 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Horizontal Layering to Vertical Integration: A Comparative Study of the AI-Driven Software Development Paradigm
Jan 30, 2026This paper examines the organizational implications of Generative AI adoption in software engineering through a multiple-case comparative study. We contrast two development environments: a traditional enterprise (brownfield) and an AI-native startup (greenfield). Our analysis reveals that transitioning from Horizontal Layering (functional specialization) to Vertical Integration (end-to-end ownership) yields 8-fold to 33-fold reductions in resource consumption. We attribute these gains to the emergence of Super Employees, AI-augmented engineers who span traditional role boundaries, and the elimination of inter-functional coordination overhead. Theoretically, we propose Human-AI Collaboration Efficacy as the primary optimization target for engineering organizations, supplanting individual productivity metrics. Our Total Factor Productivity analysis identifies an AI Distortion Effect that diminishes returns to labor scale while amplifying technological leverage. We conclude with managerial strategies for organizational redesign, including the reactivation of idle cognitive bandwidth in senior engineers and the suppression of blind scale expansion.
Modeling Cascaded Delay Feedback for Online Net Conversion Rate Prediction: Benchmark, Insights and Solutions
Jan 29, 2026In industrial recommender systems, conversion rate (CVR) is widely used for traffic allocation, but it fails to fully reflect recommendation effectiveness because it ignores refund behavior. To better capture true user satisfaction and business value, net conversion rate (NetCVR), defined as the probability that a clicked item is purchased and not refunded, has been proposed.Unlike CVR, NetCVR prediction involves a more complex multi-stage cascaded delayed feedback process. The two cascaded delays from click to conversion and from conversion to refund have opposite effects, making traditional CVR modeling methods inapplicable. Moreover, the lack of open-source datasets and online continuous training schemes further hinders progress in this area.To address these challenges, we introduce CASCADE (Cascaded Sequences of Conversion and Delayed Refund), the first large-scale open dataset derived from the Taobao app for online continuous NetCVR prediction. Through an in-depth analysis of CASCADE, we identify three key insights: (1) NetCVR exhibits strong temporal dynamics, necessitating online continuous modeling; (2) cascaded modeling of CVR and refund rate outperforms direct NetCVR modeling; and (3) delay time, which correlates with both CVR and refund rate, is an important feature for NetCVR prediction.Based on these insights, we propose TESLA, a continuous NetCVR modeling framework featuring a CVR-refund-rate cascaded architecture, stage-wise debiasing, and a delay-time-aware ranking loss. Extensive experiments demonstrate that TESLA consistently outperforms state-of-the-art methods on CASCADE, achieving absolute improvements of 12.41 percent in RI-AUC and 14.94 percent in RI-PRAUC on NetCVR prediction. The code and dataset are publicly available at https://github.com/alimama-tech/NetCVR.
Efficient Token Pruning for LLaDA-V
Jan 28, 2026Diffusion-based large multimodal models, such as LLaDA-V, have demonstrated impressive capabilities in vision-language understanding and generation. However, their bidirectional attention mechanism and diffusion-style iterative denoising paradigm introduce significant computational overhead, as visual tokens are repeatedly processed across all layers and denoising steps. In this work, we conduct an in-depth attention analysis and reveal that, unlike autoregressive decoders, LLaDA-V aggregates cross-modal information predominantly in middle-to-late layers, leading to delayed semantic alignment. Motivated by this observation, we propose a structured token pruning strategy inspired by FastV, selectively removing a proportion of visual tokens at designated layers to reduce FLOPs while preserving critical semantic information. To the best of our knowledge, this is the first work to investigate structured token pruning in diffusion-based large multimodal models. Unlike FastV, which focuses on shallow-layer pruning, our method targets the middle-to-late layers of the first denoising step to align with LLaDA-V's delayed attention aggregation to maintain output quality, and the first-step pruning strategy reduces the computation across all subsequent steps. Our framework provides an empirical basis for efficient LLaDA-V inference and highlights the potential of vision-aware pruning in diffusion-based multimodal models. Across multiple benchmarks, our best configuration reduces computational cost by up to 65% while preserving an average of 95% task performance.
