 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Visual Servoing under Human Supervision for Assembly Tasks
Apr 16, 2025We propose a framework enabling mobile manipulators to reliably complete pick-and-place tasks for assembling structures from construction blocks. The picking uses an eye-in-hand visual servoing controller for object tracking with Control Barrier Functions (CBFs) to ensure fiducial markers in the blocks remain visible. An additional robot with an eye-to-hand setup ensures precise placement, critical for structural stability. We integrate human-in-the-loop capabilities for flexibility and fault correction and analyze robustness to camera pose errors, proposing adapted barrier functions to handle them. Lastly, experiments validate the framework on 6-DoF mobile arms.
AttendLight: Universal Attention-Based Reinforcement Learning Model for Traffic Signal Control
Oct 12, 2020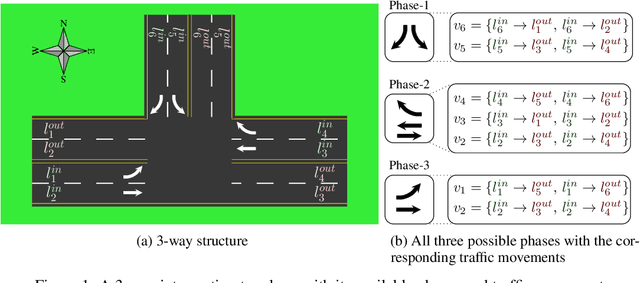

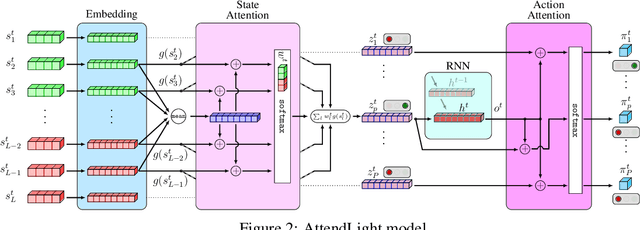
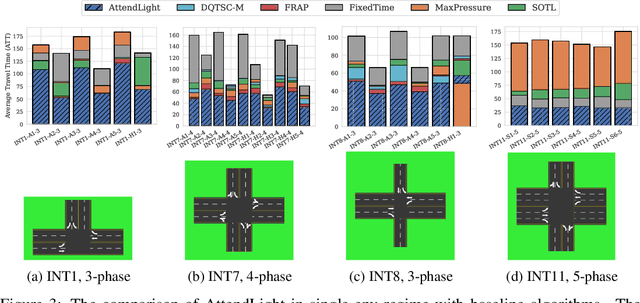
We propose AttendLight, an end-to-end Reinforcement Learning (RL) algorithm for the problem of traffic signal control. Previous approaches for this problem have the shortcoming that they require training for each new intersection with a different structure or traffic flow distribution. AttendLight solves this issue by training a single, universal model for intersections with any number of roads, lanes, phases (possible signals), and traffic flow. To this end, we propose a deep RL model which incorporates two attention models. The first attention model is introduced to handle different numbers of roads-lanes; and the second attention model is intended for enabling decision-making with any number of phases in an intersection. As a result, our proposed model works for any intersection configuration, as long as a similar configuration is represented in the training set. Experiments were conducted with both synthetic and real-world standard benchmark data-sets. The results we show cover intersections with three or four approaching roads; one-directional/bi-directional roads with one, two, and three lanes; different number of phases; and different traffic flows. We consider two regimes: (i) single-environment training, single-deployment, and (ii) multi-environment training, multi-deployment. AttendLight outperforms both classical and other RL-based approaches on all cases in both regimes.
