 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVALLR-Pin: Uncertainty-Factorized Visual Speech Recognition for Mandarin with Pinyin Guidance
Dec 29, 2025Visual speech recognition (VSR) aims to transcribe spoken content from silent lip-motion videos and is particularly challenging in Mandarin due to severe viseme ambiguity and pervasive homophones. We propose VALLR-Pin, a two-stage Mandarin VSR framework that extends the VALLR architecture by explicitly incorporating Pinyin as an intermediate representation. In the first stage, a shared visual encoder feeds dual decoders that jointly predict Mandarin characters and their corresponding Pinyin sequences, encouraging more robust visual-linguistic representations. In the second stage, an LLM-based refinement module takes the predicted Pinyin sequence together with an N-best list of character hypotheses to resolve homophone-induced ambiguities. To further adapt the LLM to visual recognition errors, we fine-tune it on synthetic instruction data constructed from model-generated Pinyin-text pairs, enabling error-aware correction. Experiments on public Mandarin VSR benchmarks demonstrate that VALLR-Pin consistently improves transcription accuracy under multi-speaker conditions, highlighting the effectiveness of combining phonetic guidance with lightweight LLM refinement.
VALLR-Pin: Dual-Decoding Visual Speech Recognition for Mandarin with Pinyin-Guided LLM Refinement
Dec 23, 2025Visual Speech Recognition aims to transcribe spoken words from silent lip-motion videos. This task is particularly challenging for Mandarin, as visemes are highly ambiguous and homophones are prevalent. We propose VALLR-Pin, a novel two-stage framework that extends the recent VALLR architecture from English to Mandarin. First, a shared video encoder feeds into dual decoders, which jointly predict both Chinese character sequences and their standard Pinyin romanization. The multi-task learning of character and phonetic outputs fosters robust visual-semantic representations. During inference, the text decoder generates multiple candidate transcripts. We construct a prompt by concatenating the Pinyin output with these candidate Chinese sequences and feed it to a large language model to resolve ambiguities and refine the transcription. This provides the LLM with explicit phonetic context to correct homophone-induced errors. Finally, we fine-tune the LLM on synthetic noisy examples: we generate imperfect Pinyin-text pairs from intermediate VALLR-Pin checkpoints using the training data, creating instruction-response pairs for error correction. This endows the LLM with awareness of our model's specific error patterns. In summary, VALLR-Pin synergizes visual features with phonetic and linguistic context to improve Mandarin lip-reading performance.
Skillful Subseasonal-to-Seasonal Forecasting of Extreme Events with a Multi-Sphere Coupled Probabilistic Model
Dec 14, 2025Accurate subseasonal-to-seasonal (S2S) prediction of extreme events is critical for resource planning and disaster mitigation under accelerating climate change. However, such predictions remain challenging due to complex multi-sphere interactions and intrinsic atmospheric uncertainty. Here we present TianXing-S2S, a multi-sphere coupled probabilistic model for global S2S daily ensemble forecast. TianXing-S2S first encodes diverse multi-sphere predictors into a compact latent space, then employs a diffusion model to generate daily ensemble forecasts. A novel coupling module based on optimal transport (OT) is incorporated in the denoiser to optimize the interactions between atmospheric and multi-sphere boundary conditions. Across key atmospheric variables, TianXing-S2S outperforms both the European Centre for Medium-Range Weather Forecasts (ECMWF) S2S system and FuXi-S2S in 45-day daily-mean ensemble forecasts at 1.5 resolution. Our model achieves skillful subseasonal prediction of extreme events including heat waves and anomalous precipitation, identifying soil moisture as a critical precursor signal. Furthermore, we demonstrate that TianXing-S2S can generate stable rollout forecasts up to 180 days, establishing a robust framework for S2S research in a warming world.
