 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision Matters: Simple Visual Perturbations Can Boost Multimodal Math Reasoning
Jun 11, 2025Despite the rapid progress of multimodal large language models (MLLMs), they have largely overlooked the importance of visual processing. In a simple yet revealing experiment, we interestingly find that language-only models, when provided with image captions, can achieve comparable or even better performance than MLLMs that consume raw visual inputs. This suggests that current MLLMs may generate accurate visual descriptions but fail to effectively integrate them during reasoning. Motivated by this, we propose a simple visual perturbation framework that enhances perceptual robustness without requiring algorithmic modifications or additional training data. Our approach introduces three targeted perturbations: distractor concatenation, dominance-preserving mixup, and random rotation, that can be easily integrated into existing post-training pipelines including SFT, DPO, and GRPO. Through extensive experiments across multiple datasets, we demonstrate consistent improvements in mathematical reasoning performance, with gains comparable to those achieved through algorithmic changes. Additionally, we achieve competitive performance among open-source 7B RL-tuned models by training Qwen2.5-VL-7B with visual perturbation. Through comprehensive ablation studies, we analyze the effectiveness of different perturbation strategies, revealing that each perturbation type contributes uniquely to different aspects of visual reasoning. Our findings highlight the critical role of visual perturbation in multimodal mathematical reasoning: better reasoning begins with better seeing. Our code is available at https://github.com/YutingLi0606/Vision-Matters.
Advancing Multimodal Reasoning via Reinforcement Learning with Cold Start
May 28, 2025Recent advancements in large language models (LLMs) have demonstrated impressive chain-of-thought reasoning capabilities, with reinforcement learning (RL) playing a crucial role in this progress. While "aha moment" patterns--where models exhibit self-correction through reflection--are often attributed to emergent properties from RL, we first demonstrate that these patterns exist in multimodal LLMs (MLLMs) prior to RL training but may not necessarily correlate with improved reasoning performance. Building on these insights, we present a comprehensive study on enhancing multimodal reasoning through a two-stage approach: (1) supervised fine-tuning (SFT) as a cold start with structured chain-of-thought reasoning patterns, followed by (2) reinforcement learning via GRPO to further refine these capabilities. Our extensive experiments show that this combined approach consistently outperforms both SFT-only and RL-only methods across challenging multimodal reasoning benchmarks. The resulting models achieve state-of-the-art performance among open-source MLLMs at both 3B and 7B scales, with our 7B model showing substantial improvements over base models (e.g., 66.3 %$\rightarrow$73.4 % on MathVista, 62.9 %$\rightarrow$70.4 % on We-Math) and our 3B model achieving performance competitive with several 7B models. Overall, this work provides practical guidance for building advanced multimodal reasoning models. Our code is available at https://github.com/waltonfuture/RL-with-Cold-Start.
CrystalX: Ultra-Precision Crystal Structure Resolution and Error Correction Using Deep Learning
Oct 17, 2024Atomic structure analysis of crystalline materials is a paramount endeavor in both chemical and material sciences. This sophisticated technique necessitates not only a solid foundation in crystallography but also a profound comprehension of the intricacies of the accompanying software, posing a significant challenge in meeting the rigorous daily demands. For the first time, we confront this challenge head-on by harnessing the power of deep learning for ultra-precise structural analysis at the full-atom level. To validate the performance of the model, named CrystalX, we employed a vast dataset comprising over 50,000 X-ray diffraction measurements derived from authentic experiments, demonstrating performance that is commensurate with human experts and adept at deciphering intricate geometric patterns. Remarkably, CrystalX revealed that even peer-reviewed publications can harbor errors that are stealthy to human scrutiny, yet CrystalX adeptly rectifies them. This deep learning model revolutionizes the time frame for crystal structure analysis, slashing it down to seconds. It has already been successfully applied in the structure analysis of newly discovered compounds in the latest research without human intervention. Overall, CrystalX marks the beginning of a new era in automating routine structural analysis within self-driving laboratories.