Multi-Task Learning with Incomplete Data for Healthcare
Jul 06, 2018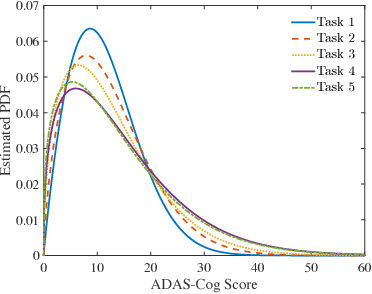

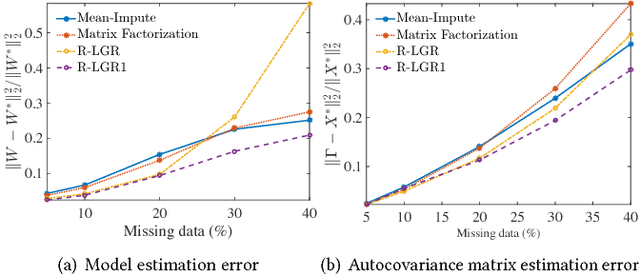
Multi-task learning is a type of transfer learning that trains multiple tasks simultaneously and leverages the shared information between related tasks to improve the generalization performance. However, missing features in the input matrix is a much more difficult problem which needs to be carefully addressed. Removing records with missing values can significantly reduce the sample size, which is impractical for datasets with large percentage of missing values. Popular imputation methods often distort the covariance structure of the data, which causes inaccurate inference. In this paper we propose using plug-in covariance matrix estimators to tackle the challenge of missing features. Specifically, we analyze the plug-in estimators under the framework of robust multi-task learning with LASSO and graph regularization, which captures the relatedness between tasks via graph regularization. We use the Alzheimer's disease progression dataset as an example to show how the proposed framework is effective for prediction and model estimation when missing data is present.
RULLS: Randomized Union of Locally Linear Subspaces for Feature Engineering
Apr 25, 2018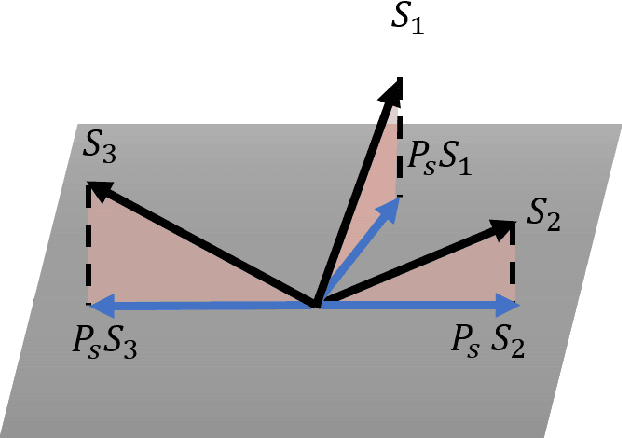
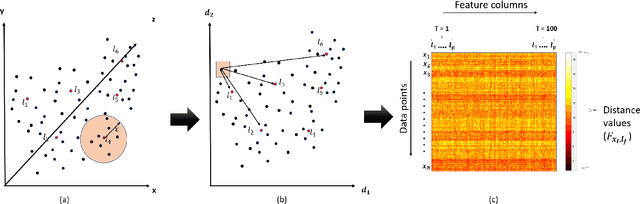
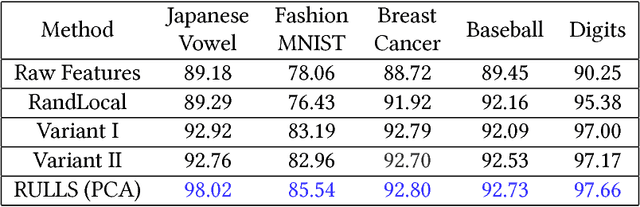
Feature engineering plays an important role in the success of a machine learning model. Most of the effort in training a model goes into data preparation and choosing the right representation. In this paper, we propose a robust feature engineering method, Randomized Union of Locally Linear Subspaces (RULLS). We generate sparse, non-negative, and rotation invariant features in an unsupervised fashion. RULLS aggregates features from a random union of subspaces by describing each point using globally chosen landmarks. These landmarks serve as anchor points for choosing subspaces. Our method provides a way to select features that are relevant in the neighborhood around these chosen landmarks. Distances from each data point to $k$ closest landmarks are encoded in the feature matrix. The final feature representation is a union of features from all chosen subspaces. The effectiveness of our algorithm is shown on various real-world datasets for tasks such as clustering and classification of raw data and in the presence of noise. We compare our method with existing feature generation methods. Results show a high performance of our method on both classification and clustering tasks.
