 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDocReLM: Mastering Document Retrieval with Language Model
May 19, 2024With over 200 million published academic documents and millions of new documents being written each year, academic researchers face the challenge of searching for information within this vast corpus. However, existing retrieval systems struggle to understand the semantics and domain knowledge present in academic papers. In this work, we demonstrate that by utilizing large language models, a document retrieval system can achieve advanced semantic understanding capabilities, significantly outperforming existing systems. Our approach involves training the retriever and reranker using domain-specific data generated by large language models. Additionally, we utilize large language models to identify candidates from the references of retrieved papers to further enhance the performance. We use a test set annotated by academic researchers in the fields of quantum physics and computer vision to evaluate our system's performance. The results show that DocReLM achieves a Top 10 accuracy of 44.12% in computer vision, compared to Google Scholar's 15.69%, and an increase to 36.21% in quantum physics, while that of Google Scholar is 12.96%.
Self-consistent Validation for Machine Learning Electronic Structure
Feb 15, 2024Machine learning has emerged as a significant approach to efficiently tackle electronic structure problems. Despite its potential, there is less guarantee for the model to generalize to unseen data that hinders its application in real-world scenarios. To address this issue, a technique has been proposed to estimate the accuracy of the predictions. This method integrates machine learning with self-consistent field methods to achieve both low validation cost and interpret-ability. This, in turn, enables exploration of the model's ability with active learning and instills confidence in its integration into real-world studies.
Rethinking Semi-Supervised Imbalanced Node Classification from Bias-Variance Decomposition
Oct 28, 2023


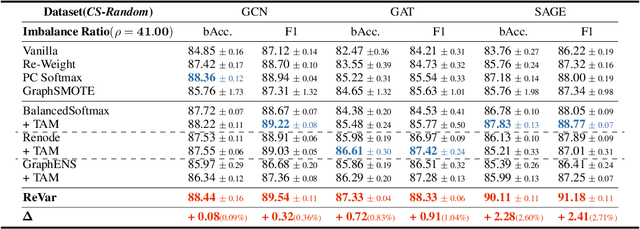
This paper introduces a new approach to address the issue of class imbalance in graph neural networks (GNNs) for learning on graph-structured data. Our approach integrates imbalanced node classification and Bias-Variance Decomposition, establishing a theoretical framework that closely relates data imbalance to model variance. We also leverage graph augmentation technique to estimate the variance, and design a regularization term to alleviate the impact of imbalance. Exhaustive tests are conducted on multiple benchmarks, including naturally imbalanced datasets and public-split class-imbalanced datasets, demonstrating that our approach outperforms state-of-the-art methods in various imbalanced scenarios. This work provides a novel theoretical perspective for addressing the problem of imbalanced node classification in GNNs.