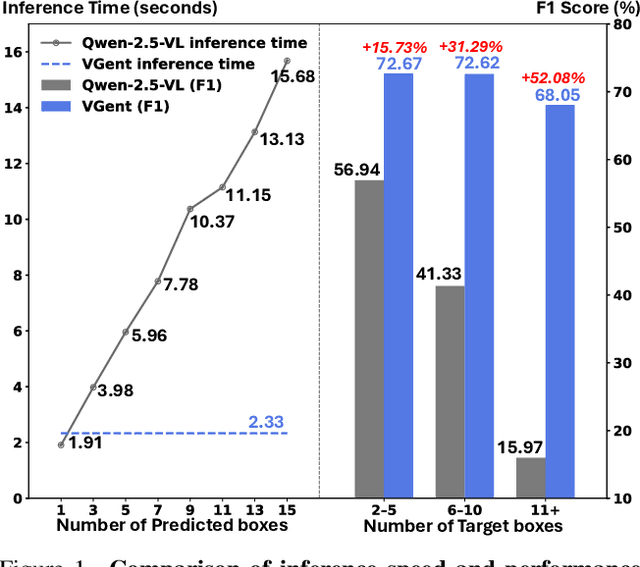
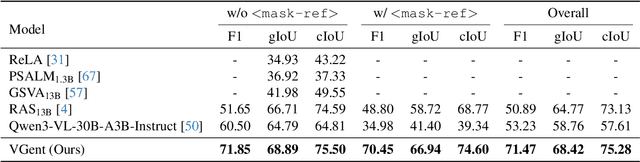
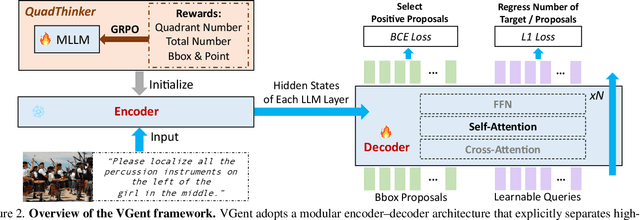
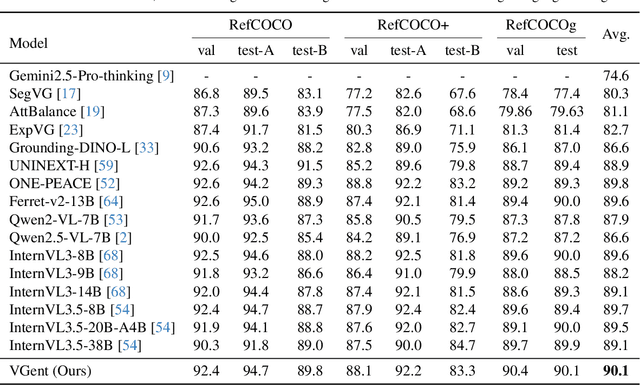
Current visual grounding models are either based on a Multimodal Large Language Model (MLLM) that performs auto-regressive decoding, which is slow and risks hallucinations, or on re-aligning an LLM with vision features to learn new special or object tokens for grounding, which may undermine the LLM's pretrained reasoning ability. In contrast, we propose VGent, a modular encoder-decoder architecture that explicitly disentangles high-level reasoning and low-level bounding box prediction. Specifically, a frozen MLLM serves as the encoder to provide untouched powerful reasoning capabilities, while a decoder takes high-quality boxes proposed by detectors as queries and selects target box(es) via cross-attending on encoder's hidden states. This design fully leverages advances in both object detection and MLLM, avoids the pitfalls of auto-regressive decoding, and enables fast inference. Moreover, it supports modular upgrades of both the encoder and decoder to benefit the whole system: we introduce (i) QuadThinker, an RL-based training paradigm for enhancing multi-target reasoning ability of the encoder; (ii) mask-aware label for resolving detection-segmentation ambiguity; and (iii) global target recognition to improve the recognition of all the targets which benefits the selection among augmented proposals. Experiments on multi-target visual grounding benchmarks show that VGent achieves a new state-of-the-art with +20.6% F1 improvement over prior methods, and further boosts gIoU by +8.2% and cIoU by +5.8% under visual reference challenges, while maintaining constant, fast inference latency.
