 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHaS: Accelerating RAG through Homology-Aware Speculative Retrieval
Apr 22, 2026Retrieval-Augmented Generation (RAG) expands the knowledge boundary of large language models (LLMs) at inference by retrieving external documents as context. However, retrieval becomes increasingly time-consuming as the knowledge databases grow in size. Existing acceleration strategies either compromise accuracy through approximate retrieval, or achieve marginal gains by reusing results of strictly identical queries. We propose HaS, a homology-aware speculative retrieval framework that performs low-latency speculative retrieval over restricted scopes to obtain candidate documents, followed by validating whether they contain the required knowledge. The validation, grounded in the homology relation between queries, is formulated as a homologous query re-identification task: once a previously observed query is identified as a homologous re-encounter of the incoming query, the draft is deemed acceptable, allowing the system to bypass slow full-database retrieval. Benefiting from the prevalence of homologous queries under real-world popularity patterns, HaS achieves substantial efficiency gains. Extensive experiments demonstrate that HaS reduces retrieval latency by 23.74% and 36.99% across datasets with only a 1-2% marginal accuracy drop. As a plug-and-play solution, HaS also significantly accelerates complex multi-hop queries in modern agentic RAG pipelines. Source code is available at: https://github.com/ErrEqualsNil/HaS.
FSP-Diff: Full-Spectrum Prior-Enhanced DualDomain Latent Diffusion for Ultra-Low-Dose Spectral CT Reconstruction
Feb 08, 2026Spectral computed tomography (CT) with photon-counting detectors holds immense potential for material discrimination and tissue characterization. However, under ultra-low-dose conditions, the sharply degraded signal-to-noise ratio (SNR) in energy-specific projections poses a significant challenge, leading to severe artifacts and loss of structural details in reconstructed images. To address this, we propose FSP-Diff, a full-spectrum prior-enhanced dual-domain latent diffusion framework for ultra-low-dose spectral CT reconstruction. Our framework integrates three core strategies: 1) Complementary Feature Construction: We integrate direct image reconstructions with projection-domain denoised results. While the former preserves latent textural nuances amidst heavy noise, the latter provides a stable structural scaffold to balance detail fidelity and noise suppression. 2) Full-Spectrum Prior Integration: By fusing multi-energy projections into a high-SNR full-spectrum image, we establish a unified structural reference that guides the reconstruction across all energy bins. 3) Efficient Latent Diffusion Synthesis: To alleviate the high computational burden of high-dimensional spectral data, multi-path features are embedded into a compact latent space. This allows the diffusion process to facilitate interactive feature fusion in a lower-dimensional manifold, achieving accelerated reconstruction while maintaining fine-grained detail restoration. Extensive experiments on simulated and real-world datasets demonstrate that FSP-Diff significantly outperforms state-of-the-art methods in both image quality and computational efficiency, underscoring its potential for clinically viable ultra-low-dose spectral CT imaging.
Continuity-driven Synergistic Diffusion with Neural Priors for Ultra-Sparse-View CBCT Reconstruction
Feb 08, 2026The clinical application of cone-beam computed tomography (CBCT) is constrained by the inherent trade-off between radiation exposure and image quality. Ultra-sparse angular sampling, employed to reduce dose, introduces severe undersampling artifacts and inter-slice inconsistencies, compromising diagnostic reliability. Existing reconstruction methods often struggle to balance angular continuity with spatial detail fidelity. To address these challenges, we propose a Continuity-driven Synergistic Diffusion with Neural priors (CSDN) for ultra-sparse-view CBCT reconstruction. Neural priors are introduced as a structural foundation to encode a continuous threedimensional attenuation representation, enabling the synthesis of physically consistent dense projections from ultra-sparse measurements. Building upon this neural-prior-based initialization, a synergistic diffusion strategy is developed, consisting of two collaborative refinement paths: a Sinogram Refinement Diffusion (Sino-RD) process that restores angular continuity and a Digital Radiography Refinement Diffusion (DR-RD) process that enforces inter-slice consistency from the projection image perspective. The outputs of the two diffusion paths are adaptively fused by the Dual-Projection Reconstruction Fusion (DPRF) module to achieve coherent volumetric reconstruction. Extensive experiments demonstrate that the proposed CSDN effectively suppresses artifacts and recovers fine textures under ultra-sparse-view conditions, outperforming existing state-of-the-art techniques.