Delayed Feedback Modeling for Post-Click Gross Merchandise Volume Prediction: Benchmark, Insights and Approaches
Jan 28, 2026The prediction objectives of online advertisement ranking models are evolving from probabilistic metrics like conversion rate (CVR) to numerical business metrics like post-click gross merchandise volume (GMV). Unlike the well-studied delayed feedback problem in CVR prediction, delayed feedback modeling for GMV prediction remains unexplored and poses greater challenges, as GMV is a continuous target, and a single click can lead to multiple purchases that cumulatively form the label. To bridge the research gap, we establish TRACE, a GMV prediction benchmark containing complete transaction sequences rising from each user click, which supports delayed feedback modeling in an online streaming manner. Our analysis and exploratory experiments on TRACE reveal two key insights: (1) the rapid evolution of the GMV label distribution necessitates modeling delayed feedback under online streaming training; (2) the label distribution of repurchase samples substantially differs from that of single-purchase samples, highlighting the need for separate modeling. Motivated by these findings, we propose RepurchasE-Aware Dual-branch prEdictoR (READER), a novel GMV modeling paradigm that selectively activates expert parameters according to repurchase predictions produced by a router. Moreover, READER dynamically calibrates the regression target to mitigate under-estimation caused by incomplete labels. Experimental results show that READER yields superior performance on TRACE over baselines, achieving a 2.19% improvement in terms of accuracy. We believe that our study will open up a new avenue for studying online delayed feedback modeling for GMV prediction, and our TRACE benchmark with the gathered insights will facilitate future research and application in this promising direction. Our code and dataset are available at https://github.com/alimama-tech/OnlineGMV .
From Prefix Cache to Fusion RAG Cache: Accelerating LLM Inference in Retrieval-Augmented Generation
Jan 19, 2026Retrieval-Augmented Generation enhances Large Language Models by integrating external knowledge, which reduces hallucinations but increases prompt length. This increase leads to higher computational costs and longer Time to First Token (TTFT). To mitigate this issue, existing solutions aim to reuse the preprocessed KV cache of each retrieved chunk to accelerate RAG. However, the lack of cross-chunk contextual information leads to a significant drop in generation quality, leaving the potential benefits of KV cache reuse largely unfulfilled. The challenge lies in how to reuse the precomputed KV cache of chunks while preserving generation quality. We propose FusionRAG, a novel inference framework that optimizes both the preprocessing and reprocessing stages of RAG. In the offline preprocessing stage, we embed information from other related text chunks into each chunk, while in the online reprocessing stage, we recompute the KV cache for tokens that the model focuses on. As a result, we achieve a better trade-off between generation quality and efficiency. According to our experiments, FusionRAG significantly improves generation quality at the same recomputation ratio compared to previous state-of-the-art solutions. By recomputing fewer than 15% of the tokens, FusionRAG achieves up to 70% higher normalized F1 scores than baselines and reduces TTFT by 2.66x-9.39x compared to Full Attention.
QianfanHuijin Technical Report: A Novel Multi-Stage Training Paradigm for Finance Industrial LLMs
Dec 30, 2025Domain-specific enhancement of Large Language Models (LLMs) within the financial context has long been a focal point of industrial application. While previous models such as BloombergGPT and Baichuan-Finance primarily focused on knowledge enhancement, the deepening complexity of financial services has driven a growing demand for models that possess not only domain knowledge but also robust financial reasoning and agentic capabilities. In this paper, we present QianfanHuijin, a financial domain LLM, and propose a generalizable multi-stage training paradigm for industrial model enhancement. Our approach begins with Continual Pre-training (CPT) on financial corpora to consolidate the knowledge base. This is followed by a fine-grained Post-training pipeline designed with increasing specificity: starting with Financial SFT, progressing to Finance Reasoning RL and Finance Agentic RL, and culminating in General RL aligned with real-world business scenarios. Empirical results demonstrate that QianfanHuijin achieves superior performance across various authoritative financial benchmarks. Furthermore, ablation studies confirm that the targeted Reasoning RL and Agentic RL stages yield significant gains in their respective capabilities. These findings validate our motivation and suggest that this fine-grained, progressive post-training methodology is poised to become a mainstream paradigm for various industrial-enhanced LLMs.
