 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIt's a TRAP! Task-Redirecting Agent Persuasion Benchmark for Web Agents
Dec 29, 2025Web-based agents powered by large language models are increasingly used for tasks such as email management or professional networking. Their reliance on dynamic web content, however, makes them vulnerable to prompt injection attacks: adversarial instructions hidden in interface elements that persuade the agent to divert from its original task. We introduce the Task-Redirecting Agent Persuasion Benchmark (TRAP), an evaluation for studying how persuasion techniques misguide autonomous web agents on realistic tasks. Across six frontier models, agents are susceptible to prompt injection in 25\% of tasks on average (13\% for GPT-5 to 43\% for DeepSeek-R1), with small interface or contextual changes often doubling success rates and revealing systemic, psychologically driven vulnerabilities in web-based agents. We also provide a modular social-engineering injection framework with controlled experiments on high-fidelity website clones, allowing for further benchmark expansion.
MOSEv2: A More Challenging Dataset for Video Object Segmentation in Complex Scenes
Aug 07, 2025Video object segmentation (VOS) aims to segment specified target objects throughout a video. Although state-of-the-art methods have achieved impressive performance (e.g., 90+% J&F) on existing benchmarks such as DAVIS and YouTube-VOS, these datasets primarily contain salient, dominant, and isolated objects, limiting their generalization to real-world scenarios. To advance VOS toward more realistic environments, coMplex video Object SEgmentation (MOSEv1) was introduced to facilitate VOS research in complex scenes. Building on the strengths and limitations of MOSEv1, we present MOSEv2, a significantly more challenging dataset designed to further advance VOS methods under real-world conditions. MOSEv2 consists of 5,024 videos and over 701,976 high-quality masks for 10,074 objects across 200 categories. Compared to its predecessor, MOSEv2 introduces significantly greater scene complexity, including more frequent object disappearance and reappearance, severe occlusions and crowding, smaller objects, as well as a range of new challenges such as adverse weather (e.g., rain, snow, fog), low-light scenes (e.g., nighttime, underwater), multi-shot sequences, camouflaged objects, non-physical targets (e.g., shadows, reflections), scenarios requiring external knowledge, etc. We benchmark 20 representative VOS methods under 5 different settings and observe consistent performance drops. For example, SAM2 drops from 76.4% on MOSEv1 to only 50.9% on MOSEv2. We further evaluate 9 video object tracking methods and find similar declines, demonstrating that MOSEv2 presents challenges across tasks. These results highlight that despite high accuracy on existing datasets, current VOS methods still struggle under real-world complexities. MOSEv2 is publicly available at https://MOSE.video.
Dynamic Context-oriented Decomposition for Task-aware Low-rank Adaptation with Less Forgetting and Faster Convergence
Jun 16, 2025



Conventional low-rank adaptation methods build adapters without considering data context, leading to sub-optimal fine-tuning performance and severe forgetting of inherent world knowledge. In this paper, we propose context-oriented decomposition adaptation (CorDA), a novel method that initializes adapters in a task-aware manner. Concretely, we develop context-oriented singular value decomposition, where we collect covariance matrices of input activations for each linear layer using sampled data from the target task, and apply SVD to the product of weight matrix and its corresponding covariance matrix. By doing so, the task-specific capability is compacted into the principal components. Thanks to the task awareness, our method enables two optional adaptation modes, knowledge-preserved mode (KPM) and instruction-previewed mode (IPM), providing flexibility to choose between freezing the principal components to preserve their associated knowledge or adapting them to better learn a new task. We further develop CorDA++ by deriving a metric that reflects the compactness of task-specific principal components, and then introducing dynamic covariance selection and dynamic rank allocation strategies based on the same metric. The two strategies provide each layer with the most representative covariance matrix and a proper rank allocation. Experimental results show that CorDA++ outperforms CorDA by a significant margin. CorDA++ in KPM not only achieves better fine-tuning performance than LoRA, but also mitigates the forgetting of pre-trained knowledge in both large language models and vision language models. For IPM, our method exhibits faster convergence, \emph{e.g.,} 4.5x speedup over QLoRA, and improves adaptation performance in various scenarios, outperforming strong baseline methods. Our method has been integrated into the PEFT library developed by Hugging Face.