PROMISE: Prompt-Attentive Hierarchical Contrastive Learning for Robust Cross-Modal Representation with Missing Modalities
Nov 14, 2025Multimodal models integrating natural language and visual information have substantially improved generalization of representation models. However, their effectiveness significantly declines in real-world situations where certain modalities are missing or unavailable. This degradation primarily stems from inconsistent representation learning between complete multimodal data and incomplete modality scenarios. Existing approaches typically address missing modalities through relatively simplistic generation methods, yet these approaches fail to adequately preserve cross-modal consistency, leading to suboptimal performance. To overcome this limitation, we propose a novel multimodal framework named PROMISE, a PROMpting-Attentive HIerarchical ContraStive LEarning approach designed explicitly for robust cross-modal representation under conditions of missing modalities. Specifically, PROMISE innovatively incorporates multimodal prompt learning into a hierarchical contrastive learning framework, equipped with a specially designed prompt-attention mechanism. This mechanism dynamically generates robust and consistent representations for scenarios where particular modalities are absent, thereby effectively bridging the representational gap between complete and incomplete data. Extensive experiments conducted on benchmark datasets, along with comprehensive ablation studies, clearly demonstrate the superior performance of PROMISE compared to current state-of-the-art multimodal methods.
FedRS-Bench: Realistic Federated Learning Datasets and Benchmarks in Remote Sensing
May 13, 2025Remote sensing (RS) images are usually produced at an unprecedented scale, yet they are geographically and institutionally distributed, making centralized model training challenging due to data-sharing restrictions and privacy concerns. Federated learning (FL) offers a solution by enabling collaborative model training across decentralized RS data sources without exposing raw data. However, there lacks a realistic federated dataset and benchmark in RS. Prior works typically rely on manually partitioned single dataset, which fail to capture the heterogeneity and scale of real-world RS data, and often use inconsistent experimental setups, hindering fair comparison. To address this gap, we propose a realistic federated RS dataset, termed FedRS. FedRS consists of eight datasets that cover various sensors and resolutions and builds 135 clients, which is representative of realistic operational scenarios. Data for each client come from the same source, exhibiting authentic federated properties such as skewed label distributions, imbalanced client data volumes, and domain heterogeneity across clients. These characteristics reflect practical challenges in federated RS and support evaluation of FL methods at scale. Based on FedRS, we implement 10 baseline FL algorithms and evaluation metrics to construct the comprehensive FedRS-Bench. The experimental results demonstrate that FL can consistently improve model performance over training on isolated data silos, while revealing performance trade-offs of different methods under varying client heterogeneity and availability conditions. We hope FedRS-Bench will accelerate research on large-scale, realistic FL in RS by providing a standardized, rich testbed and facilitating fair comparisons across future works. The source codes and dataset are available at https://fedrs-bench.github.io/.
