 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFreeQ-Graph: Free-form Querying with Semantic Consistent Scene Graph for 3D Scene Understanding
Jun 16, 2025Semantic querying in complex 3D scenes through free-form language presents a significant challenge. Existing 3D scene understanding methods use large-scale training data and CLIP to align text queries with 3D semantic features. However, their reliance on predefined vocabulary priors from training data hinders free-form semantic querying. Besides, recent advanced methods rely on LLMs for scene understanding but lack comprehensive 3D scene-level information and often overlook the potential inconsistencies in LLM-generated outputs. In our paper, we propose FreeQ-Graph, which enables Free-form Querying with a semantic consistent scene Graph for 3D scene understanding. The core idea is to encode free-form queries from a complete and accurate 3D scene graph without predefined vocabularies, and to align them with 3D consistent semantic labels, which accomplished through three key steps. We initiate by constructing a complete and accurate 3D scene graph that maps free-form objects and their relations through LLM and LVLM guidance, entirely free from training data or predefined priors. Most importantly, we align graph nodes with accurate semantic labels by leveraging 3D semantic aligned features from merged superpoints, enhancing 3D semantic consistency. To enable free-form semantic querying, we then design an LLM-based reasoning algorithm that combines scene-level and object-level information to intricate reasoning. We conducted extensive experiments on 3D semantic grounding, segmentation, and complex querying tasks, while also validating the accuracy of graph generation. Experiments on 6 datasets show that our model excels in both complex free-form semantic queries and intricate relational reasoning.
Hi-LSplat: Hierarchical 3D Language Gaussian Splatting
Jun 07, 2025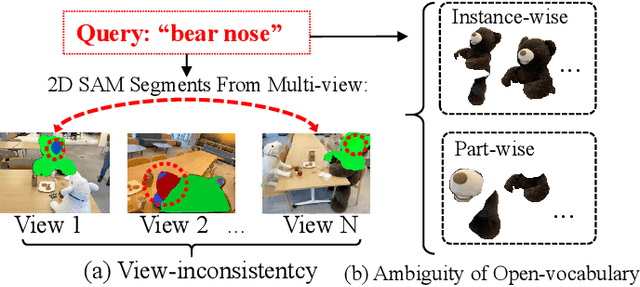
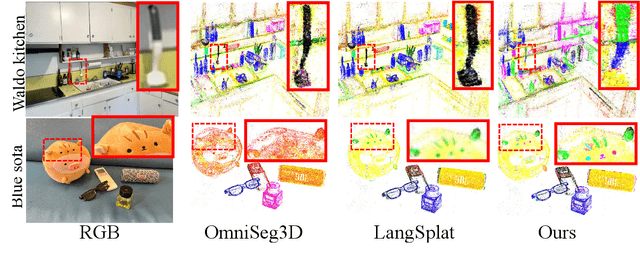
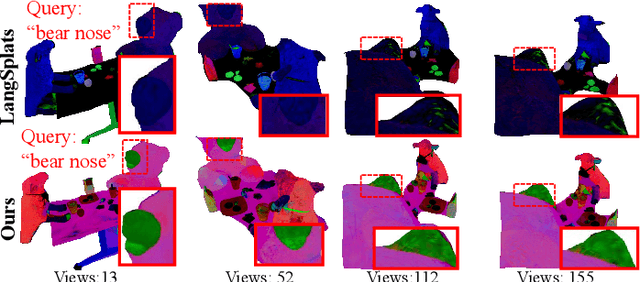
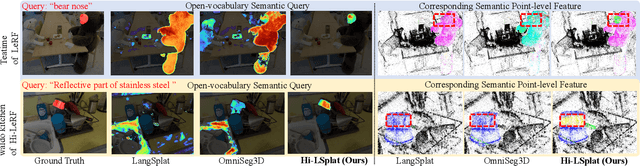
Modeling 3D language fields with Gaussian Splatting for open-ended language queries has recently garnered increasing attention. However, recent 3DGS-based models leverage view-dependent 2D foundation models to refine 3D semantics but lack a unified 3D representation, leading to view inconsistencies. Additionally, inherent open-vocabulary challenges cause inconsistencies in object and relational descriptions, impeding hierarchical semantic understanding. In this paper, we propose Hi-LSplat, a view-consistent Hierarchical Language Gaussian Splatting work for 3D open-vocabulary querying. To achieve view-consistent 3D hierarchical semantics, we first lift 2D features to 3D features by constructing a 3D hierarchical semantic tree with layered instance clustering, which addresses the view inconsistency issue caused by 2D semantic features. Besides, we introduce instance-wise and part-wise contrastive losses to capture all-sided hierarchical semantic representations. Notably, we construct two hierarchical semantic datasets to better assess the model's ability to distinguish different semantic levels. Extensive experiments highlight our method's superiority in 3D open-vocabulary segmentation and localization. Its strong performance on hierarchical semantic datasets underscores its ability to capture complex hierarchical semantics within 3D scenes.
RDG-GS: Relative Depth Guidance with Gaussian Splatting for Real-time Sparse-View 3D Rendering
Jan 19, 2025Efficiently synthesizing novel views from sparse inputs while maintaining accuracy remains a critical challenge in 3D reconstruction. While advanced techniques like radiance fields and 3D Gaussian Splatting achieve rendering quality and impressive efficiency with dense view inputs, they suffer from significant geometric reconstruction errors when applied to sparse input views. Moreover, although recent methods leverage monocular depth estimation to enhance geometric learning, their dependence on single-view estimated depth often leads to view inconsistency issues across different viewpoints. Consequently, this reliance on absolute depth can introduce inaccuracies in geometric information, ultimately compromising the quality of scene reconstruction with Gaussian splats. In this paper, we present RDG-GS, a novel sparse-view 3D rendering framework with Relative Depth Guidance based on 3D Gaussian Splatting. The core innovation lies in utilizing relative depth guidance to refine the Gaussian field, steering it towards view-consistent spatial geometric representations, thereby enabling the reconstruction of accurate geometric structures and capturing intricate textures. First, we devise refined depth priors to rectify the coarse estimated depth and insert global and fine-grained scene information to regular Gaussians. Building on this, to address spatial geometric inaccuracies from absolute depth, we propose relative depth guidance by optimizing the similarity between spatially correlated patches of depth and images. Additionally, we also directly deal with the sparse areas challenging to converge by the adaptive sampling for quick densification. Across extensive experiments on Mip-NeRF360, LLFF, DTU, and Blender, RDG-GS demonstrates state-of-the-art rendering quality and efficiency, making a significant advancement for real-world application.
Agent Security Bench (ASB): Formalizing and Benchmarking Attacks and Defenses in LLM-based Agents
Oct 03, 2024