Peak Criterion for Choosing Gaussian Kernel Bandwidth in Support Vector Data Description
Aug 08, 2017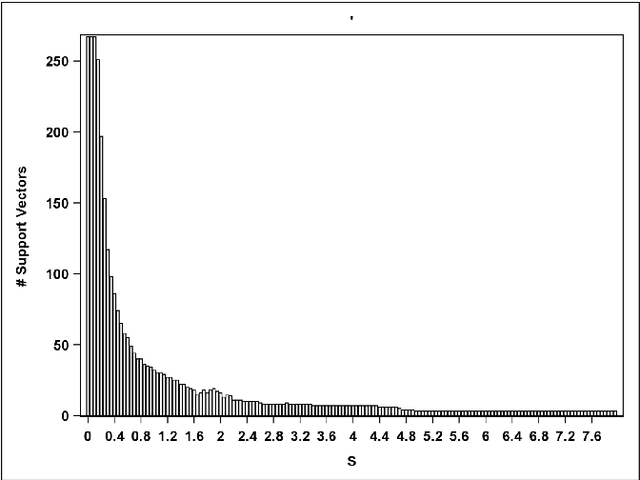

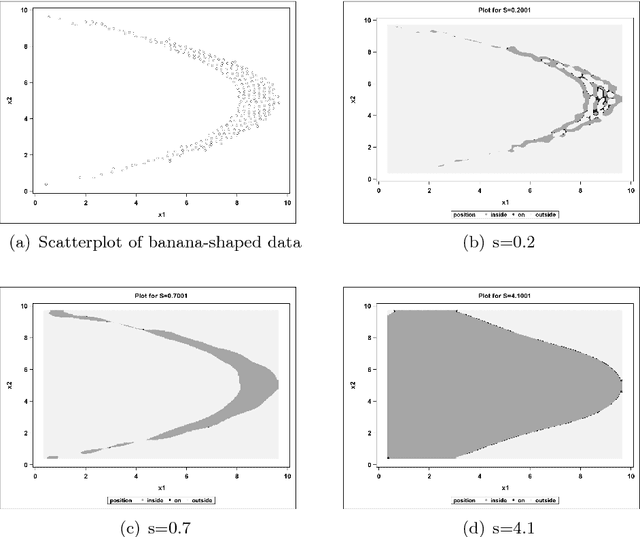
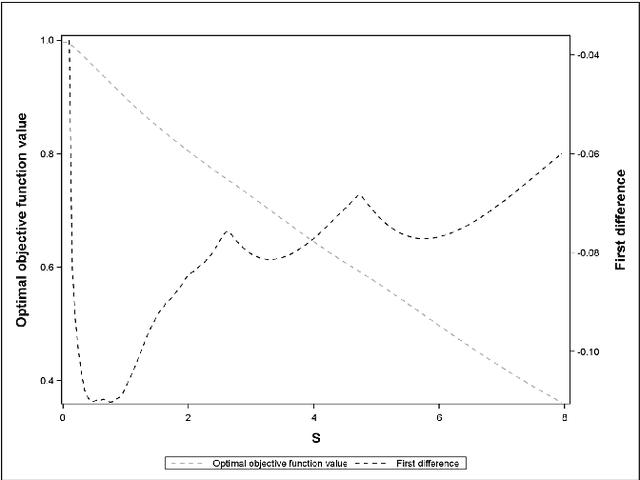
Support Vector Data Description (SVDD) is a machine-learning technique used for single class classification and outlier detection. SVDD formulation with kernel function provides a flexible boundary around data. The value of kernel function parameters affects the nature of the data boundary. For example, it is observed that with a Gaussian kernel, as the value of kernel bandwidth is lowered, the data boundary changes from spherical to wiggly. The spherical data boundary leads to underfitting, and an extremely wiggly data boundary leads to overfitting. In this paper, we propose empirical criterion to obtain good values of the Gaussian kernel bandwidth parameter. This criterion provides a smooth boundary that captures the essential geometric features of the data.
