 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWebRL: Training LLM Web Agents via Self-Evolving Online Curriculum Reinforcement Learning
Nov 04, 2024



Large language models (LLMs) have shown remarkable potential as autonomous agents, particularly in web-based tasks. However, existing LLM web agents heavily rely on expensive proprietary LLM APIs, while open LLMs lack the necessary decision-making capabilities. This paper introduces WebRL, a self-evolving online curriculum reinforcement learning framework designed to train high-performance web agents using open LLMs. WebRL addresses three key challenges in building LLM web agents, including the scarcity of training tasks, sparse feedback signals, and policy distribution drift in online learning. Specifically, WebRL incorporates 1) a self-evolving curriculum that generates new tasks from unsuccessful attempts, 2) a robust outcome-supervised reward model (ORM), and 3) adaptive reinforcement learning strategies to ensure consistent improvements. We apply WebRL to transform open Llama-3.1 and GLM-4 models into proficient web agents. On WebArena-Lite, WebRL improves the success rate of Llama-3.1-8B from 4.8% to 42.4%, and from 6.1% to 43% for GLM-4-9B. These open models significantly surpass the performance of GPT-4-Turbo (17.6%) and GPT-4o (13.9%) and outperform previous state-of-the-art web agents trained on open LLMs (AutoWebGLM, 18.2%). Our findings demonstrate WebRL's effectiveness in bridging the gap between open and proprietary LLM-based web agents, paving the way for more accessible and powerful autonomous web interaction systems.
AutoGLM: Autonomous Foundation Agents for GUIs
Oct 28, 2024



We present AutoGLM, a new series in the ChatGLM family, designed to serve as foundation agents for autonomous control of digital devices through Graphical User Interfaces (GUIs). While foundation models excel at acquiring human knowledge, they often struggle with decision-making in dynamic real-world environments, limiting their progress toward artificial general intelligence. This limitation underscores the importance of developing foundation agents capable of learning through autonomous environmental interactions by reinforcing existing models. Focusing on Web Browser and Phone as representative GUI scenarios, we have developed AutoGLM as a practical foundation agent system for real-world GUI interactions. Our approach integrates a comprehensive suite of techniques and infrastructures to create deployable agent systems suitable for user delivery. Through this development, we have derived two key insights: First, the design of an appropriate "intermediate interface" for GUI control is crucial, enabling the separation of planning and grounding behaviors, which require distinct