Although LLM-based agents, powered by Large Language Models (LLMs), can use external tools and memory mechanisms to solve complex real-world tasks, they may also introduce critical security vulnerabilities. However, the existing literature does not comprehensively evaluate attacks and defenses against LLM-based agents. To address this, we introduce Agent Security Bench (ASB), a comprehensive framework designed to formalize, benchmark, and evaluate the attacks and defenses of LLM-based agents, including 10 scenarios (e.g., e-commerce, autonomous driving, finance), 10 agents targeting the scenarios, over 400 tools, 23 different types of attack/defense methods, and 8 evaluation metrics. Based on ASB, we benchmark 10 prompt injection attacks, a memory poisoning attack, a novel Plan-of-Thought backdoor attack, a mixed attack, and 10 corresponding defenses across 13 LLM backbones with nearly 90,000 testing cases in total. Our benchmark results reveal critical vulnerabilities in different stages of agent operation, including system prompt, user prompt handling, tool usage, and memory retrieval, with the highest average attack success rate of 84.30\%, but limited effectiveness shown in current defenses, unveiling important works to be done in terms of agent security for the community. Our code can be found at https://github.com/agiresearch/ASB.
Towards Imperceptible Backdoor Attack in Self-supervised Learning
May 23, 2024
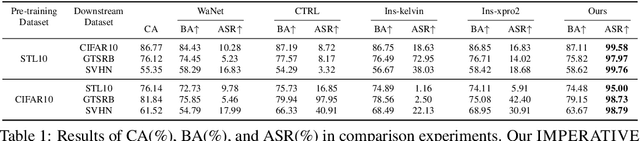