Class Incremental Fault Diagnosis under Limited Fault Data via Supervised Contrastive Knowledge Distillation
Jan 16, 2025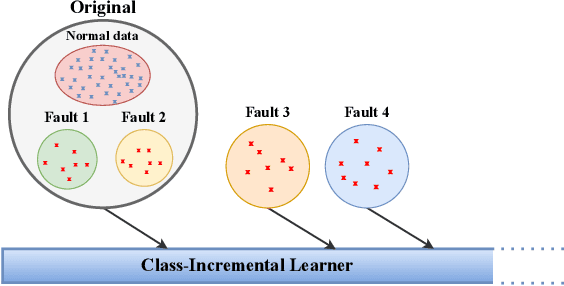
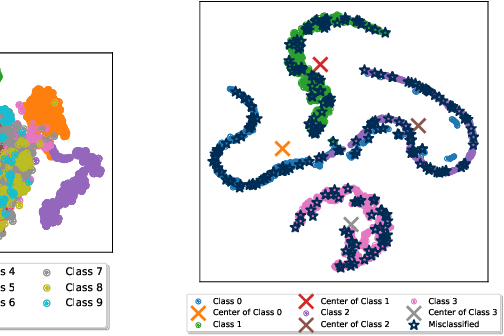
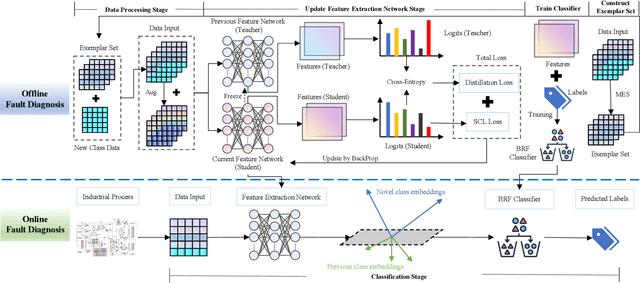
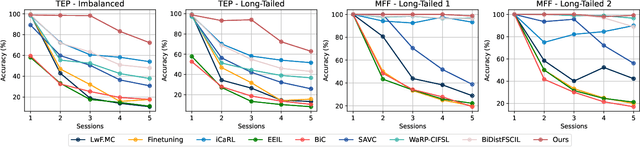
Class-incremental fault diagnosis requires a model to adapt to new fault classes while retaining previous knowledge. However, limited research exists for imbalanced and long-tailed data. Extracting discriminative features from few-shot fault data is challenging, and adding new fault classes often demands costly model retraining. Moreover, incremental training of existing methods risks catastrophic forgetting, and severe class imbalance can bias the model's decisions toward normal classes. To tackle these issues, we introduce a Supervised Contrastive knowledge distiLlation for class Incremental Fault Diagnosis (SCLIFD) framework proposing supervised contrastive knowledge distillation for improved representation learning capability and less forgetting, a novel prioritized exemplar selection method for sample replay to alleviate catastrophic forgetting, and the Random Forest Classifier to address the class imbalance. Extensive experimentation on simulated and real-world industrial datasets across various imbalance ratios demonstrates the superiority of SCLIFD over existing approaches. Our code can be found at https://github.com/Zhang-Henry/SCLIFD_TII.
Internal Contrastive Learning for Generalized Out-of-distribution Fault Diagnosis (GOOFD) Framework
Jun 27, 2023Fault diagnosis is essential in industrial processes for monitoring the conditions of important machines. With the ever-increasing complexity of working conditions and demand for safety during production and operation, different diagnosis methods are required, and more importantly, an integrated fault diagnosis system that can cope with multiple tasks is highly desired. However, the diagnosis subtasks are often studied separately, and the currently available methods still need improvement for such a generalized system. To address this issue, we propose the Generalized Out-of-distribution Fault Diagnosis (GOOFD) framework to integrate diagnosis subtasks, such as fault detection, fault classification, and novel fault diagnosis. Additionally, a unified fault diagnosis method based on internal contrastive learning is put forward to underpin the proposed generalized framework. The method extracts features utilizing the internal contrastive learning technique and then recognizes the outliers based on the Mahalanobis distance. Experiments are conducted on a simulated benchmark dataset as well as two practical process datasets to evaluate the proposed framework. As demonstrated in the experiments, the proposed method achieves better performance compared with several existing techniques and thus verifies the effectiveness of the proposed framework.