Online Robust Principal Component Analysis with Change Point Detection
Mar 20, 2017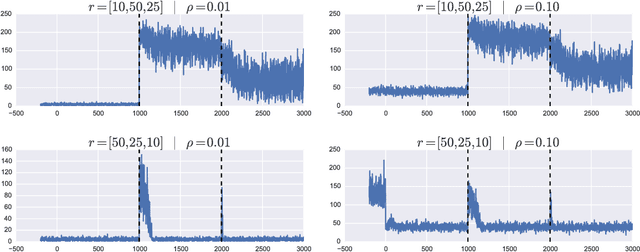
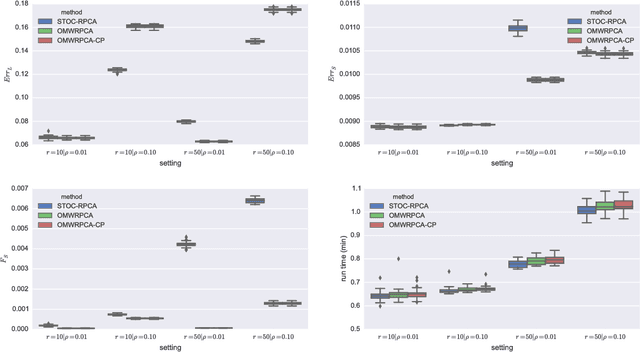
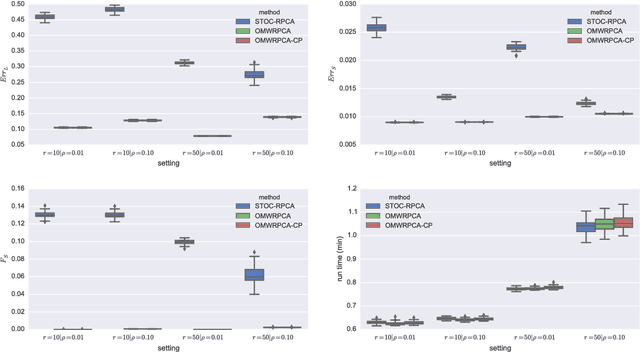
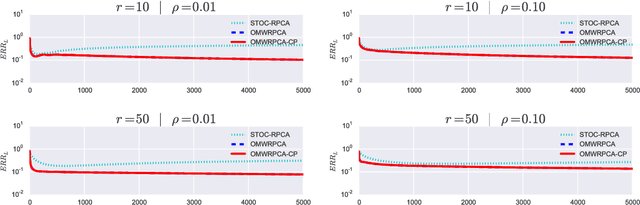
Robust PCA methods are typically batch algorithms which requires loading all observations into memory before processing. This makes them inefficient to process big data. In this paper, we develop an efficient online robust principal component methods, namely online moving window robust principal component analysis (OMWRPCA). Unlike existing algorithms, OMWRPCA can successfully track not only slowly changing subspace but also abruptly changed subspace. By embedding hypothesis testing into the algorithm, OMWRPCA can detect change points of the underlying subspaces. Extensive simulation studies demonstrate the superior performance of OMWRPCA compared with other state-of-art approaches. We also apply the algorithm for real-time background subtraction of surveillance video.
A recursive procedure for density estimation on the binary hypercube
Nov 30, 2012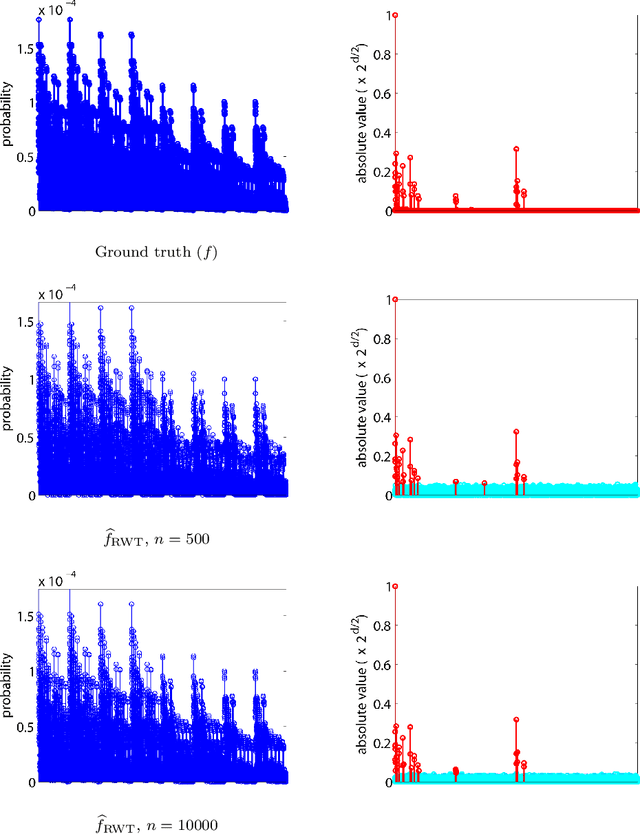
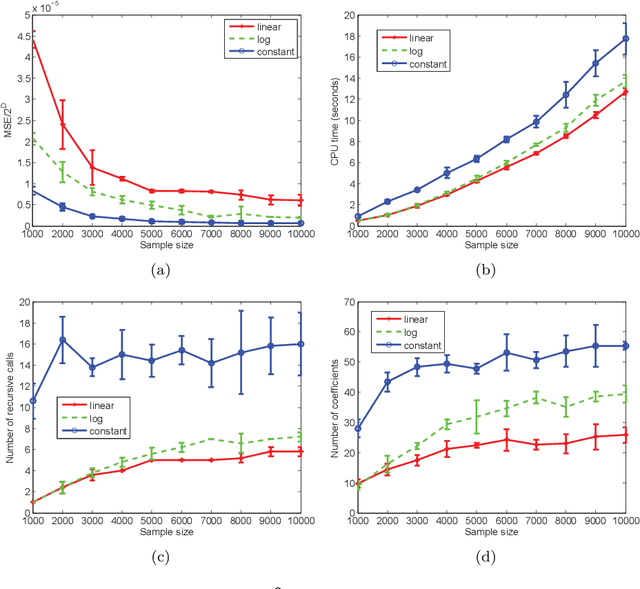
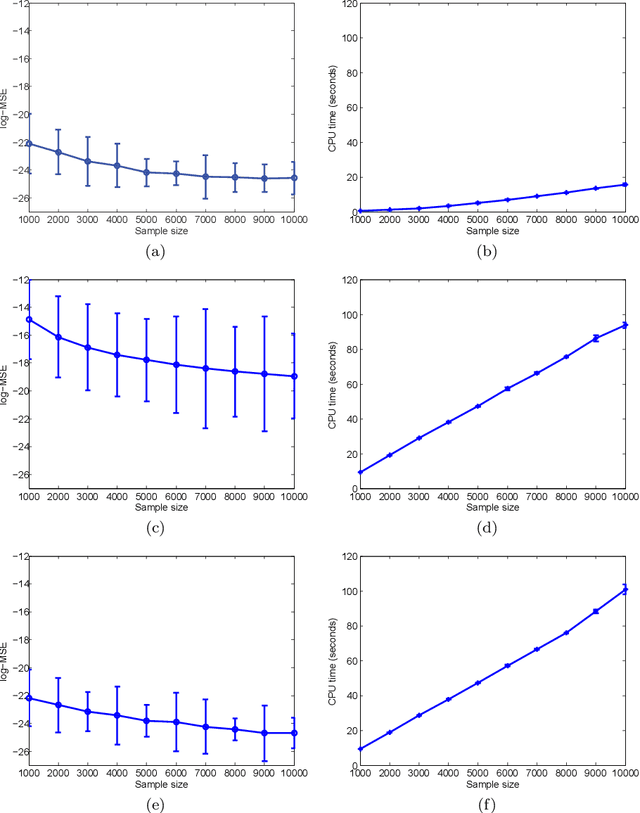
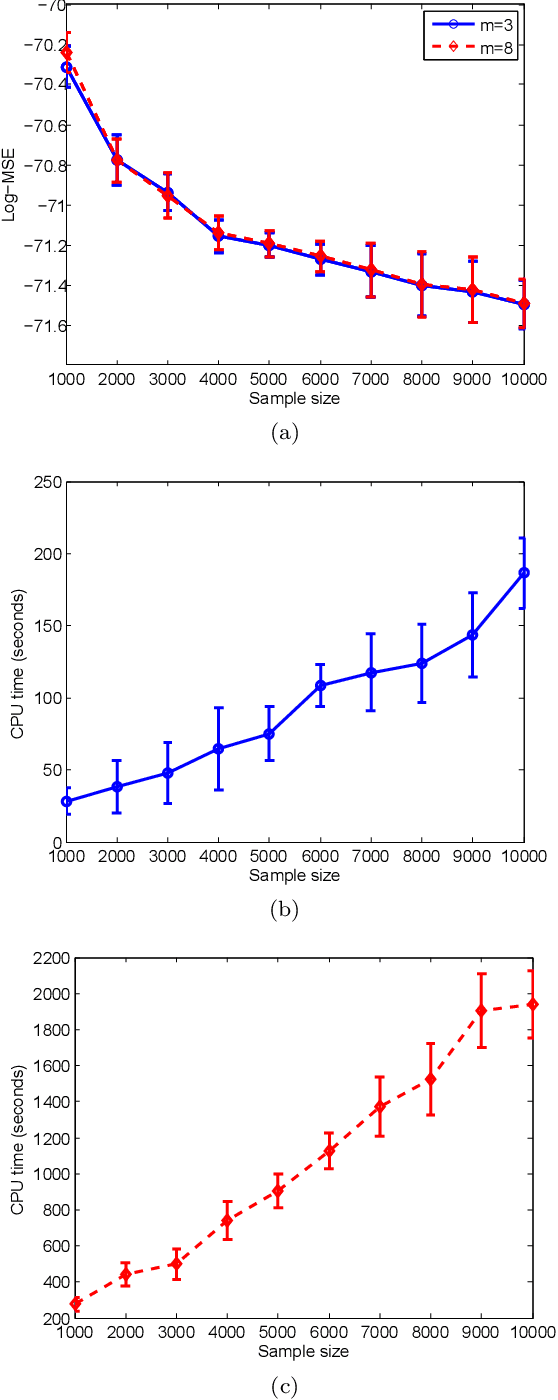
