 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Penalized Shared-parameter Algorithm for Estimating Optimal Dynamic Treatment Regimens
Jul 13, 2021
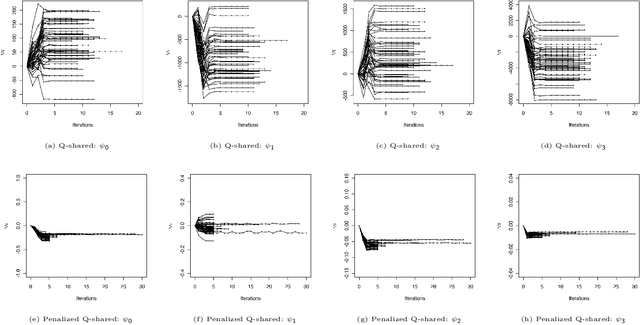
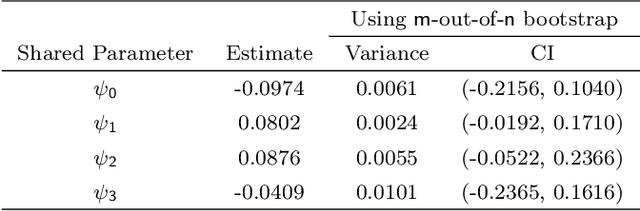
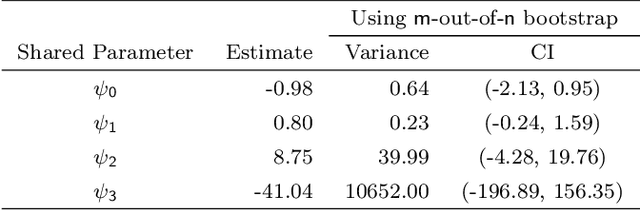
A dynamic treatment regimen (DTR) is a set of decision rules to personalize treatments for an individual using their medical history. The Q-learning based Q-shared algorithm has been used to develop DTRs that involve decision rules shared across multiple stages of intervention. We show that the existing Q-shared algorithm can suffer from non-convergence due to the use of linear models in the Q-learning setup, and identify the condition in which Q-shared fails. Leveraging properties from expansion-constrained ordinary least-squares, we give a penalized Q-shared algorithm that not only converges in settings that violate the condition, but can outperform the original Q-shared algorithm even when the condition is satisfied. We give evidence for the proposed method in a real-world application and several synthetic simulations.
Peak Criterion for Choosing Gaussian Kernel Bandwidth in Support Vector Data Description
Aug 08, 2017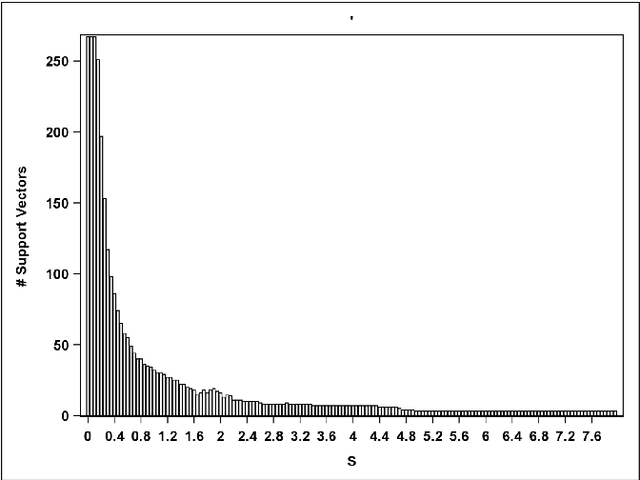

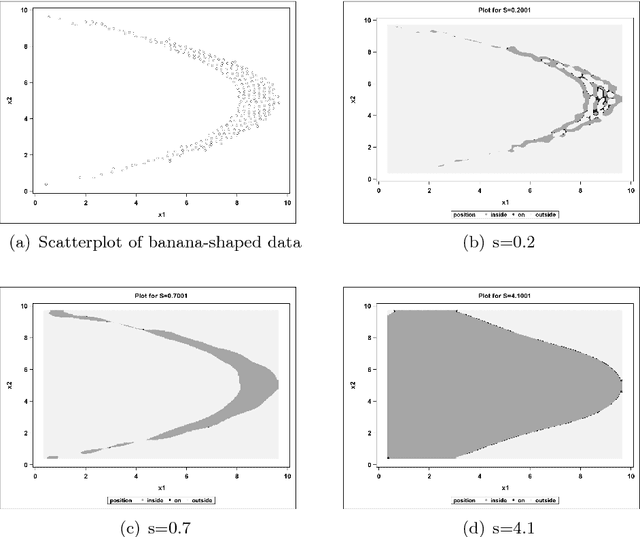
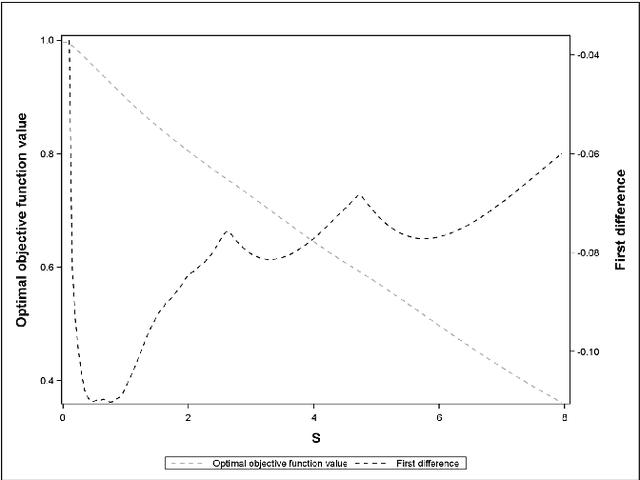
Support Vector Data Description (SVDD) is a machine-learning technique used for single class classification and outlier detection. SVDD formulation with kernel function provides a flexible boundary around data. The value of kernel function parameters affects the nature of the data boundary. For example, it is observed that with a Gaussian kernel, as the value of kernel bandwidth is lowered, the data boundary changes from spherical to wiggly. The spherical data boundary leads to underfitting, and an extremely wiggly data boundary leads to overfitting. In this paper, we propose empirical criterion to obtain good values of the Gaussian kernel bandwidth parameter. This criterion provides a smooth boundary that captures the essential geometric features of the data.