Hard Sample Mining Enabled Contrastive Feature Learning for Wind Turbine Pitch System Fault Diagnosis
Jun 26, 2023The efficient utilization of wind power by wind turbines relies on the ability of their pitch systems to adjust blade pitch angles in response to varying wind speeds. However, the presence of multiple fault types in the pitch system poses challenges in accurately classifying these faults. This paper proposes a novel method based on hard sample mining-enabled contrastive feature learning (HSMCFL) to address this problem. The proposed method employs cosine similarity to identify hard samples and subsequently leverages contrastive feature learning to enhance representation learning through the construction of hard sample pairs. Furthermore, a multilayer perceptron is trained using the learned discriminative representations to serve as an efficient classifier. To evaluate the effectiveness of the proposed method, two real datasets comprising wind turbine pitch system cog belt fracture data are utilized. The fault diagnosis performance of the proposed method is compared against existing methods, and the results demonstrate its superior performance. The proposed approach exhibits significant improvements in fault diagnosis accuracy, providing promising prospects for enhancing the reliability and efficiency of wind turbine pitch system fault diagnosis.
SCCAM: Supervised Contrastive Convolutional Attention Mechanism for Ante-hoc Interpretable Fault Diagnosis with Limited Fault Samples
Feb 17, 2023



In real industrial processes, fault diagnosis methods are required to learn from limited fault samples since the procedures are mainly under normal conditions and the faults rarely occur. Although attention mechanisms have become popular in the field of fault diagnosis, the existing attention-based methods are still unsatisfying for the above practical applications. First, pure attention-based architectures like transformers need a large number of fault samples to offset the lack of inductive biases thus performing poorly under limited fault samples. Moreover, the poor fault classification dilemma further leads to the failure of the existing attention-based methods to identify the root causes. To address the aforementioned issues, we innovatively propose a supervised contrastive convolutional attention mechanism (SCCAM) with ante-hoc interpretability, which solves the root cause analysis problem under limited fault samples for the first time. The proposed SCCAM method is tested on a continuous stirred tank heater and the Tennessee Eastman industrial process benchmark. Three common fault diagnosis scenarios are covered, including a balanced scenario for additional verification and two scenarios with limited fault samples (i.e., imbalanced scenario and long-tail scenario). The comprehensive results demonstrate that the proposed SCCAM method can achieve better performance compared with the state-of-the-art methods on fault classification and root cause analysis.
An Order-Invariant and Interpretable Hierarchical Dilated Convolution Neural Network for Chemical Fault Detection and Diagnosis
Feb 13, 2023



Fault detection and diagnosis is significant for reducing maintenance costs and improving health and safety in chemical processes. Convolution neural network (CNN) is a popular deep learning algorithm with many successful applications in chemical fault detection and diagnosis tasks. However, convolution layers in CNN are very sensitive to the order of features, which can lead to instability in the processing of tabular data. Optimal order of features result in better performance of CNN models but it is expensive to seek such optimal order. In addition, because of the encapsulation mechanism of feature extraction, most CNN models are opaque and have poor interpretability, thus failing to identify root-cause features without human supervision. These difficulties inevitably limit the performance and credibility of CNN methods. In this paper, we propose an order-invariant and interpretable hierarchical dilated convolution neural network (HDLCNN), which is composed by feature clustering, dilated convolution and the shapley additive explanations (SHAP) method. The novelty of HDLCNN lies in its capability of processing tabular data with features of arbitrary order without seeking the optimal order, due to the ability to agglomerate correlated features of feature clustering and the large receptive field of dilated convolution. Then, the proposed method provides interpretability by including the SHAP values to quantify feature contribution. Therefore, the root-cause features can be identified as the features with the highest contribution. Computational experiments are conducted on the Tennessee Eastman chemical process benchmark dataset. Compared with the other methods, the proposed HDLCNN-SHAP method achieves better performance on processing tabular data with features of arbitrary order, detecting faults, and identifying the root-cause features.