 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemRec: Collaborative Memory-Augmented Agentic Recommender System
Jan 13, 2026The evolution of recommender systems has shifted preference storage from rating matrices and dense embeddings to semantic memory in the agentic era. Yet existing agents rely on isolated memory, overlooking crucial collaborative signals. Bridging this gap is hindered by the dual challenges of distilling vast graph contexts without overwhelming reasoning agents with cognitive load, and evolving the collaborative memory efficiently without incurring prohibitive computational costs. To address this, we propose MemRec, a framework that architecturally decouples reasoning from memory management to enable efficient collaborative augmentation. MemRec introduces a dedicated, cost-effective LM_Mem to manage a dynamic collaborative memory graph, serving synthesized, high-signal context to a downstream LLM_Rec. The framework operates via a practical pipeline featuring efficient retrieval and cost-effective asynchronous graph propagation that evolves memory in the background. Extensive experiments on four benchmarks demonstrate that MemRec achieves state-of-the-art performance. Furthermore, architectural analysis confirms its flexibility, establishing a new Pareto frontier that balances reasoning quality, cost, and privacy through support for diverse deployments, including local open-source models. Code:https://github.com/rutgerswiselab/memrec and Homepage: https://memrec.weixinchen.com
Vision Matters: Simple Visual Perturbations Can Boost Multimodal Math Reasoning
Jun 11, 2025Despite the rapid progress of multimodal large language models (MLLMs), they have largely overlooked the importance of visual processing. In a simple yet revealing experiment, we interestingly find that language-only models, when provided with image captions, can achieve comparable or even better performance than MLLMs that consume raw visual inputs. This suggests that current MLLMs may generate accurate visual descriptions but fail to effectively integrate them during reasoning. Motivated by this, we propose a simple visual perturbation framework that enhances perceptual robustness without requiring algorithmic modifications or additional training data. Our approach introduces three targeted perturbations: distractor concatenation, dominance-preserving mixup, and random rotation, that can be easily integrated into existing post-training pipelines including SFT, DPO, and GRPO. Through extensive experiments across multiple datasets, we demonstrate consistent improvements in mathematical reasoning performance, with gains comparable to those achieved through algorithmic changes. Additionally, we achieve competitive performance among open-source 7B RL-tuned models by training Qwen2.5-VL-7B with visual perturbation. Through comprehensive ablation studies, we analyze the effectiveness of different perturbation strategies, revealing that each perturbation type contributes uniquely to different aspects of visual reasoning. Our findings highlight the critical role of visual perturbation in multimodal mathematical reasoning: better reasoning begins with better seeing. Our code is available at https://github.com/YutingLi0606/Vision-Matters.
DeSocial: Blockchain-based Decentralized Social Networks
May 28, 2025Web 2.0 social platforms are inherently centralized, with user data and algorithmic decisions controlled by the platform. However, users can only passively receive social predictions without being able to choose the underlying algorithm, which limits personalization. Fortunately, with the emergence of blockchain, users are allowed to choose algorithms that are tailored to their local situation, improving prediction results in a personalized way. In a blockchain environment, each user possesses its own model to perform the social prediction, capturing different perspectives on social interactions. In our work, we propose DeSocial, a decentralized social network learning framework deployed on an Ethereum (ETH) local development chain that integrates distributed data storage, node-level consensus, and user-driven model selection through Ganache. In the first stage, each user leverages DeSocial to evaluate multiple backbone models on their local subgraph. DeSocial coordinates the execution and returns model-wise prediction results, enabling the user to select the most suitable backbone for personalized social prediction. Then, DeSocial uniformly selects several validation nodes that possess the algorithm specified by each user, and aggregates the prediction results by majority voting, to prevent errors caused by any single model's misjudgment. Extensive experiments show that DeSocial has an evident improvement compared to the five classical centralized social network learning models, promoting user empowerment in blockchain-based decentralized social networks, showing the importance of multi-node validation and personalized algorithm selection based on blockchain. Our implementation is available at: https://github.com/agiresearch/DeSocial.