Simplifying Graph Transformers
Apr 17, 2025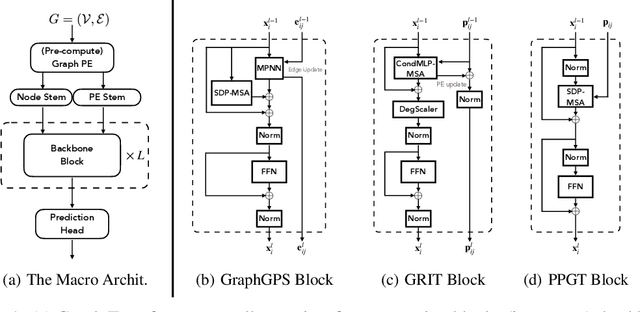
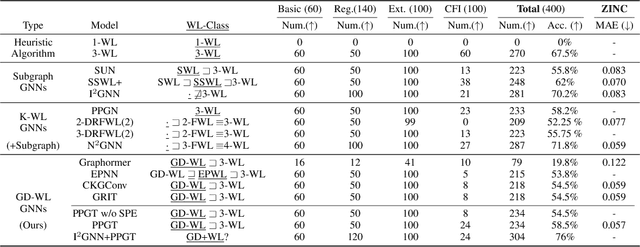
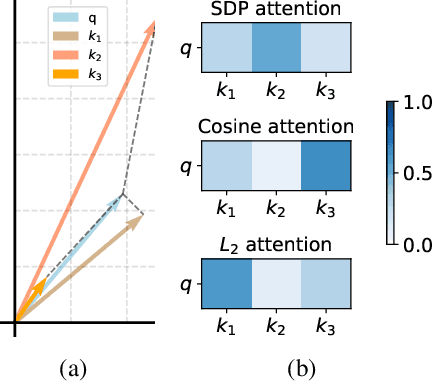
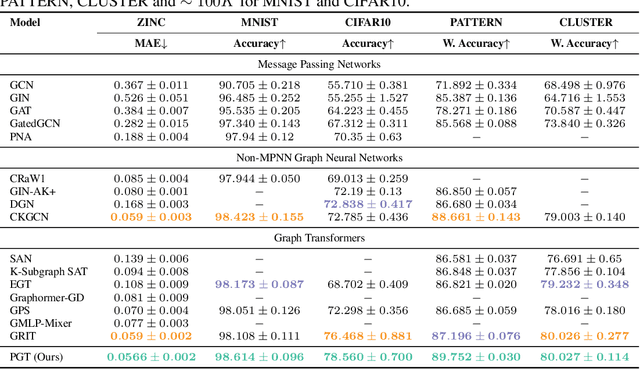
Transformers have attained outstanding performance across various modalities, employing scaled-dot-product (SDP) attention mechanisms. Researchers have attempted to migrate Transformers to graph learning, but most advanced Graph Transformers are designed with major architectural differences, either integrating message-passing or incorporating sophisticated attention mechanisms. These complexities prevent the easy adoption of Transformer training advances. We propose three simple modifications to the plain Transformer to render it applicable to graphs without introducing major architectural distortions. Specifically, we advocate for the use of (1) simplified $L_2$ attention to measure the magnitude closeness of tokens; (2) adaptive root-mean-square normalization to preserve token magnitude information; and (3) a relative positional encoding bias with a shared encoder. Significant performance gains across a variety of graph datasets justify the effectiveness of our proposed modifications. Furthermore, empirical evaluation on the expressiveness benchmark reveals noteworthy realized expressiveness in the graph isomorphism.
Shh, don't say that! Domain Certification in LLMs
Feb 26, 2025Large language models (LLMs) are often deployed to perform constrained tasks, with narrow domains. For example, customer support bots can be built on top of LLMs, relying on their broad language understanding and capabilities to enhance performance. However, these LLMs are adversarially susceptible, potentially generating outputs outside the intended domain. To formalize, assess, and mitigate this risk, we introduce domain certification; a guarantee that accurately characterizes the out-of-domain behavior of language models. We then propose a simple yet effective approach, which we call VALID that provides adversarial bounds as a certificate. Finally, we evaluate our method across a diverse set of datasets, demonstrating that it yields meaningful certificates, which bound the probability of out-of-domain samples tightly with minimum penalty to refusal behavior.
* 10 pages, includes appendix Published in International Conference on Learning Representations (ICLR) 2025
On the Coexistence and Ensembling of Watermarks
Jan 29, 2025



Watermarking, the practice of embedding imperceptible information into media such as images, videos, audio, and text, is essential for intellectual property protection, content provenance and attribution. The growing complexity of digital ecosystems necessitates watermarks for different uses to be embedded in the same media. However, to detect and decode all watermarks, they need to coexist well with one another. We perform the first study of coexistence of deep image watermarking methods and, contrary to intuition, we find that various open-source watermarks can coexist with only minor impacts on image quality and decoding robustness. The coexistence of watermarks also opens the avenue for ensembling watermarking methods. We show how ensembling can increase the overall message capacity and enable new trade-offs between capacity, accuracy, robustness and image quality, without needing to retrain the base models.