Revisiting the Broken Symmetry Phase of Solid Hydrogen: A Neural Network Variational Monte Carlo Study
Dec 19, 2025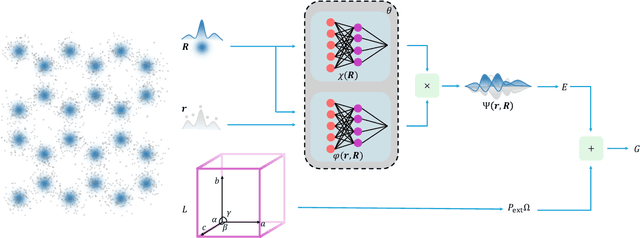
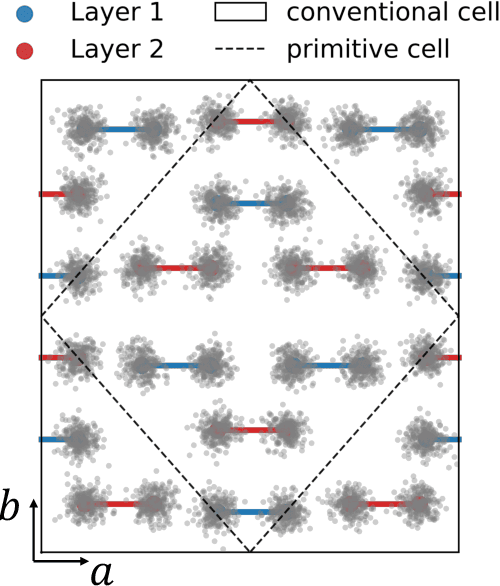
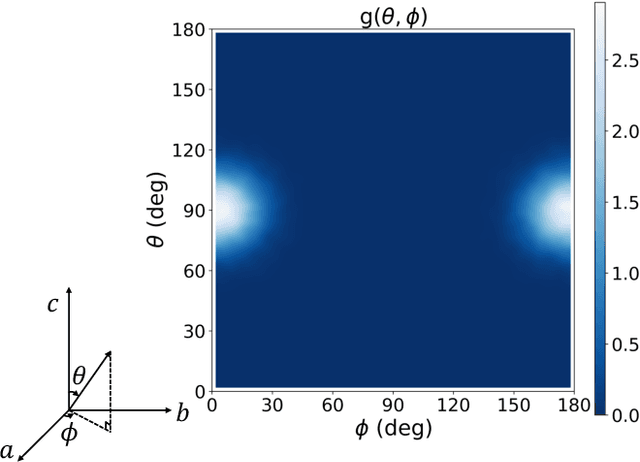
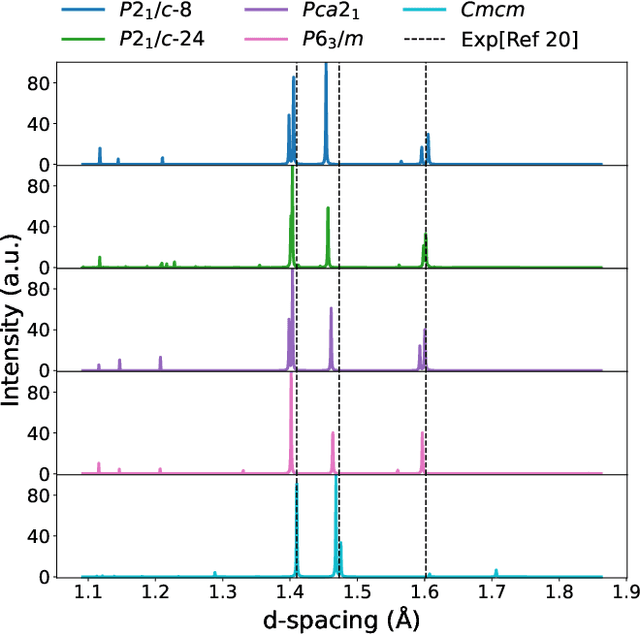
The crystal structure of high-pressure solid hydrogen remains a fundamental open problem. Although the research frontier has mostly shifted toward ultra-high pressure phases above 400 GPa, we show that even the broken symmetry phase observed around 130~GPa requires revisiting due to its intricate coupling of electronic and nuclear degrees of freedom. Here, we develop a first principle quantum Monte Carlo framework based on a deep neural network wave function that treats both electrons and nuclei quantum mechanically within the constant pressure ensemble. Our calculations reveal an unreported ground-state structure candidate for the broken symmetry phase with $Cmcm$ space group symmetry, and we test its stability up to 96 atoms. The predicted structure quantitatively matches the experimental equation of state and X-ray diffraction patterns. Furthermore, our group-theoretical analysis shows that the $Cmcm$ structure is compatible with existing Raman and infrared spectroscopic data. Crucially, static density functional theory calculation reveals the $Cmcm$ structure as a dynamically unstable saddle point on the Born-Oppenheimer potential energy surface, demonstrating that a full quantum many-body treatment of the problem is necessary. These results shed new light on the phase diagram of high-pressure hydrogen and call for further experimental verifications.
HiCaM: A Hierarchical-Causal Modification Framework for Long-Form Text Modification
May 30, 2025Large Language Models (LLMs) have achieved remarkable success in various domains. However, when handling long-form text modification tasks, they still face two major problems: (1) producing undesired modifications by inappropriately altering or summarizing irrelevant content, and (2) missing necessary modifications to implicitly related passages that are crucial for maintaining document coherence. To address these issues, we propose HiCaM, a Hierarchical-Causal Modification framework that operates through a hierarchical summary tree and a causal graph. Furthermore, to evaluate HiCaM, we derive a multi-domain dataset from various benchmarks, providing a resource for assessing its effectiveness. Comprehensive evaluations on the dataset demonstrate significant improvements over strong LLMs, with our method achieving up to a 79.50\% win rate. These results highlight the comprehensiveness of our approach, showing consistent performance improvements across multiple models and domains.