LLM as GNN: Graph Vocabulary Learning for Text-Attributed Graph Foundation Models
Mar 05, 2025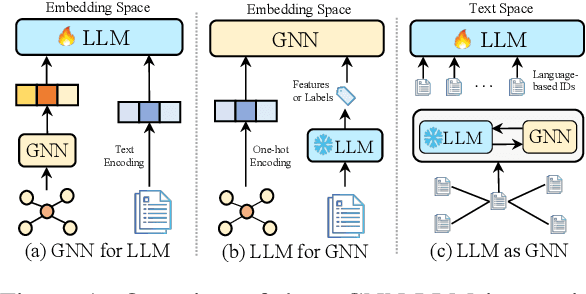
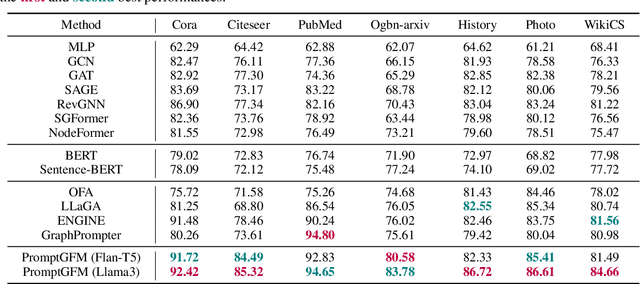
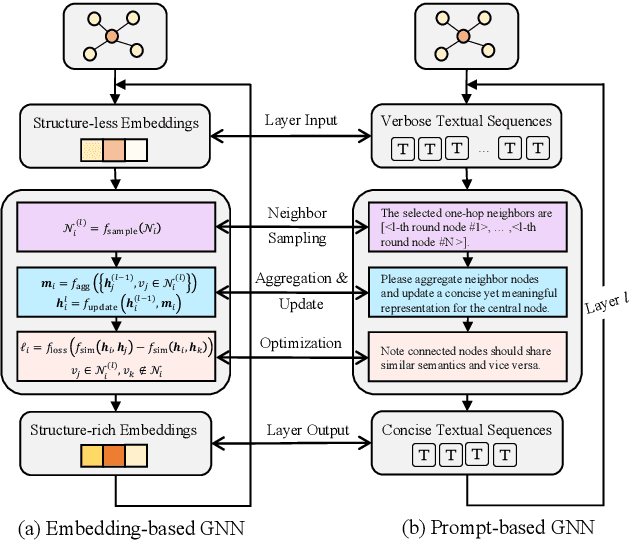
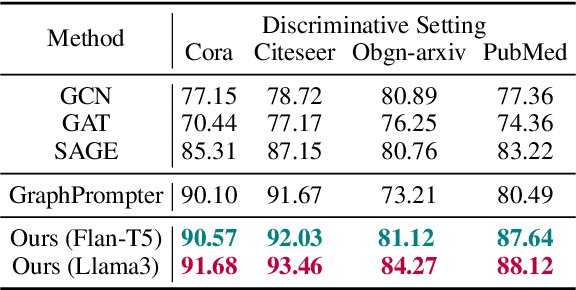
Text-Attributed Graphs (TAGs), where each node is associated with text descriptions, are ubiquitous in real-world scenarios. They typically exhibit distinctive structure and domain-specific knowledge, motivating the development of a Graph Foundation Model (GFM) that generalizes across diverse graphs and tasks. Despite large efforts to integrate Large Language Models (LLMs) and Graph Neural Networks (GNNs) for TAGs, existing approaches suffer from decoupled architectures with two-stage alignment, limiting their synergistic potential. Even worse, existing methods assign out-of-vocabulary (OOV) tokens to graph nodes, leading to graph-specific semantics, token explosion, and incompatibility with task-oriented prompt templates, which hinders cross-graph and cross-task transferability. To address these challenges, we propose PromptGFM, a versatile GFM for TAGs grounded in graph vocabulary learning. PromptGFM comprises two key components: (1) Graph Understanding Module, which explicitly prompts LLMs to replicate the finest GNN workflow within the text space, facilitating seamless GNN-LLM integration and elegant graph-text alignment; (2) Graph Inference Module, which establishes a language-based graph vocabulary ensuring expressiveness, transferability, and scalability, enabling readable instructions for LLM fine-tuning. Extensive experiments demonstrate our superiority and transferability across diverse graphs and tasks. The code is available at this: https://github.com/agiresearch/PromptGFM.
Agent Security Bench (ASB): Formalizing and Benchmarking Attacks and Defenses in LLM-based Agents
Oct 03, 2024



Although LLM-based agents, powered by Large Language Models (LLMs), can use external tools and memory mechanisms to solve complex real-world tasks, they may also introduce critical security vulnerabilities. However, the existing literature does not comprehensively evaluate attacks and defenses against LLM-based agents. To address this, we introduce Agent Security Bench (ASB), a comprehensive framework designed to formalize, benchmark, and evaluate the attacks and defenses of LLM-based agents, including 10 scenarios (e.g., e-commerce, autonomous driving, finance), 10 agents targeting the scenarios, over 400 tools, 23 different types of attack/defense methods, and 8 evaluation metrics. Based on ASB, we benchmark 10 prompt injection attacks, a memory poisoning attack, a novel Plan-of-Thought backdoor attack, a mixed attack, and 10 corresponding defenses across 13 LLM backbones with nearly 90,000 testing cases in total. Our benchmark results reveal critical vulnerabilities in different stages of agent operation, including system prompt, user prompt handling, tool usage, and memory retrieval, with the highest average attack success rate of 84.30\%, but limited effectiveness shown in current defenses, unveiling important works to be done in terms of agent security for the community. Our code can be found at https://github.com/agiresearch/ASB.
Exploring Concept Depth: How Large Language Models Acquire Knowledge at Different Layers?