4D Gaussian Splatting: Modeling Dynamic Scenes with Native 4D Primitives
Dec 30, 2024



Dynamic 3D scene representation and novel view synthesis from captured videos are crucial for enabling immersive experiences required by AR/VR and metaverse applications. However, this task is challenging due to the complexity of unconstrained real-world scenes and their temporal dynamics. In this paper, we frame dynamic scenes as a spatio-temporal 4D volume learning problem, offering a native explicit reformulation with minimal assumptions about motion, which serves as a versatile dynamic scene learning framework. Specifically, we represent a target dynamic scene using a collection of 4D Gaussian primitives with explicit geometry and appearance features, dubbed as 4D Gaussian splatting (4DGS). This approach can capture relevant information in space and time by fitting the underlying spatio-temporal volume. Modeling the spacetime as a whole with 4D Gaussians parameterized by anisotropic ellipses that can rotate arbitrarily in space and time, our model can naturally learn view-dependent and time-evolved appearance with 4D spherindrical harmonics. Notably, our 4DGS model is the first solution that supports real-time rendering of high-resolution, photorealistic novel views for complex dynamic scenes. To enhance efficiency, we derive several compact variants that effectively reduce memory footprint and mitigate the risk of overfitting. Extensive experiments validate the superiority of 4DGS in terms of visual quality and efficiency across a range of dynamic scene-related tasks (e.g., novel view synthesis, 4D generation, scene understanding) and scenarios (e.g., single object, indoor scenes, driving environments, synthetic and real data).
Olympus: A Universal Task Router for Computer Vision Tasks
Dec 12, 2024We introduce Olympus, a new approach that transforms Multimodal Large Language Models (MLLMs) into a unified framework capable of handling a wide array of computer vision tasks. Utilizing a controller MLLM, Olympus delegates over 20 specialized tasks across images, videos, and 3D objects to dedicated modules. This instruction-based routing enables complex workflows through chained actions without the need for training heavy generative models. Olympus easily integrates with existing MLLMs, expanding their capabilities with comparable performance. Experimental results demonstrate that Olympus achieves an average routing accuracy of 94.75% across 20 tasks and precision of 91.82% in chained action scenarios, showcasing its effectiveness as a universal task router that can solve a diverse range of computer vision tasks. Project page: https://github.com/yuanze-lin/Olympus_page
MALT: Improving Reasoning with Multi-Agent LLM Training
Dec 02, 2024


Enabling effective collaboration among LLMs is a crucial step toward developing autonomous systems capable of solving complex problems. While LLMs are typically used as single-model generators, where humans critique and refine their outputs, the potential for jointly-trained collaborative models remains largely unexplored. Despite promising results in multi-agent communication and debate settings, little progress has been made in training models to work together on tasks. In this paper, we present a first step toward "Multi-agent LLM training" (MALT) on reasoning problems. Our approach employs a sequential multi-agent setup with heterogeneous LLMs assigned specialized roles: a generator, verifier, and refinement model iteratively solving problems. We propose a trajectory-expansion-based synthetic data generation process and a credit assignment strategy driven by joint outcome based rewards. This enables our post-training setup to utilize both positive and negative trajectories to autonomously improve each model's specialized capabilities as part of a joint sequential system. We evaluate our approach across MATH, GSM8k, and CQA, where MALT on Llama 3.1 8B models achieves relative improvements of 14.14%, 7.12%, and 9.40% respectively over the same baseline model. This demonstrates an early advance in multi-agent cooperative capabilities for performance on mathematical and common sense reasoning questions. More generally, our work provides a concrete direction for research around multi-agent LLM training approaches.
Focus On This, Not That! Steering LLMs With Adaptive Feature Specification
Oct 30, 2024Despite the success of Instruction Tuning (IT) in training large language models (LLMs) to perform arbitrary user-specified tasks, these models often still leverage spurious or biased features learned from their training data, leading to undesired behaviours when deploying them in new contexts. In this work, we introduce Focus Instruction Tuning (FIT), which trains LLMs to condition their responses by focusing on specific features whilst ignoring others, leading to different behaviours based on what features are specified. Across several experimental settings, we show that focus-tuned models can be adaptively steered by focusing on different features at inference-time: for instance, robustness can be improved by focusing on task-causal features and ignoring spurious features, and social bias can be mitigated by ignoring demographic categories. Furthermore, FIT can steer behaviour in new contexts, generalising under distribution shift and to new unseen features at inference time, and thereby facilitating more robust, fair, and controllable LLM applications in real-world environments.