optimization for flexibility and accuracy respectively. Second, we have developed a novel progressive training framework that enables self-evolving online curriculum reinforcement learning for AutoGLM. Our evaluations demonstrate AutoGLM's effectiveness across multiple domains. For web browsing, AutoGLM achieves a 55.2% success rate on VAB-WebArena-Lite (improving to 59.1% with a second attempt) and 96.2% on OpenTable evaluation tasks. In Android device control, AutoGLM attains a 36.2% success rate on AndroidLab (VAB-Mobile) and 89.7% on common tasks in popular Chinese APPs.
VisualAgentBench: Towards Large Multimodal Models as Visual Foundation Agents
Aug 12, 2024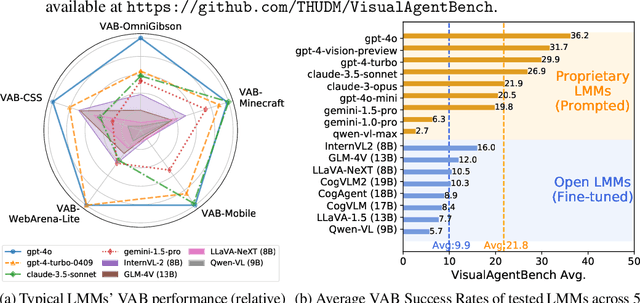
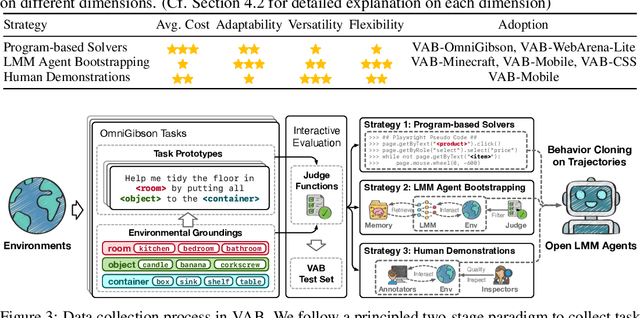
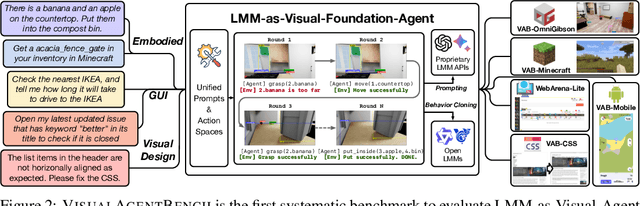
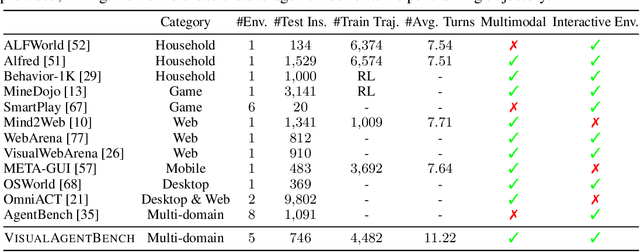
Large Multimodal Models (LMMs) have ushered in a new era in artificial intelligence, merging capabilities in both language and vision to form highly capable Visual Foundation Agents. These agents are postulated to excel across a myriad of tasks, potentially approaching general artificial intelligence. However, existing benchmarks fail to sufficiently challenge or showcase the full potential of LMMs in complex, real-world environments. To address this gap, we introduce VisualAgentBench (VAB), a comprehensive and pioneering benchmark specifically designed to train and evaluate LMMs as visual foundation agents across diverse scenarios, including Embodied, Graphical User Interface, and Visual Design, with tasks formulated to probe the depth of LMMs' understanding and interaction capabilities. Through rigorous testing across nine proprietary LMM APIs and eight open models, we demonstrate the considerable yet still developing agent capabilities of these models. Additionally, VAB constructs a trajectory training set constructed through hybrid methods including Program-based Solvers, LMM Agent Bootstrapping, and Human Demonstrations, promoting substantial performance improvements in LMMs through behavior cloning. Our work not only aims to benchmark existing models but also provides a solid foundation for future development into visual foundation agents. Code, train \& test data, and part of fine-tuned open LMMs are available at \url{https://github.com/THUDM/VisualAgentBench}.
ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools
Jun 18, 2024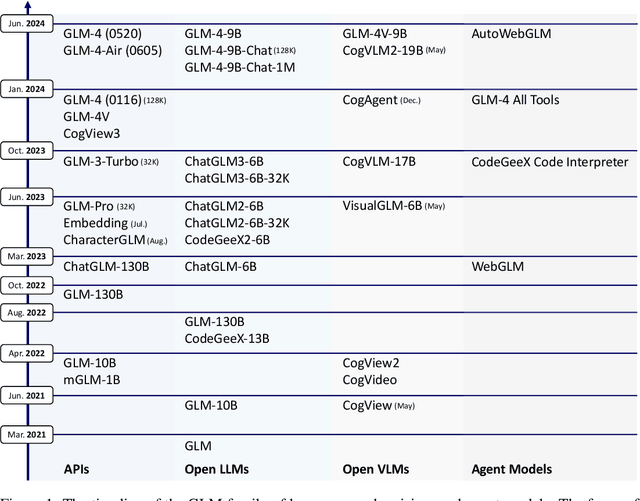
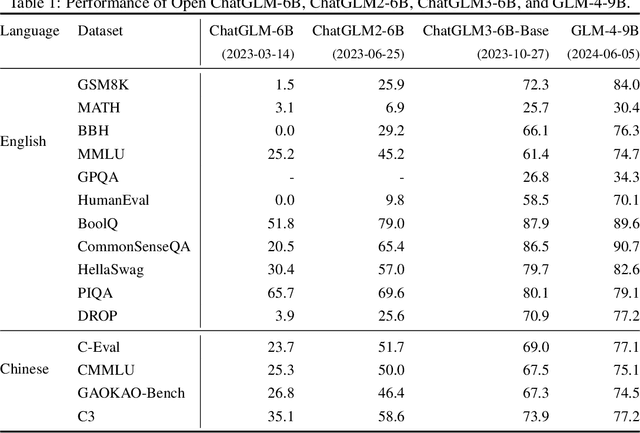
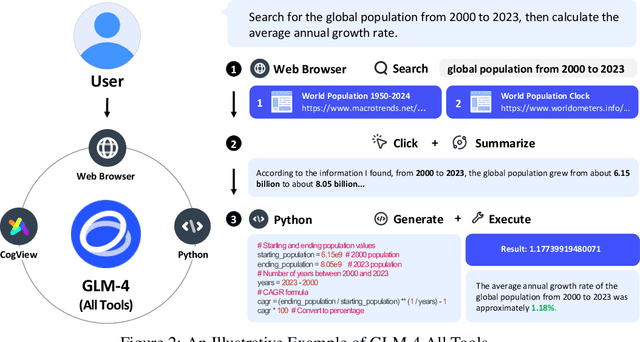
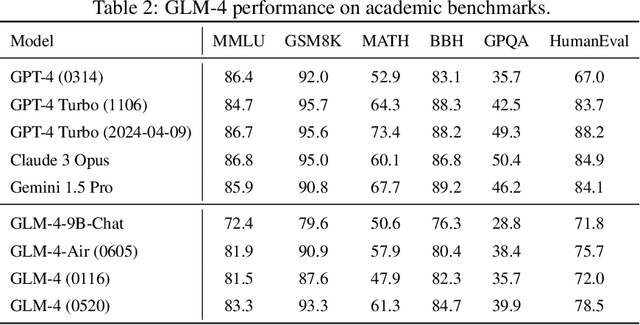