Refer to Anything with Vision-Language Prompts
Jun 05, 2025Recent image segmentation models have advanced to segment images into high-quality masks for visual entities, and yet they cannot provide comprehensive semantic understanding for complex queries based on both language and vision. This limitation reduces their effectiveness in applications that require user-friendly interactions driven by vision-language prompts. To bridge this gap, we introduce a novel task of omnimodal referring expression segmentation (ORES). In this task, a model produces a group of masks based on arbitrary prompts specified by text only or text plus reference visual entities. To address this new challenge, we propose a novel framework to "Refer to Any Segmentation Mask Group" (RAS), which augments segmentation models with complex multimodal interactions and comprehension via a mask-centric large multimodal model. For training and benchmarking ORES models, we create datasets MaskGroups-2M and MaskGroups-HQ to include diverse mask groups specified by text and reference entities. Through extensive evaluation, we demonstrate superior performance of RAS on our new ORES task, as well as classic referring expression segmentation (RES) and generalized referring expression segmentation (GRES) tasks. Project page: https://Ref2Any.github.io.
Multi-modal AI for comprehensive breast cancer prognostication
Oct 28, 2024

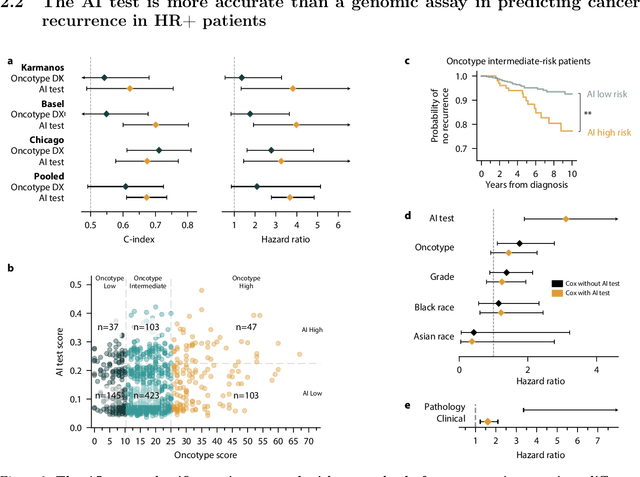

Treatment selection in breast cancer is guided by molecular subtypes and clinical characteristics. Recurrence risk assessment plays a crucial role in personalizing treatment. Current methods, including genomic assays, have limited accuracy and clinical utility, leading to suboptimal decisions for many patients. We developed a test for breast cancer patient stratification based on digital pathology and clinical characteristics using novel AI methods. Specifically, we utilized a vision transformer-based pan-cancer foundation model trained with self-supervised learning to extract features from digitized H&E-stained slides. These features were integrated with clinical data to form a multi-modal AI test predicting cancer recurrence and death. The test was developed and evaluated using data from a total of 8,161 breast cancer patients across 15 cohorts originating from seven countries. Of these, 3,502 patients from five cohorts were used exclusively for evaluation, while the remaining patients were used for training. Our test accurately predicted our primary endpoint, disease-free interval, in the five external cohorts (C-index: 0.71 [0.68-0.75], HR: 3.63 [3.02-4.37, p<0.01]). In a direct comparison (N=858), the AI test was more accurate than Oncotype DX, the standard-of-care 21-gene assay, with a C-index of 0.67 [0.61-0.74] versus 0.61 [0.49-0.73], respectively. Additionally, the AI test added independent information to Oncotype DX in a multivariate analysis (HR: 3.11 [1.91-5.09, p<0.01)]). The test demonstrated robust accuracy across all major breast cancer subtypes, including TNBC (C-index: 0.71 [0.62-0.81], HR: 3.81 [2.35-6.17, p=0.02]), where no diagnostic tools are currently recommended by clinical guidelines. These results suggest that our AI test can improve accuracy, extend applicability to a wider range of patients, and enhance access to treatment selection tools.
AutoGLM: Autonomous Foundation Agents for GUIs
Oct 28, 2024



We present AutoGLM, a new series in the ChatGLM family, designed to serve as foundation agents for autonomous control of digital devices through Graphical User Interfaces (GUIs). While foundation models excel at acquiring human knowledge, they often struggle with decision-making in dynamic real-world environments, limiting their progress toward artificial general intelligence. This limitation underscores the importance of developing foundation agents capable of learning through autonomous environmental interactions by reinforcing existing models. Focusing on Web Browser and Phone as representative GUI scenarios, we have developed AutoGLM as a practical foundation agent system for real-world GUI interactions. Our approach integrates a comprehensive suite of techniques and infrastructures to create deployable agent systems suitable for user delivery. Through this development, we have derived two key insights: First, the design of an appropriate "intermediate interface" for GUI control is crucial, enabling the separation of planning and grounding behaviors, which require distinct optimization for flexibility and accuracy respectively. Second, we have developed a novel progressive training framework that enables self-evolving online curriculum reinforcement learning for AutoGLM. Our evaluations demonstrate AutoGLM's effectiveness across multiple domains. For web browsing, AutoGLM achieves a 55.2% success rate on VAB-WebArena-Lite (improving to 59.1% with a second attempt) and 96.2% on OpenTable evaluation tasks. In Android device control, AutoGLM attains a 36.2% success rate on AndroidLab (VAB-Mobile) and 89.7% on common tasks in popular Chinese APPs.