Generalized Category Discovery in Event-Centric Contexts: Latent Pattern Mining with LLMs
May 29, 2025Generalized Category Discovery (GCD) aims to classify both known and novel categories using partially labeled data that contains only known classes. Despite achieving strong performance on existing benchmarks, current textual GCD methods lack sufficient validation in realistic settings. We introduce Event-Centric GCD (EC-GCD), characterized by long, complex narratives and highly imbalanced class distributions, posing two main challenges: (1) divergent clustering versus classification groupings caused by subjective criteria, and (2) Unfair alignment for minority classes. To tackle these, we propose PaMA, a framework leveraging LLMs to extract and refine event patterns for improved cluster-class alignment. Additionally, a ranking-filtering-mining pipeline ensures balanced representation of prototypes across imbalanced categories. Evaluations on two EC-GCD benchmarks, including a newly constructed Scam Report dataset, demonstrate that PaMA outperforms prior methods with up to 12.58% H-score gains, while maintaining strong generalization on base GCD datasets.
An LLM-enabled Multi-Agent Autonomous Mechatronics Design Framework
Apr 20, 2025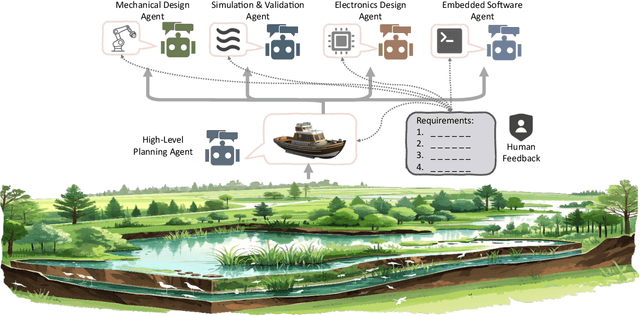

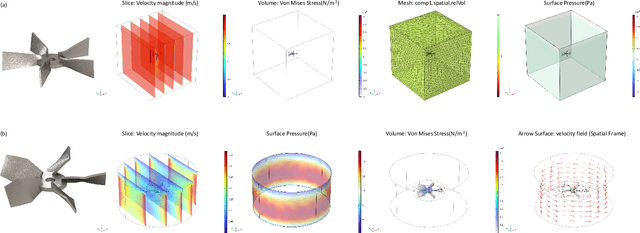
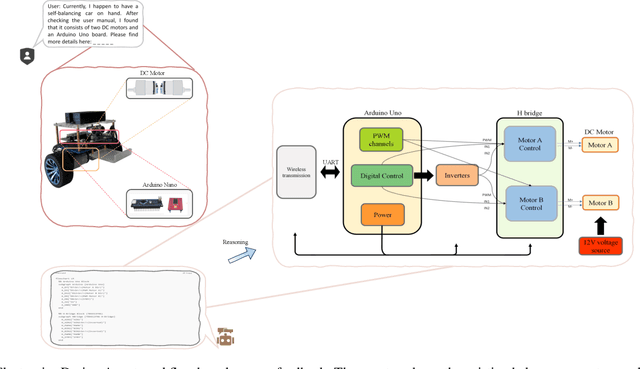
Existing LLM-enabled multi-agent frameworks are predominantly limited to digital or simulated environments and confined to narrowly focused knowledge domain, constraining their applicability to complex engineering tasks that require the design of physical embodiment, cross-disciplinary integration, and constraint-aware reasoning. This work proposes a multi-agent autonomous mechatronics design framework, integrating expertise across mechanical design, optimization, electronics, and software engineering to autonomously generate functional prototypes with minimal direct human design input. Operating primarily through a language-driven workflow, the framework incorporates structured human feedback to ensure robust performance under real-world constraints. To validate its capabilities, the framework is applied to a real-world challenge involving autonomous water-quality monitoring and sampling, where traditional methods are labor-intensive and ecologically disruptive. Leveraging the proposed system, a fully functional autonomous vessel was developed with optimized propulsion, cost-effective electronics, and advanced control. The design process was carried out by specialized agents, including a high-level planning agent responsible for problem abstraction and dedicated agents for structural, electronics, control, and software development. This approach demonstrates the potential of LLM-based multi-agent systems to automate real-world engineering workflows and reduce reliance on extensive domain expertise.