We introduce ChatGLM, an evolving family of large language models that we have been developing over time. This report primarily focuses on the GLM-4 language series, which includes GLM-4, GLM-4-Air, and GLM-4-9B. They represent our most capable models that are trained with all the insights and lessons gained from the preceding three generations of ChatGLM. To date, the GLM-4 models are pre-trained on ten trillions of tokens mostly in Chinese and English, along with a small set of corpus from 24 languages, and aligned primarily for Chinese and English usage. The high-quality alignment is achieved via a multi-stage post-training process, which involves supervised fine-tuning and learning from human feedback. Evaluations show that GLM-4 1) closely rivals or outperforms GPT-4 in terms of general metrics such as MMLU, GSM8K, MATH, BBH, GPQA, and HumanEval, 2) gets close to GPT-4-Turbo in instruction following as measured by IFEval, 3) matches GPT-4 Turbo (128K) and Claude 3 for long context tasks, and 4) outperforms GPT-4 in Chinese alignments as measured by AlignBench. The GLM-4 All Tools model is further aligned to understand user intent and autonomously decide when and which tool(s) touse -- including web browser, Python interpreter, text-to-image model, and user-defined functions -- to effectively complete complex tasks. In practical applications, it matches and even surpasses GPT-4 All Tools in tasks like accessing online information via web browsing and solving math problems using Python interpreter. Over the course, we have open-sourced a series of models, including ChatGLM-6B (three generations), GLM-4-9B (128K, 1M), GLM-4V-9B, WebGLM, and CodeGeeX, attracting over 10 million downloads on Hugging face in the year 2023 alone. The open models can be accessed through https://github.com/THUDM and https://huggingface.co/THUDM.
Forward Flow for Novel View Synthesis of Dynamic Scenes
Sep 29, 2023



This paper proposes a neural radiance field (NeRF) approach for novel view synthesis of dynamic scenes using forward warping. Existing methods often adopt a static NeRF to represent the canonical space, and render dynamic images at other time steps by mapping the sampled 3D points back to the canonical space with the learned backward flow field. However, this backward flow field is non-smooth and discontinuous, which is difficult to be fitted by commonly used smooth motion models. To address this problem, we propose to estimate the forward flow field and directly warp the canonical radiance field to other time steps. Such forward flow field is smooth and continuous within the object region, which benefits the motion model learning. To achieve this goal, we represent the canonical radiance field with voxel grids to enable efficient forward warping, and propose a differentiable warping process, including an average splatting operation and an inpaint network, to resolve the many-to-one and one-to-many mapping issues. Thorough experiments show that our method outperforms existing methods in both novel view rendering and motion modeling, demonstrating the effectiveness of our forward flow motion modeling. Project page: https://npucvr.github.io/ForwardFlowDNeRF