X-CrossNet: A complex spectral mapping approach to target speaker extraction with cross attention speaker embedding fusion
Nov 21, 2024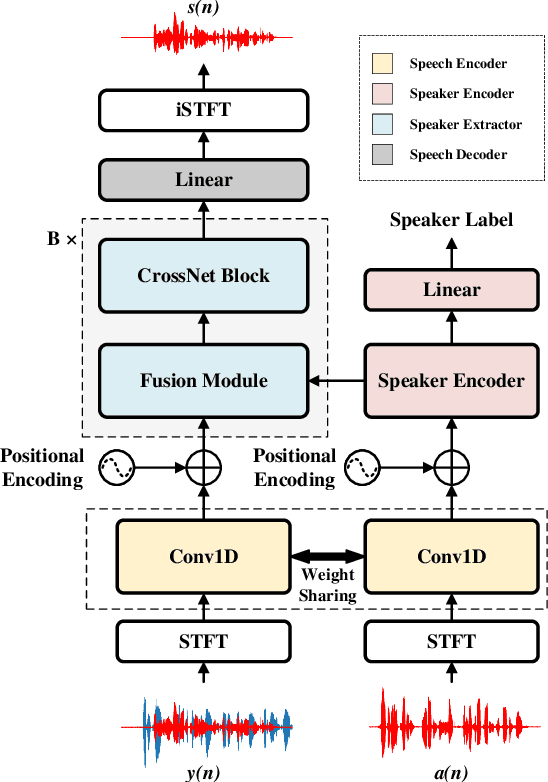
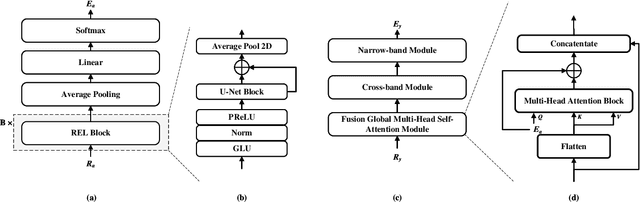
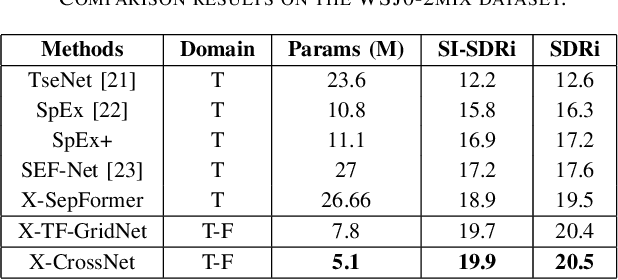
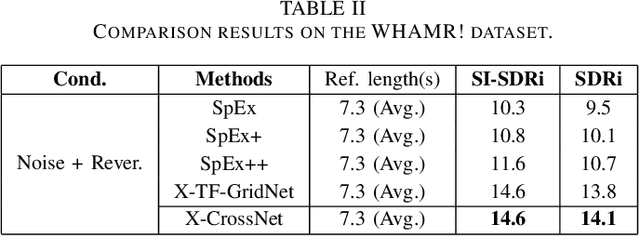
Target speaker extraction (TSE) is a technique for isolating a target speaker's voice from mixed speech using auxiliary features associated with the target speaker. This approach addresses the cocktail party problem and is generally considered more promising for practical applications than conventional speech separation methods. Although academic research in this area has achieved high accuracy and evaluation scores on public datasets, most models exhibit significantly reduced performance in real-world noisy or reverberant conditions. To address this limitation, we propose a novel TSE model, X-CrossNet, which leverages CrossNet as its backbone. CrossNet is a speech separation network specifically optimized for challenging noisy and reverberant environments, achieving state-of-the-art performance in tasks such as speaker separation under these conditions. Additionally, to enhance the network's ability to capture and utilize auxiliary features of the target speaker, we integrate a Cross-Attention mechanism into the global multi-head self-attention (GMHSA) module within each CrossNet block. This facilitates more effective integration of target speaker features with mixed speech features. Experimental results show that our method performs superior separation on the WSJ0-2mix and WHAMR! datasets, demonstrating strong robustness and stability.