Apr 10, 2024This paper studies the phenomenon that different concepts are learned in different layers of large language models, i.e. more difficult concepts are fully acquired with deeper layers. We define the difficulty of concepts by the level of abstraction, and here it is crudely categorized by factual, emotional, and inferential. Each category contains a spectrum of tasks, arranged from simple to complex. For example, within the factual dimension, tasks range from lie detection to categorizing mathematical problems. We employ a probing technique to extract representations from different layers of the model and apply these to classification tasks. Our findings reveal that models tend to efficiently classify simpler tasks, indicating that these concepts are learned in shallower layers. Conversely, more complex tasks may only be discernible at deeper layers, if at all. This paper explores the implications of these findings for our understanding of model learning processes and internal representations. Our implementation is available at \url{https://github.com/Luckfort/CD}.
Not All Countries Celebrate Thanksgiving: On the Cultural Dominance in Large Language Models
Oct 19, 2023



In this paper, we identify a cultural dominance issue within large language models (LLMs) due to the predominant use of English data in model training (e.g. ChatGPT). LLMs often provide inappropriate English-culture-related answers that are not relevant to the expected culture when users ask in non-English languages. To systematically evaluate the cultural dominance issue, we build a benchmark that consists of both concrete (e.g. holidays and songs) and abstract (e.g. values and opinions) cultural objects. Empirical results show that the representative GPT models suffer from the culture dominance problem, where GPT-4 is the most affected while text-davinci-003 suffers the least from this problem. Our study emphasizes the need for critical examination of cultural dominance and ethical consideration in their development and deployment. We show two straightforward methods in model development (i.e. pretraining on more diverse data) and deployment (e.g. culture-aware prompting) can significantly mitigate the cultural dominance issue in LLMs.
An Image is Worth a Thousand Toxic Words: A Metamorphic Testing Framework for Content Moderation Software
Aug 18, 2023


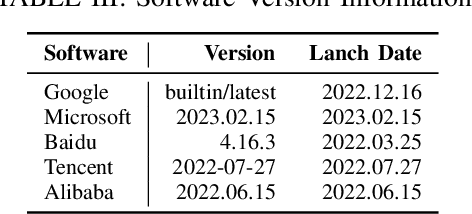
The exponential growth of social media platforms has brought about a revolution in communication and content dissemination in human society. Nevertheless, these platforms are being increasingly misused to spread toxic content, including hate speech, malicious advertising, and pornography, leading to severe negative consequences such as harm to teenagers' mental health. Despite tremendous efforts in developing and deploying textual and image content moderation methods, malicious users can evade moderation by embedding texts into images, such as screenshots of the text, usually with some interference. We find that modern content moderation software's performance against such malicious inputs remains underexplored. In this work, we propose OASIS, a metamorphic testing framework for content moderation software. OASIS employs 21 transform rules summarized from our pilot study on 5,000 real-world toxic contents collected from 4 popular social media applications, including Twitter, Instagram, Sina Weibo, and Baidu Tieba. Given toxic textual contents, OASIS can generate image test cases, which preserve the toxicity yet are likely to bypass moderation. In the evaluation, we employ OASIS to test five commercial textual content moderation software from famous companies (i.e., Google Cloud, Microsoft Azure, Baidu Cloud, Alibaba Cloud and Tencent Cloud), as well as a state-of-the-art moderation research model. The results show that OASIS achieves up to 100% error finding rates. Moreover, through retraining the models with the test cases generated by OASIS, the robustness of the moderation model can be improved without performance degradation.
Validating Multimedia Content Moderation Software via Semantic Fusion
May 23, 2023The exponential growth of social media platforms, such as Facebook and TikTok, has revolutionized communication and content publication in human society. Users on these platforms can publish multimedia content that delivers information via the combination of text, audio, images, and video. Meanwhile, the multimedia content release facility has been increasingly exploited to propagate toxic content, such as hate speech, malicious advertisements, and pornography. To this end, content moderation software has been widely deployed on these platforms to detect and blocks toxic content. However, due to the complexity of content moderation models and the difficulty of understanding information across multiple modalities, existing content moderation software can fail to detect toxic content, which often leads to extremely negative impacts. We introduce Semantic Fusion, a general, effective methodology for validating multimedia content moderation software. Our key idea is to fuse two or more existing single-modal inputs (e.g., a textual sentence and an image) into a new input that combines the semantics of its ancestors in a novel manner and has toxic nature by construction. This fused input is then used for validating multimedia content moderation software. We realized Semantic Fusion as DUO, a practical content moderation software testing tool. In our evaluation, we employ DUO to test five commercial content moderation software and two state-of-the-art models against three kinds of toxic content. The results show that DUO achieves up to 100% error finding rate (EFR) when testing moderation software. In addition, we leverage the test cases generated by DUO to retrain the two models we explored, which largely improves model robustness while maintaining the accuracy on the original test set.