* Accepted by ICCV2023 as oral. Project page: https://npucvr.github.io/ForwardFlowDNeRF
Digging into Depth Priors for Outdoor Neural Radiance Fields
Aug 08, 2023Neural Radiance Fields (NeRF) have demonstrated impressive performance in vision and graphics tasks, such as novel view synthesis and immersive reality. However, the shape-radiance ambiguity of radiance fields remains a challenge, especially in the sparse viewpoints setting. Recent work resorts to integrating depth priors into outdoor NeRF training to alleviate the issue. However, the criteria for selecting depth priors and the relative merits of different priors have not been thoroughly investigated. Moreover, the relative merits of selecting different approaches to use the depth priors is also an unexplored problem. In this paper, we provide a comprehensive study and evaluation of employing depth priors to outdoor neural radiance fields, covering common depth sensing technologies and most application ways. Specifically, we conduct extensive experiments with two representative NeRF methods equipped with four commonly-used depth priors and different depth usages on two widely used outdoor datasets. Our experimental results reveal several interesting findings that can potentially benefit practitioners and researchers in training their NeRF models with depth priors. Project Page: https://cwchenwang.github.io/outdoor-nerf-depth
MapNeRF: Incorporating Map Priors into Neural Radiance Fields for Driving View Simulation
Aug 06, 2023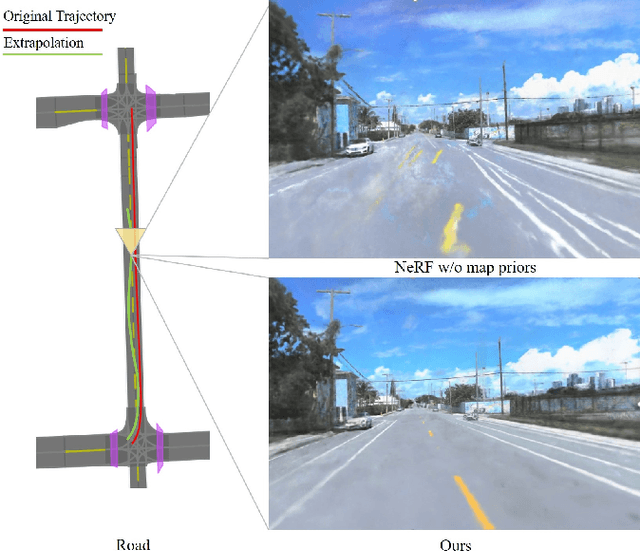
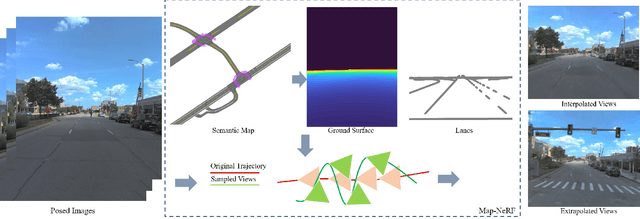
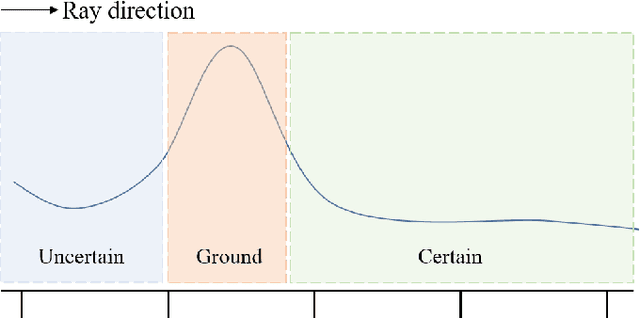

Simulating camera sensors is a crucial task in autonomous driving. Although neural radiance fields are exceptional at synthesizing photorealistic views in driving simulations, they still fail to generate extrapolated views. This paper proposes to incorporate map priors into neural radiance fields to synthesize out-of-trajectory driving views with semantic road consistency. The key insight is that map information can be utilized as a prior to guiding the training of the radiance fields with uncertainty. Specifically, we utilize the coarse ground surface as uncertain information to supervise the density field and warp depth with uncertainty from unknown camera poses to ensure multi-view consistency. Experimental results demonstrate that our approach can produce semantic consistency in deviated views for vehicle camera simulation. The supplementary video can be viewed at https://youtu.be/jEQWr-Rfh3A.
