 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient and Universal Neural-Network Decoder for Stabilizer-Based Quantum Error Correction
Feb 27, 2025



Quantum error correction is crucial for large-scale quantum computing, but the absence of efficient decoders for new codes like quantum low-density parity-check (QLDPC) codes has hindered progress. Here we introduce a universal decoder based on linear attention sequence modeling and graph neural network that operates directly on any stabilizer code's graph structure. Our numerical experiments demonstrate that this decoder outperforms specialized algorithms in both accuracy and speed across diverse stabilizer codes, including surface codes, color codes, and QLDPC codes. The decoder maintains linear time scaling with syndrome measurements and requires no structural modifications between different codes. For the Bivariate Bicycle code with distance 12, our approach achieves a 39.4% lower logical error rate than previous best decoders while requiring only ~1% of the decoding time. These results provide a practical, universal solution for quantum error correction, eliminating the need for code-specific decoders.
CrystalX: Ultra-Precision Crystal Structure Resolution and Error Correction Using Deep Learning
Oct 17, 2024Atomic structure analysis of crystalline materials is a paramount endeavor in both chemical and material sciences. This sophisticated technique necessitates not only a solid foundation in crystallography but also a profound comprehension of the intricacies of the accompanying software, posing a significant challenge in meeting the rigorous daily demands. For the first time, we confront this challenge head-on by harnessing the power of deep learning for ultra-precise structural analysis at the full-atom level. To validate the performance of the model, named CrystalX, we employed a vast dataset comprising over 50,000 X-ray diffraction measurements derived from authentic experiments, demonstrating performance that is commensurate with human experts and adept at deciphering intricate geometric patterns. Remarkably, CrystalX revealed that even peer-reviewed publications can harbor errors that are stealthy to human scrutiny, yet CrystalX adeptly rectifies them. This deep learning model revolutionizes the time frame for crystal structure analysis, slashing it down to seconds. It has already been successfully applied in the structure analysis of newly discovered compounds in the latest research without human intervention. Overall, CrystalX marks the beginning of a new era in automating routine structural analysis within self-driving laboratories.
Iterative Length-Regularized Direct Preference Optimization: A Case Study on Improving 7B Language Models to GPT-4 Level
Jun 17, 2024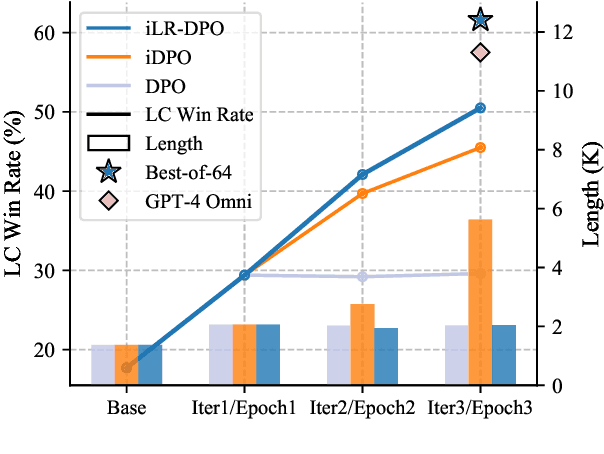
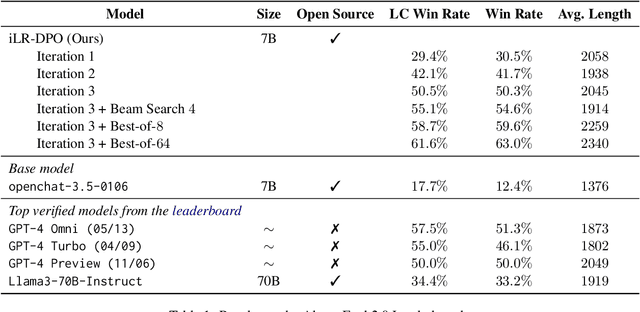
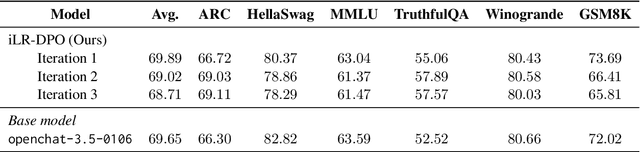
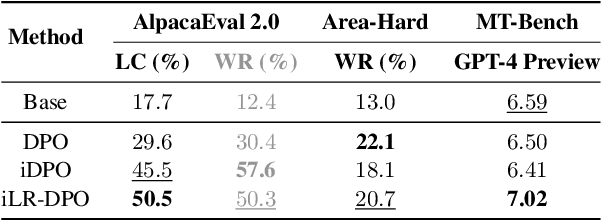
Direct Preference Optimization (DPO), a standard method for aligning language models with human preferences, is traditionally applied to offline preferences. Recent studies show that DPO benefits from iterative training with online preferences labeled by a trained reward model. In this work, we identify a pitfall of vanilla iterative DPO - improved response quality can lead to increased verbosity. To address this, we introduce iterative length-regularized DPO (iLR-DPO) to penalize response length. Our empirical results show that iLR-DPO can enhance a 7B model to perform on par with GPT-4 without increasing verbosity. Specifically, our 7B model achieves a $50.5\%$ length-controlled win rate against $\texttt{GPT-4 Preview}$ on AlpacaEval 2.0, and excels across standard benchmarks including MT-Bench, Arena-Hard and OpenLLM Leaderboard. These results demonstrate the effectiveness of iterative DPO in aligning language models with human feedback.
DocReLM: Mastering Document Retrieval with Language Model
May 19, 2024With over 200 million published academic documents and millions of new documents being written each year, academic researchers face the challenge of searching for information within this vast corpus. However, existing retrieval systems struggle to understand the semantics and domain knowledge present in academic papers. In this work, we demonstrate that by utilizing large language models, a document retrieval system can achieve advanced semantic understanding capabilities, significantly outperforming existing systems. Our approach involves training the retriever and reranker using domain-specific data generated by large language models. Additionally, we utilize large language models to identify candidates from the references of retrieved papers to further enhance the performance. We use a test set annotated by academic researchers in the fields of quantum physics and computer vision to evaluate our system's performance. The results show that DocReLM achieves a Top 10 accuracy of 44.12% in computer vision, compared to Google Scholar's 15.69%, and an increase to 36.21% in quantum physics, while that of Google Scholar is 12.96%.
LOCR: Location-Guided Transformer for Optical Character Recognition
Mar 04, 2024Academic documents are packed with texts, equations, tables, and figures, requiring comprehensive understanding for accurate Optical Character Recognition (OCR). While end-to-end OCR methods offer improved accuracy over layout-based approaches, they often grapple with significant repetition issues, especially with complex layouts in Out-Of-Domain (OOD) documents.To tackle this issue, we propose LOCR, a model that integrates location guiding into the transformer architecture during autoregression. We train the model on a dataset comprising over 77M text-location pairs from 125K academic document pages, including bounding boxes for words, tables and mathematical symbols. LOCR adeptly handles various formatting elements and generates content in Markdown language. It outperforms all existing methods in our test set constructed from arXiv, as measured by edit distance, BLEU, METEOR and F-measure.LOCR also reduces repetition frequency from 4.4% of pages to 0.5% in the arXiv dataset, from 13.2% to 1.3% in OOD quantum physics documents and from 8.1% to 1.8% in OOD marketing documents. Additionally, LOCR features an interactive OCR mode, facilitating the generation of complex documents through a few location prompts from human.