This paper describes a recursive estimation procedure for multivariate binary densities (probability distributions of vectors of Bernoulli random variables) using orthogonal expansions. For $d$ covariates, there are $2^d$ basis coefficients to estimate, which renders conventional approaches computationally prohibitive when $d$ is large. However, for a wide class of densities that satisfy a certain sparsity condition, our estimator runs in probabilistic polynomial time and adapts to the unknown sparsity of the underlying density in two key ways: (1) it attains near-minimax mean-squared error for moderate sample sizes, and (2) the computational complexity is lower for sparser densities. Our method also allows for flexible control of the trade-off between mean-squared error and computational complexity.
Sequential anomaly detection in the presence of noise and limited feedback
Mar 13, 2012
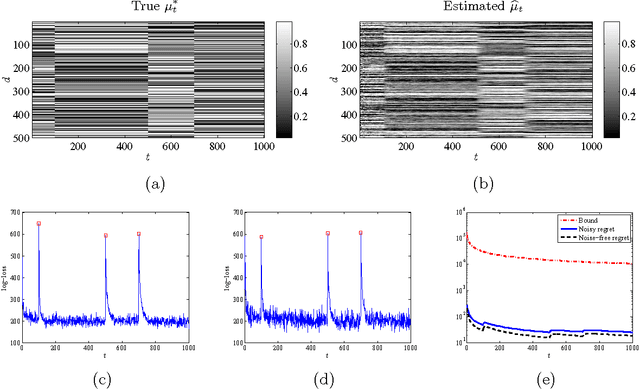
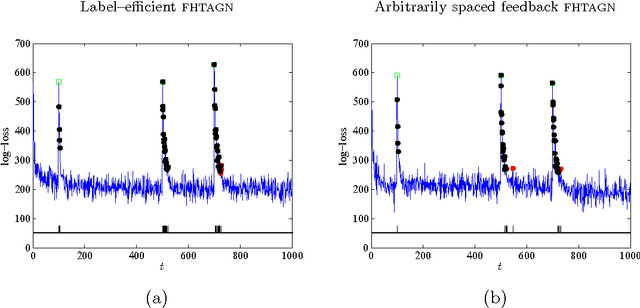

This paper describes a methodology for detecting anomalies from sequentially observed and potentially noisy data. The proposed approach consists of two main elements: (1) {\em filtering}, or assigning a belief or likelihood to each successive measurement based upon our ability to predict it from previous noisy observations, and (2) {\em hedging}, or flagging potential anomalies by comparing the current belief against a time-varying and data-adaptive threshold. The threshold is adjusted based on the available feedback from an end user. Our algorithms, which combine universal prediction with recent work on online convex programming, do not require computing posterior distributions given all current observations and involve simple primal-dual parameter updates. At the heart of the proposed approach lie exponential-family models which can be used in a wide variety of contexts and applications, and which yield methods that achieve sublinear per-round regret against both static and slowly varying product distributions with marginals drawn from the same exponential family. Moreover, the regret against static distributions coincides with the minimax value of the corresponding online strongly convex game. We also prove bounds on the number of mistakes made during the hedging step relative to the best offline choice of the threshold with access to all estimated beliefs and feedback signals. We validate the theory on synthetic data drawn from a time-varying distribution over binary vectors of high dimensionality, as well as on the Enron email dataset.