Sampling Method for Fast Training of Support Vector Data Description
Sep 25, 2016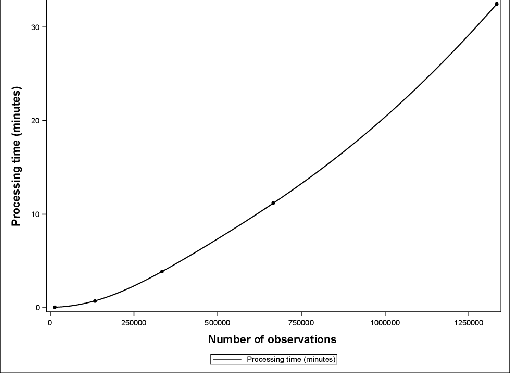
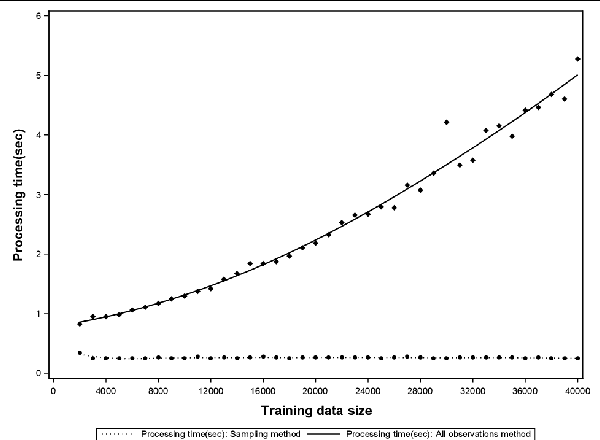
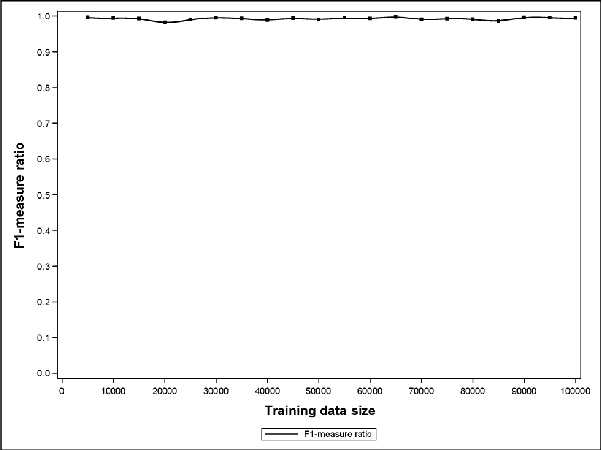
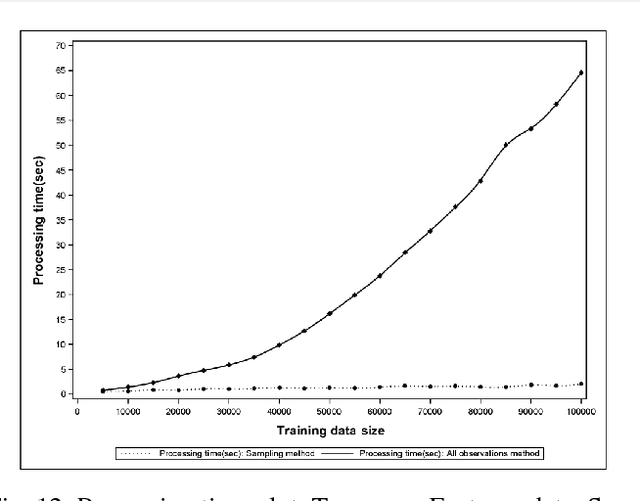
Support Vector Data Description (SVDD) is a popular outlier detection technique which constructs a flexible description of the input data. SVDD computation time is high for large training datasets which limits its use in big-data process-monitoring applications. We propose a new iterative sampling-based method for SVDD training. The method incrementally learns the training data description at each iteration by computing SVDD on an independent random sample selected with replacement from the training data set. The experimental results indicate that the proposed method is extremely fast and provides a good data description .