CU-Net: LiDAR Depth-Only Completion With Coupled U-Net
Oct 26, 2022
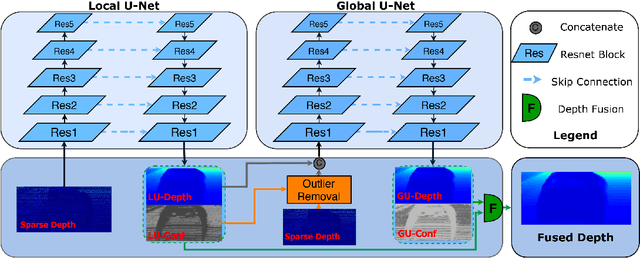


LiDAR depth-only completion is a challenging task to estimate dense depth maps only from sparse measurement points obtained by LiDAR. Even though the depth-only methods have been widely developed, there is still a significant performance gap with the RGB-guided methods that utilize extra color images. We find that existing depth-only methods can obtain satisfactory results in the areas where the measurement points are almost accurate and evenly distributed (denoted as normal areas), while the performance is limited in the areas where the foreground and background points are overlapped due to occlusion (denoted as overlap areas) and the areas where there are no measurement points around (denoted as blank areas) since the methods have no reliable input information in these areas. Building upon these observations, we propose an effective Coupled U-Net (CU-Net) architecture for depth-only completion. Instead of directly using a large network for regression, we employ the local U-Net to estimate accurate values in the normal areas and provide the global U-Net with reliable initial values in the overlap and blank areas. The depth maps predicted by the two coupled U-Nets are fused by learned confidence maps to obtain final results. In addition, we propose a confidence-based outlier removal module, which removes outliers using simple judgment conditions. Our proposed method boosts the final results with fewer parameters and achieves state-of-the-art results on the KITTI benchmark. Moreover, it owns a powerful generalization ability under various depth densities, varying lighting, and weather conditions.
Learning a Task-specific Descriptor for Robust Matching of 3D Point Clouds
Oct 26, 2022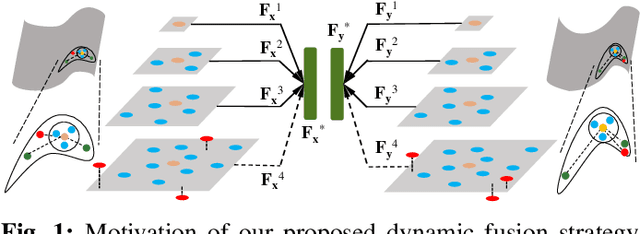



Existing learning-based point feature descriptors are usually task-agnostic, which pursue describing the individual 3D point clouds as accurate as possible. However, the matching task aims at describing the corresponding points consistently across different 3D point clouds. Therefore these too accurate features may play a counterproductive role due to the inconsistent point feature representations of correspondences caused by the unpredictable noise, partiality, deformation, \etc, in the local geometry. In this paper, we propose to learn a robust task-specific feature descriptor to consistently describe the correct point correspondence under interference. Born with an Encoder and a Dynamic Fusion module, our method EDFNet develops from two aspects. First, we augment the matchability of correspondences by utilizing their repetitive local structure. To this end, a special encoder is designed to exploit two input point clouds jointly for each point descriptor. It not only captures the local geometry of each point in the current point cloud by convolution, but also exploits the repetitive structure from paired point cloud by Transformer. Second, we propose a dynamical fusion module to jointly use different scale features. There is an inevitable struggle between robustness and discriminativeness of the single scale feature. Specifically, the small scale feature is robust since little interference exists in this small receptive field. But it is not sufficiently discriminative as there are many repetitive local structures within a point cloud. Thus the resultant descriptors will lead to many incorrect matches. In contrast, the large scale feature is more discriminative by integrating more neighborhood information. ...
Searching Dense Point Correspondences via Permutation Matrix Learning
Oct 26, 2022



Although 3D point cloud data has received widespread attentions as a general form of 3D signal expression, applying point clouds to the task of dense correspondence estimation between 3D shapes has not been investigated widely. Furthermore, even in the few existing 3D point cloud-based methods, an important and widely acknowledged principle, i.e . one-to-one matching, is usually ignored. In response, this paper presents a novel end-to-end learning-based method to estimate the dense correspondence of 3D point clouds, in which the problem of point matching is formulated as a zero-one assignment problem to achieve a permutation matching matrix to implement the one-to-one principle fundamentally. Note that the classical solutions of this assignment problem are always non-differentiable, which is fatal for deep learning frameworks. Thus we design a special matching module, which solves a doubly stochastic matrix at first and then projects this obtained approximate solution to the desired permutation matrix. Moreover, to guarantee end-to-end learning and the accuracy of the calculated loss, we calculate the loss from the learned permutation matrix but propagate the gradient to the doubly stochastic matrix directly which bypasses the permutation matrix during the backward propagation. Our method can be applied to both non-rigid and rigid 3D point cloud data and extensive experiments show that our method achieves state-of-the-art performance for dense correspondence learning.