Quantifying Impairment and Disease Severity Using AI Models Trained on Healthy Subjects
Nov 21, 2023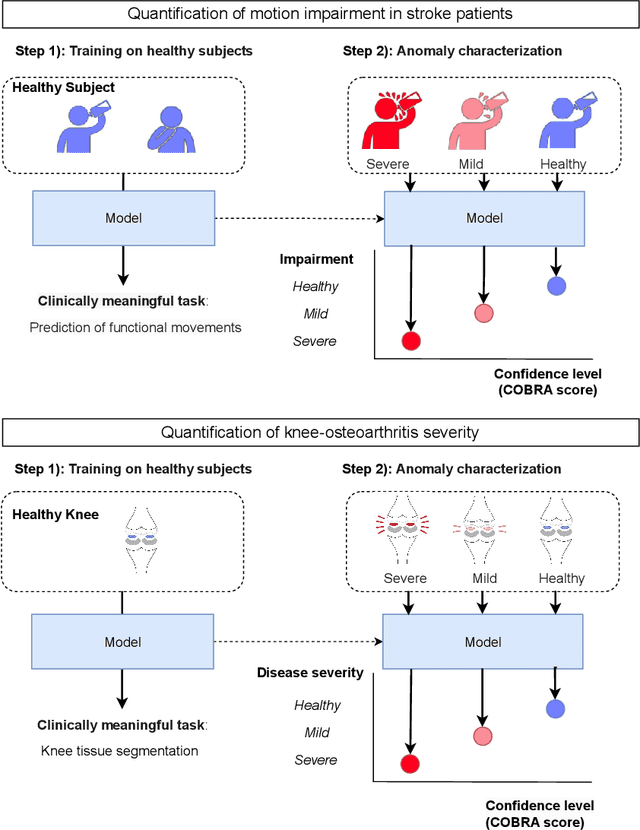
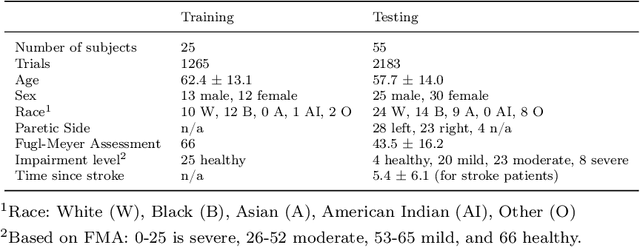
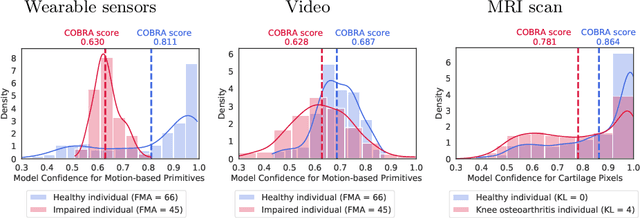
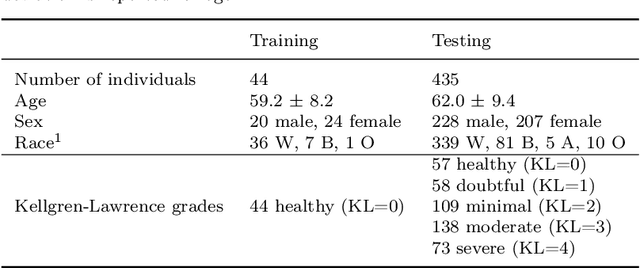
Automatic assessment of impairment and disease severity is a key challenge in data-driven medicine. We propose a novel framework to address this challenge, which leverages AI models trained exclusively on healthy individuals. The COnfidence-Based chaRacterization of Anomalies (COBRA) score exploits the decrease in confidence of these models when presented with impaired or diseased patients to quantify their deviation from the healthy population. We applied the COBRA score to address a key limitation of current clinical evaluation of upper-body impairment in stroke patients. The gold-standard Fugl-Meyer Assessment (FMA) requires in-person administration by a trained assessor for 30-45 minutes, which restricts monitoring frequency and precludes physicians from adapting rehabilitation protocols to the progress of each patient. The COBRA score, computed automatically in under one minute, is shown to be strongly correlated with the FMA on an independent test cohort for two different data modalities: wearable sensors ($\rho = 0.845$, 95% CI [0.743,0.908]) and video ($\rho = 0.746$, 95% C.I [0.594, 0.847]). To demonstrate the generalizability of the approach to other conditions, the COBRA score was also applied to quantify severity of knee osteoarthritis from magnetic-resonance imaging scans, again achieving significant correlation with an independent clinical assessment ($\rho = 0.644$, 95% C.I [0.585,0.696]).