AutoGLM: Autonomous Foundation Agents for GUIs
Oct 28, 2024



We present AutoGLM, a new series in the ChatGLM family, designed to serve as foundation agents for autonomous control of digital devices through Graphical User Interfaces (GUIs). While foundation models excel at acquiring human knowledge, they often struggle with decision-making in dynamic real-world environments, limiting their progress toward artificial general intelligence. This limitation underscores the importance of developing foundation agents capable of learning through autonomous environmental interactions by reinforcing existing models. Focusing on Web Browser and Phone as representative GUI scenarios, we have developed AutoGLM as a practical foundation agent system for real-world GUI interactions. Our approach integrates a comprehensive suite of techniques and infrastructures to create deployable agent systems suitable for user delivery. Through this development, we have derived two key insights: First, the design of an appropriate "intermediate interface" for GUI control is crucial, enabling the separation of planning and grounding behaviors, which require distinct optimization for flexibility and accuracy respectively. Second, we have developed a novel progressive training framework that enables self-evolving online curriculum reinforcement learning for AutoGLM. Our evaluations demonstrate AutoGLM's effectiveness across multiple domains. For web browsing, AutoGLM achieves a 55.2% success rate on VAB-WebArena-Lite (improving to 59.1% with a second attempt) and 96.2% on OpenTable evaluation tasks. In Android device control, AutoGLM attains a 36.2% success rate on AndroidLab (VAB-Mobile) and 89.7% on common tasks in popular Chinese APPs.
Weighted Joint Maximum Mean Discrepancy Enabled Multi-Source-Multi-Target Unsupervised Domain Adaptation Fault Diagnosis
Oct 20, 2023
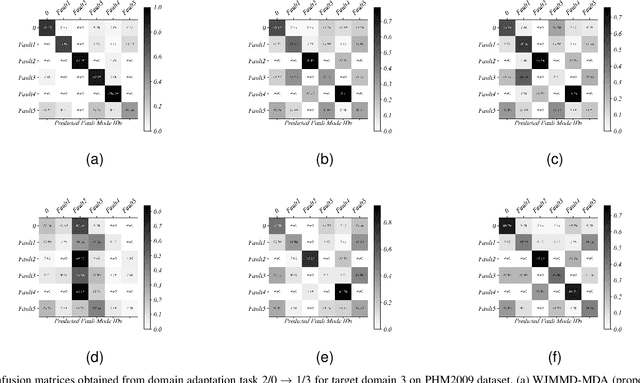


Despite the remarkable results that can be achieved by data-driven intelligent fault diagnosis techniques, they presuppose the same distribution of training and test data as well as sufficient labeled data. Various operating states often exist in practical scenarios, leading to the problem of domain shift that hinders the effectiveness of fault diagnosis. While recent unsupervised domain adaptation methods enable cross-domain fault diagnosis, they struggle to effectively utilize information from multiple source domains and achieve effective diagnosis faults in multiple target domains simultaneously. In this paper, we innovatively proposed a weighted joint maximum mean discrepancy enabled multi-source-multi-target unsupervised domain adaptation (WJMMD-MDA), which realizes domain adaptation under multi-source-multi-target scenarios in the field of fault diagnosis for the first time. The proposed method extracts sufficient information from multiple labeled source domains and achieves domain alignment between source and target domains through an improved weighted distance loss. As a result, domain-invariant and discriminative features between multiple source and target domains are learned with cross-domain fault diagnosis realized. The performance of the proposed method is evaluated in comprehensive comparative experiments on three datasets, and the experimental results demonstrate the superiority of this method.
Hard Sample Mining Enabled Contrastive Feature Learning for Wind Turbine Pitch System Fault Diagnosis
Jun 26, 2023The efficient utilization of wind power by wind turbines relies on the ability of their pitch systems to adjust blade pitch angles in response to varying wind speeds. However, the presence of multiple fault types in the pitch system poses challenges in accurately classifying these faults. This paper proposes a novel method based on hard sample mining-enabled contrastive feature learning (HSMCFL) to address this problem. The proposed method employs cosine similarity to identify hard samples and subsequently leverages contrastive feature learning to enhance representation learning through the construction of hard sample pairs. Furthermore, a multilayer perceptron is trained using the learned discriminative representations to serve as an efficient classifier. To evaluate the effectiveness of the proposed method, two real datasets comprising wind turbine pitch system cog belt fracture data are utilized. The fault diagnosis performance of the proposed method is compared against existing methods, and the results demonstrate its superior performance. The proposed approach exhibits significant improvements in fault diagnosis accuracy, providing promising prospects for enhancing the reliability and efficiency of wind turbine pitch system fault diagnosis.
