 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYour Text Encoder Can Be An Object-Level Watermarking Controller
Mar 15, 2025Invisible watermarking of AI-generated images can help with copyright protection, enabling detection and identification of AI-generated media. In this work, we present a novel approach to watermark images of T2I Latent Diffusion Models (LDMs). By only fine-tuning text token embeddings $W_*$, we enable watermarking in selected objects or parts of the image, offering greater flexibility compared to traditional full-image watermarking. Our method leverages the text encoder's compatibility across various LDMs, allowing plug-and-play integration for different LDMs. Moreover, introducing the watermark early in the encoding stage improves robustness to adversarial perturbations in later stages of the pipeline. Our approach achieves $99\%$ bit accuracy ($48$ bits) with a $10^5 \times$ reduction in model parameters, enabling efficient watermarking.
On the Coexistence and Ensembling of Watermarks
Jan 29, 2025



Watermarking, the practice of embedding imperceptible information into media such as images, videos, audio, and text, is essential for intellectual property protection, content provenance and attribution. The growing complexity of digital ecosystems necessitates watermarks for different uses to be embedded in the same media. However, to detect and decode all watermarks, they need to coexist well with one another. We perform the first study of coexistence of deep image watermarking methods and, contrary to intuition, we find that various open-source watermarks can coexist with only minor impacts on image quality and decoding robustness. The coexistence of watermarks also opens the avenue for ensembling watermarking methods. We show how ensembling can increase the overall message capacity and enable new trade-offs between capacity, accuracy, robustness and image quality, without needing to retrain the base models.
Self-Improving Diffusion Models with Synthetic Data
Aug 29, 2024
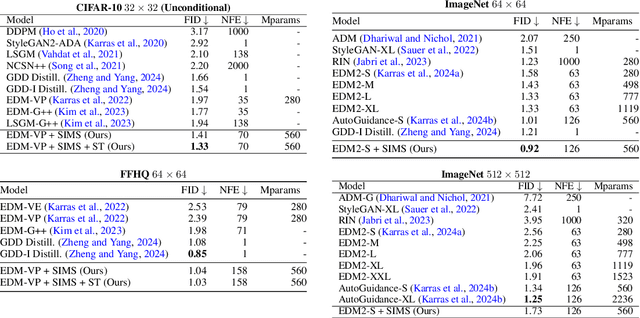
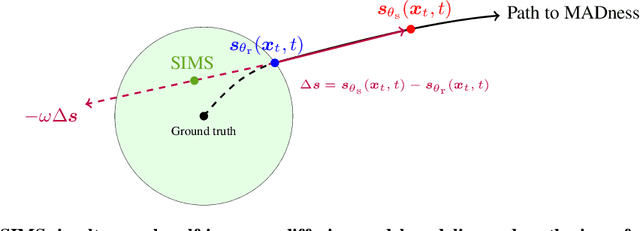
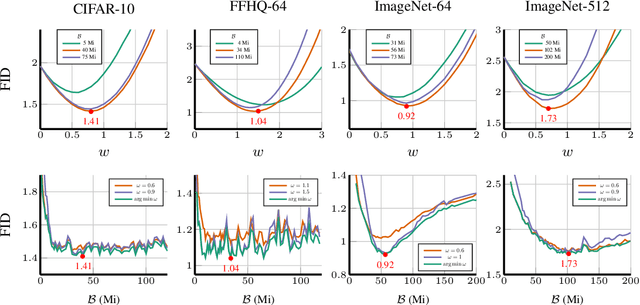
The artificial intelligence (AI) world is running out of real data for training increasingly large generative models, resulting in accelerating pressure to train on synthetic data. Unfortunately, training new generative models with synthetic data from current or past generation models creates an autophagous (self-consuming) loop that degrades the quality and/or diversity of the synthetic data in what has been termed model autophagy disorder (MAD) and model collapse. Current thinking around model autophagy recommends that synthetic data is to be avoided for model training lest the system deteriorate into MADness. In this paper, we take a different tack that treats synthetic data differently from real data. Self-IMproving diffusion models with Synthetic data (SIMS) is a new training concept for diffusion models that uses self-synthesized data to provide negative guidance during the generation process to steer a model's generative process away from the non-ideal synthetic data manifold and towards the real data distribution. We demonstrate that SIMS is capable of self-improvement; it establishes new records based on the Fr\'echet inception distance (FID) metric for CIFAR-10 and ImageNet-64 generation and achieves competitive results on FFHQ-64 and ImageNet-512. Moreover, SIMS is, to the best of our knowledge, the first prophylactic generative AI algorithm that can be iteratively trained on self-generated synthetic data without going MAD. As a bonus, SIMS can adjust a diffusion model's synthetic data distribution to match any desired in-domain target distribution to help mitigate biases and ensure fairness.
ProMark: Proactive Diffusion Watermarking for Causal Attribution
Mar 14, 2024