Provable Contrastive Continual Learning
May 29, 2024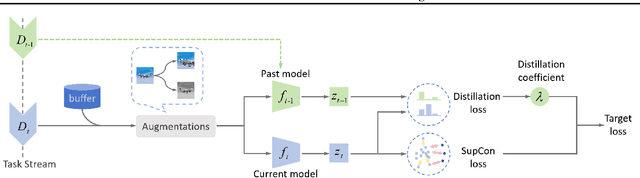


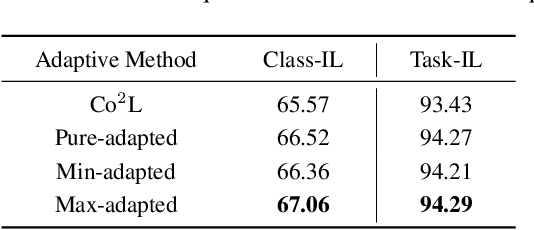
Continual learning requires learning incremental tasks with dynamic data distributions. So far, it has been observed that employing a combination of contrastive loss and distillation loss for training in continual learning yields strong performance. To the best of our knowledge, however, this contrastive continual learning framework lacks convincing theoretical explanations. In this work, we fill this gap by establishing theoretical performance guarantees, which reveal how the performance of the model is bounded by training losses of previous tasks in the contrastive continual learning framework. Our theoretical explanations further support the idea that pre-training can benefit continual learning. Inspired by our theoretical analysis of these guarantees, we propose a novel contrastive continual learning algorithm called CILA, which uses adaptive distillation coefficients for different tasks. These distillation coefficients are easily computed by the ratio between average distillation losses and average contrastive losses from previous tasks. Our method shows great improvement on standard benchmarks and achieves new state-of-the-art performance.
Efficient Few-Shot Clinical Task Adaptation with Large Language Models
Dec 12, 2023Few-shot learning has been studied to adapt models to tasks with very few samples. It holds profound significance, particularly in clinical tasks, due to the high annotation cost of medical images. Several works have explored few-shot learning on medical images, yet they still require a large number of medical images for pre-training models to gain domain-specific priors. Vision foundation models recently have achieved remarkable success in natural images. Hence, adapting rapidly advancing vision foundation models from natural images to few-shot clinical tasks holds great promise. MedFMC has recently organized a challenge to shed more light on this topic at NeurIPS 2023. In this work, we present our challenge solution. We observe that a simple variant of fine-tuning with partial freezing shows remarkable performance. Empirical evidence demonstrates that this approach could outperform various common fine-tuning methods under limited sample sizes. Additionally, we explore enhanced utilization of semantic supervision to boost performance. We propose a novel approach that contextualizes labels via large language models (LLMs). Our findings reveal that the context generated by LLMs significantly enhances the discrimination of semantic embeddings for similar categories, resulting in a notable performance improvement of 3%-5% in 1-shot settings compared to commonly employed one-hot labels and other semantic supervision methods. Our solution secures the 1st place in the MedFMC challenge.
OTMatch: Improving Semi-Supervised Learning with Optimal Transport
Oct 26, 2023Semi-supervised learning has made remarkable strides by effectively utilizing a limited amount of labeled data while capitalizing on the abundant information present in unlabeled data. However, current algorithms often prioritize aligning image predictions with specific classes generated through self-training techniques, thereby neglecting the inherent relationships that exist within these classes. In this paper, we present a new approach called OTMatch, which leverages semantic relationships among classes by employing an optimal transport loss function. By utilizing optimal transport, our proposed method consistently outperforms established state-of-the-art methods. Notably, we observed a substantial improvement of a certain percentage in accuracy compared to the current state-of-the-art method, FreeMatch. OTMatch achieves 3.18%, 3.46%, and 1.28% error rate reduction over FreeMatch on CIFAR-10 with 1 label per class, STL-10 with 4 labels per class, and ImageNet with 100 labels per class, respectively. This demonstrates the effectiveness and superiority of our approach in harnessing semantic relationships to enhance learning performance in a semi-supervised setting.
DiffKendall: A Novel Approach for Few-Shot Learning with Differentiable Kendall's Rank Correlation
Jul 28, 2023



Few-shot learning aims to adapt models trained on the base dataset to novel tasks where the categories are not seen by the model before. This often leads to a relatively uniform distribution of feature values across channels on novel classes, posing challenges in determining channel importance for novel tasks. Standard few-shot learning methods employ geometric similarity metrics such as cosine similarity and negative Euclidean distance to gauge the semantic relatedness between two features. However, features with high geometric similarities may carry distinct semantics, especially in the context of few-shot learning. In this paper, we demonstrate that the importance ranking of feature channels is a more reliable indicator for few-shot learning than geometric similarity metrics. We observe that replacing the geometric similarity metric with Kendall's rank correlation only during inference is able to improve the performance of few-shot learning across a wide range of datasets with different domains. Furthermore, we propose a carefully designed differentiable loss for meta-training to address the non-differentiability issue of Kendall's rank correlation. Extensive experiments demonstrate that the proposed rank-correlation-based approach substantially enhances few-shot learning performance.