The RoyalFlush System for the WMT 2022 Efficiency Task
Dec 03, 2022This paper describes the submission of the RoyalFlush neural machine translation system for the WMT 2022 translation efficiency task. Unlike the commonly used autoregressive translation system, we adopted a two-stage translation paradigm called Hybrid Regression Translation (HRT) to combine the advantages of autoregressive and non-autoregressive translation. Specifically, HRT first autoregressively generates a discontinuous sequence (e.g., make a prediction every $k$ tokens, $k>1$) and then fills in all previously skipped tokens at once in a non-autoregressive manner. Thus, we can easily trade off the translation quality and speed by adjusting $k$. In addition, by integrating other modeling techniques (e.g., sequence-level knowledge distillation and deep-encoder-shallow-decoder layer allocation strategy) and a mass of engineering efforts, HRT improves 80\% inference speed and achieves equivalent translation performance with the same-capacity AT counterpart. Our fastest system reaches 6k+ words/second on the GPU latency setting, estimated to be about 3.1x faster than the last year's winner.
Slow-varying Dynamics Assisted Temporal Capsule Network for Machinery Remaining Useful Life Estimation
Mar 30, 2022
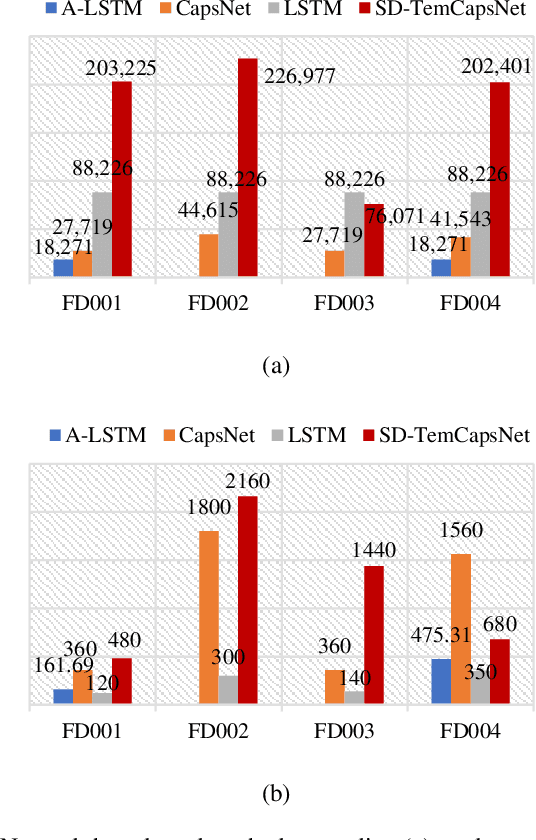
Capsule network (CapsNet) acts as a promising alternative to the typical convolutional neural network, which is the dominant network to develop the remaining useful life (RUL) estimation models for mechanical equipment. Although CapsNet comes with an impressive ability to represent the entities' hierarchical relationships through a high-dimensional vector embedding, it fails to capture the long-term temporal correlation of run-to-failure time series measured from degraded mechanical equipment. On the other hand, the slow-varying dynamics, which reveals the low-frequency information hidden in mechanical dynamical behaviour, is overlooked in the existing RUL estimation models, limiting the utmost ability of advanced networks. To address the aforementioned concerns, we propose a Slow-varying Dynamics assisted Temporal CapsNet (SD-TemCapsNet) to simultaneously learn the slow-varying dynamics and temporal dynamics from measurements for accurate RUL estimation. First, in light of the sensitivity of fault evolution, slow-varying features are decomposed from normal raw data to convey the low-frequency components corresponding to the system dynamics. Next, the long short-term memory (LSTM) mechanism is introduced into CapsNet to capture the temporal correlation of time series. To this end, experiments conducted on an aircraft engine and a milling machine verify that the proposed SD-TemCapsNet outperforms the mainstream methods. In comparison with CapsNet, the estimation accuracy of the aircraft engine with four different scenarios has been improved by 10.17%, 24.97%, 3.25%, and 13.03% concerning the index root mean squared error, respectively. Similarly, the estimation accuracy of the milling machine has been improved by 23.57% compared to LSTM and 19.54% compared to CapsNet.