Generative AI (GenAI) is transforming creative workflows through the capability to synthesize and manipulate images via high-level prompts. Yet creatives are not well supported to receive recognition or reward for the use of their content in GenAI training. To this end, we propose ProMark, a causal attribution technique to attribute a synthetically generated image to its training data concepts like objects, motifs, templates, artists, or styles. The concept information is proactively embedded into the input training images using imperceptible watermarks, and the diffusion models (unconditional or conditional) are trained to retain the corresponding watermarks in generated images. We show that we can embed as many as $2^{16}$ unique watermarks into the training data, and each training image can contain more than one watermark. ProMark can maintain image quality whilst outperforming correlation-based attribution. Finally, several qualitative examples are presented, providing the confidence that the presence of the watermark conveys a causative relationship between training data and synthetic images.
TrustMark: Universal Watermarking for Arbitrary Resolution Images
Nov 30, 2023


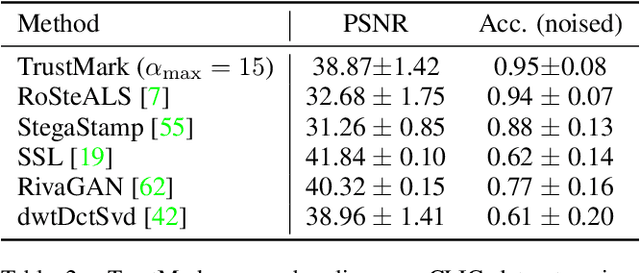
Imperceptible digital watermarking is important in copyright protection, misinformation prevention, and responsible generative AI. We propose TrustMark - a GAN-based watermarking method with novel design in architecture and spatio-spectra losses to balance the trade-off between watermarked image quality with the watermark recovery accuracy. Our model is trained with robustness in mind, withstanding various in- and out-place perturbations on the encoded image. Additionally, we introduce TrustMark-RM - a watermark remover method useful for re-watermarking. Our methods achieve state-of-art performance on 3 benchmarks comprising arbitrary resolution images.
An Evaluation of Forensic Facial Recognition
Nov 10, 2023Recent advances in machine learning and computer vision have led to reported facial recognition accuracies surpassing human performance. We question if these systems will translate to real-world forensic scenarios in which a potentially low-resolution, low-quality, partially-occluded image is compared against a standard facial database. We describe the construction of a large-scale synthetic facial dataset along with a controlled facial forensic lineup, the combination of which allows for a controlled evaluation of facial recognition under a range of real-world conditions. Using this synthetic dataset, and a popular dataset of real faces, we evaluate the accuracy of two popular neural-based recognition systems. We find that previously reported face recognition accuracies of more than 95% drop to as low as 65% in this more challenging forensic scenario.
EKILA: Synthetic Media Provenance and Attribution for Generative Art
Apr 10, 2023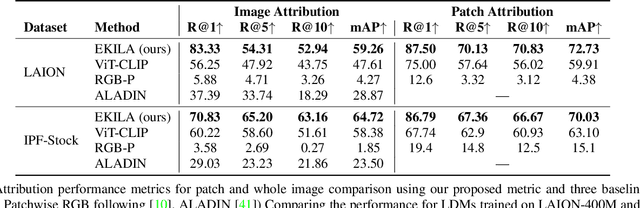
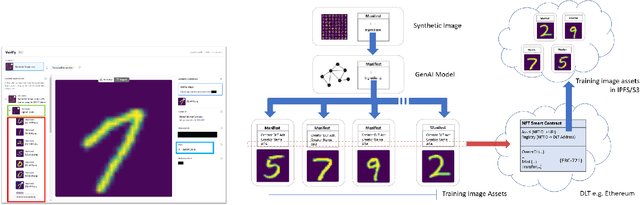
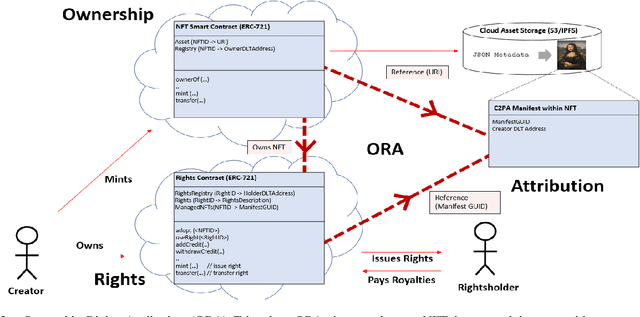

We present EKILA; a decentralized framework that enables creatives to receive recognition and reward for their contributions to generative AI (GenAI). EKILA proposes a robust visual attribution technique and combines this with an emerging content provenance standard (C2PA) to address the problem of synthetic image provenance -- determining the generative model and training data responsible for an AI-generated image. Furthermore, EKILA extends the non-fungible token (NFT) ecosystem to introduce a tokenized representation for rights, enabling a triangular relationship between the asset's Ownership, Rights, and Attribution (ORA). Leveraging the ORA relationship enables creators to express agency over training consent and, through our attribution model, to receive apportioned credit, including royalty payments for the use of their assets in GenAI.
RoSteALS: Robust Steganography using Autoencoder Latent Space
Apr 06, 2023