Self-supervised learning models are vulnerable to backdoor attacks. Existing backdoor attacks that are effective in self-supervised learning often involve noticeable triggers, like colored patches, which are vulnerable to human inspection. In this paper, we propose an imperceptible and effective backdoor attack against self-supervised models. We first find that existing imperceptible triggers designed for supervised learning are not as effective in compromising self-supervised models. We then identify this ineffectiveness is attributed to the overlap in distributions between the backdoor and augmented samples used in self-supervised learning. Building on this insight, we design an attack using optimized triggers that are disentangled to the augmented transformation in the self-supervised learning, while also remaining imperceptible to human vision. Experiments on five datasets and seven SSL algorithms demonstrate our attack is highly effective and stealthy. It also has strong resistance to existing backdoor defenses. Our code can be found at https://github.com/Zhang-Henry/IMPERATIVE.
MedM2G: Unifying Medical Multi-Modal Generation via Cross-Guided Diffusion with Visual Invariant
Mar 07, 2024



Medical generative models, acknowledged for their high-quality sample generation ability, have accelerated the fast growth of medical applications. However, recent works concentrate on separate medical generation models for distinct medical tasks and are restricted to inadequate medical multi-modal knowledge, constraining medical comprehensive diagnosis. In this paper, we propose MedM2G, a Medical Multi-Modal Generative framework, with the key innovation to align, extract, and generate medical multi-modal within a unified model. Extending beyond single or two medical modalities, we efficiently align medical multi-modal through the central alignment approach in the unified space. Significantly, our framework extracts valuable clinical knowledge by preserving the medical visual invariant of each imaging modal, thereby enhancing specific medical information for multi-modal generation. By conditioning the adaptive cross-guided parameters into the multi-flow diffusion framework, our model promotes flexible interactions among medical multi-modal for generation. MedM2G is the first medical generative model that unifies medical generation tasks of text-to-image, image-to-text, and unified generation of medical modalities (CT, MRI, X-ray). It performs 5 medical generation tasks across 10 datasets, consistently outperforming various state-of-the-art works.
UniDCP: Unifying Multiple Medical Vision-language Tasks via Dynamic Cross-modal Learnable Prompts
Dec 18, 2023



Medical vision-language pre-training (Med-VLP) models have recently accelerated the fast-growing medical diagnostics application. However, most Med-VLP models learn task-specific representations independently from scratch, thereby leading to great inflexibility when they work across multiple fine-tuning tasks. In this work, we propose UniDCP, a Unified medical vision-language model with Dynamic Cross-modal learnable Prompts, which can be plastically applied to multiple medical vision-language tasks. Specifically, we explicitly construct a unified framework to harmonize diverse inputs from multiple pretraining tasks by leveraging cross-modal prompts for unification, which accordingly can accommodate heterogeneous medical fine-tuning tasks. Furthermore, we conceive a dynamic cross-modal prompt optimizing strategy that optimizes the prompts within the shareable space for implicitly processing the shareable clinic knowledge. UniDCP is the first Med-VLP model capable of performing all 8 medical uni-modal and cross-modal tasks over 14 corresponding datasets, consistently yielding superior results over diverse state-of-the-art methods.
UnICLAM:Contrastive Representation Learning with Adversarial Masking for Unified and Interpretable Medical Vision Question Answering
Dec 23, 2022



Medical Visual Question Answering (Medical-VQA) aims to to answer clinical questions regarding radiology images, assisting doctors with decision-making options. Nevertheless, current Medical-VQA models learn cross-modal representations through residing vision and texture encoders in dual separate spaces, which lead to indirect semantic alignment. In this paper, we propose UnICLAM, a Unified and Interpretable Medical-VQA model through Contrastive Representation Learning with Adversarial Masking. Specifically, to learn an aligned image-text representation, we first establish a unified dual-stream pre-training structure with the gradually soft-parameter sharing strategy. Technically, the proposed strategy learns a constraint for the vision and texture encoders to be close in a same space, which is gradually loosened as the higher number of layers. Moreover, for grasping the unified semantic representation, we extend the adversarial masking data augmentation to the contrastive representation learning of vision and text in a unified manner. Concretely, while the encoder training minimizes the distance between original and masking samples, the adversarial masking module keeps adversarial learning to conversely maximize the distance. Furthermore, we also intuitively take a further exploration to the unified adversarial masking augmentation model, which improves the potential ante-hoc interpretability with remarkable performance and efficiency. Experimental results on VQA-RAD and SLAKE public benchmarks demonstrate that UnICLAM outperforms existing 11 state-of-the-art Medical-VQA models. More importantly, we make an additional discussion about the performance of UnICLAM in diagnosing heart failure, verifying that UnICLAM exhibits superior few-shot adaption performance in practical disease diagnosis.