Handwritten Mathematical Expression Recognition via Attention Aggregation based Bi-directional Mutual Learning
Dec 07, 2021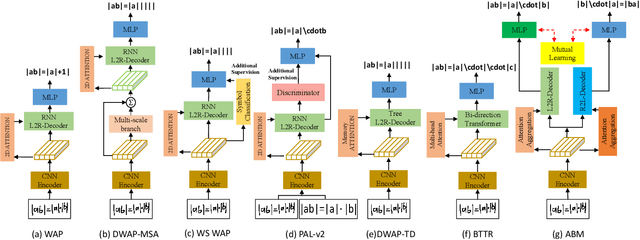
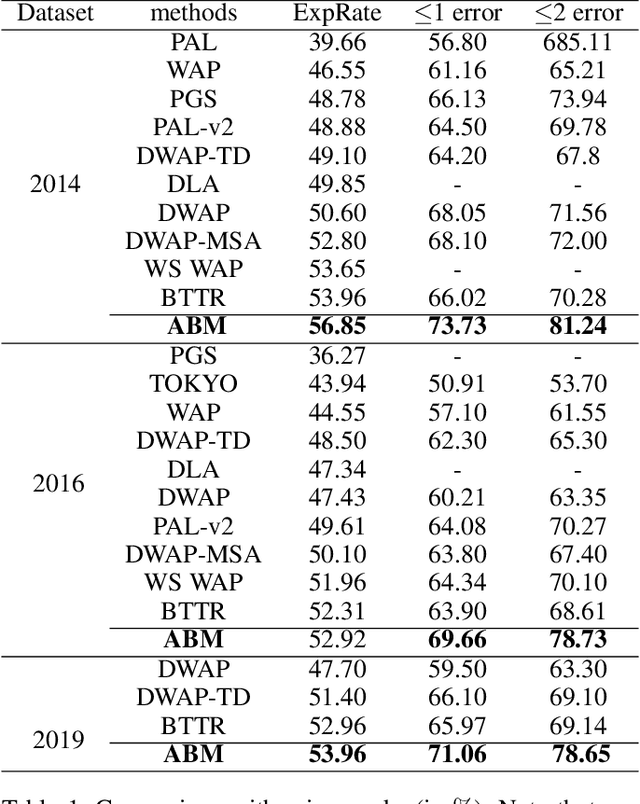
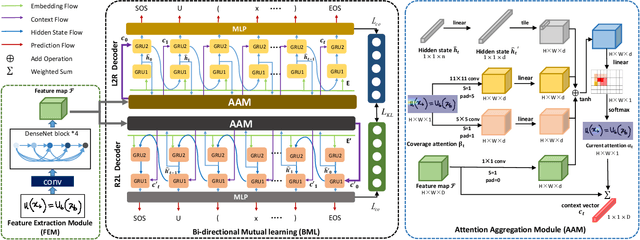
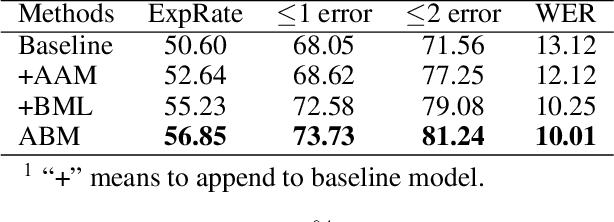
Handwritten mathematical expression recognition aims to automatically generate LaTeX sequences from given images. Currently, attention-based encoder-decoder models are widely used in this task. They typically generate target sequences in a left-to-right (L2R) manner, leaving the right-to-left (R2L) contexts unexploited. In this paper, we propose an Attention aggregation based Bi-directional Mutual learning Network (ABM) which consists of one shared encoder and two parallel inverse decoders (L2R and R2L). The two decoders are enhanced via mutual distillation, which involves one-to-one knowledge transfer at each training step, making full use of the complementary information from two inverse directions. Moreover, in order to deal with mathematical symbols in diverse scales, an Attention Aggregation Module (AAM) is proposed to effectively integrate multi-scale coverage attentions. Notably, in the inference phase, given that the model already learns knowledge from two inverse directions, we only use the L2R branch for inference, keeping the original parameter size and inference speed. Extensive experiments demonstrate that our proposed approach achieves the recognition accuracy of 56.85 % on CROHME 2014, 52.92 % on CROHME 2016, and 53.96 % on CROHME 2019 without data augmentation and model ensembling, substantially outperforming the state-of-the-art methods. The source code is available in the supplementary materials.
* 9 pages,5 figures, to be published in AAAI 2022