Data hiding such as steganography and invisible watermarking has important applications in copyright protection, privacy-preserved communication and content provenance. Existing works often fall short in either preserving image quality, or robustness against perturbations or are too complex to train. We propose RoSteALS, a practical steganography technique leveraging frozen pretrained autoencoders to free the payload embedding from learning the distribution of cover images. RoSteALS has a light-weight secret encoder of just 300k parameters, is easy to train, has perfect secret recovery performance and comparable image quality on three benchmarks. Additionally, RoSteALS can be adapted for novel cover-less steganography applications in which the cover image can be sampled from noise or conditioned on text prompts via a denoising diffusion process. Our model and code are available at \url{https://github.com/TuBui/RoSteALS}.
Watch Those Words: Video Falsification Detection Using Word-Conditioned Facial Motion
Dec 21, 2021



In today's era of digital misinformation, we are increasingly faced with new threats posed by video falsification techniques. Such falsifications range from cheapfakes (e.g., lookalikes or audio dubbing) to deepfakes (e.g., sophisticated AI media synthesis methods), which are becoming perceptually indistinguishable from real videos. To tackle this challenge, we propose a multi-modal semantic forensic approach to discover clues that go beyond detecting discrepancies in visual quality, thereby handling both simpler cheapfakes and visually persuasive deepfakes. In this work, our goal is to verify that the purported person seen in the video is indeed themselves by detecting anomalous correspondences between their facial movements and the words they are saying. We leverage the idea of attribution to learn person-specific biometric patterns that distinguish a given speaker from others. We use interpretable Action Units (AUs) to capture a persons' face and head movement as opposed to deep CNN visual features, and we are the first to use word-conditioned facial motion analysis. Unlike existing person-specific approaches, our method is also effective against attacks that focus on lip manipulation. We further demonstrate our method's effectiveness on a range of fakes not seen in training including those without video manipulation, that were not addressed in prior work.
A Penalized Shared-parameter Algorithm for Estimating Optimal Dynamic Treatment Regimens
Jul 13, 2021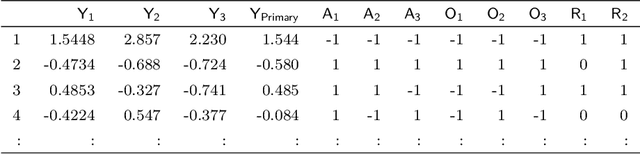
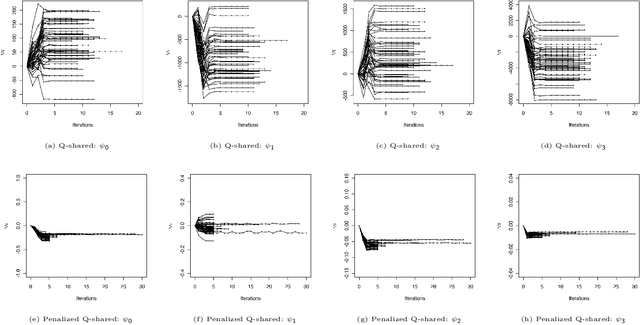
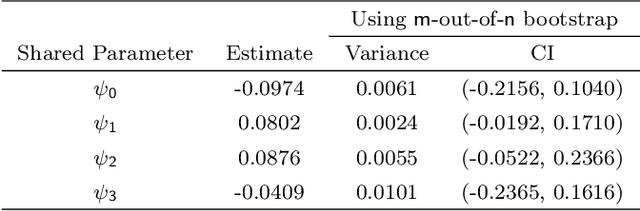
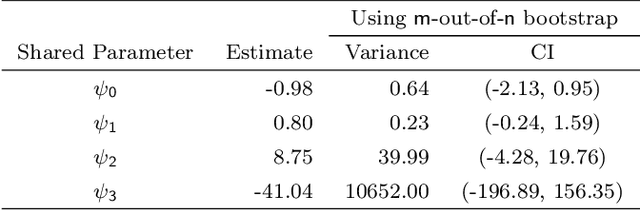
A dynamic treatment regimen (DTR) is a set of decision rules to personalize treatments for an individual using their medical history. The Q-learning based Q-shared algorithm has been used to develop DTRs that involve decision rules shared across multiple stages of intervention. We show that the existing Q-shared algorithm can suffer from non-convergence due to the use of linear models in the Q-learning setup, and identify the condition in which Q-shared fails. Leveraging properties from expansion-constrained ordinary least-squares, we give a penalized Q-shared algorithm that not only converges in settings that violate the condition, but can outperform the original Q-shared algorithm even when the condition is satisfied. We give evidence for the proposed method in a real-world application and several synthetic simulations.