 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCRAFT: A Tendon-Driven Hand with Hybrid Hard-Soft Compliance
Mar 12, 2026We introduce CRAFT hand, a tendon-driven anthropomorphic hand with hybrid hard-soft compliance for contact-rich manipulation. The design is based on a simple idea: contact is not uniform across the hand. Impacts concentrate at joints, while links carry most of the load. CRAFT places soft material at joints and keeps links rigid, and uses rollingcontact joint surfaces to keep flexion on repeatable motion paths. Fifteen motors mounted on the fingers drive the hand through tendons, keeping the form factor compact and the fingers light. In structural tests, CRAFT improves strength and endurance while maintaining comparable repeatability. In teleoperation, CRAFT improves handling of fragile and low-friction items, and the hand covers 33/33 grasps in the Feix taxonomy. The full design costs under $600 and will be released open-source with visionbased teleoperation and simulation integration. Project page: http://craft-hand.github.io/
Robotic Manipulation by Imitating Generated Videos Without Physical Demonstrations
Jul 01, 2025This work introduces Robots Imitating Generated Videos (RIGVid), a system that enables robots to perform complex manipulation tasks--such as pouring, wiping, and mixing--purely by imitating AI-generated videos, without requiring any physical demonstrations or robot-specific training. Given a language command and an initial scene image, a video diffusion model generates potential demonstration videos, and a vision-language model (VLM) automatically filters out results that do not follow the command. A 6D pose tracker then extracts object trajectories from the video, and the trajectories are retargeted to the robot in an embodiment-agnostic fashion. Through extensive real-world evaluations, we show that filtered generated videos are as effective as real demonstrations, and that performance improves with generation quality. We also show that relying on generated videos outperforms more compact alternatives such as keypoint prediction using VLMs, and that strong 6D pose tracking outperforms other ways to extract trajectories, such as dense feature point tracking. These findings suggest that videos produced by a state-of-the-art off-the-shelf model can offer an effective source of supervision for robotic manipulation.
A Real-to-Sim-to-Real Approach to Robotic Manipulation with VLM-Generated Iterative Keypoint Rewards
Feb 12, 2025Task specification for robotic manipulation in open-world environments is challenging, requiring flexible and adaptive objectives that align with human intentions and can evolve through iterative feedback. We introduce Iterative Keypoint Reward (IKER), a visually grounded, Python-based reward function that serves as a dynamic task specification. Our framework leverages VLMs to generate and refine these reward functions for multi-step manipulation tasks. Given RGB-D observations and free-form language instructions, we sample keypoints in the scene and generate a reward function conditioned on these keypoints. IKER operates on the spatial relationships between keypoints, leveraging commonsense priors about the desired behaviors, and enabling precise SE(3) control. We reconstruct real-world scenes in simulation and use the generated rewards to train reinforcement learning (RL) policies, which are then deployed into the real world-forming a real-to-sim-to-real loop. Our approach demonstrates notable capabilities across diverse scenarios, including both prehensile and non-prehensile tasks, showcasing multi-step task execution, spontaneous error recovery, and on-the-fly strategy adjustments. The results highlight IKER's effectiveness in enabling robots to perform multi-step tasks in dynamic environments through iterative reward shaping.
UnZipLoRA: Separating Content and Style from a Single Image
Dec 05, 2024
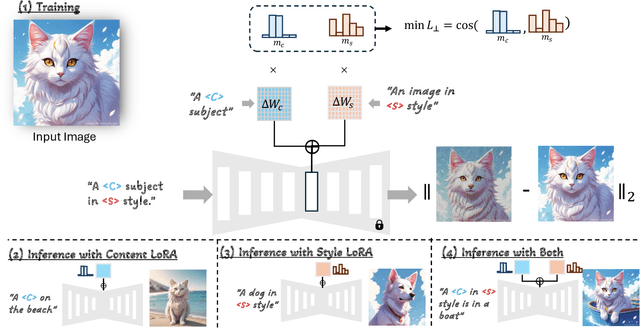
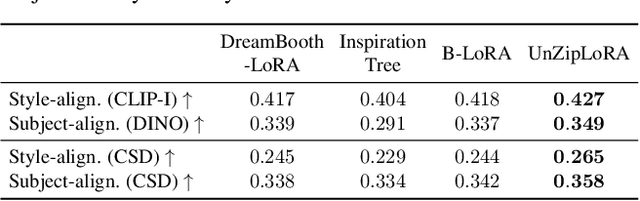
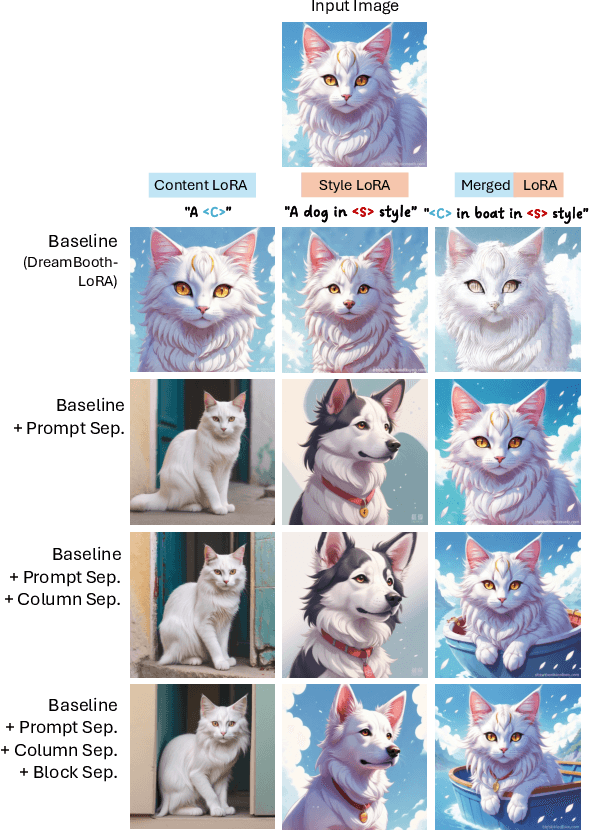
This paper introduces UnZipLoRA, a method for decomposing an image into its constituent subject and style, represented as two distinct LoRAs (Low-Rank Adaptations). Unlike existing personalization techniques that focus on either subject or style in isolation, or require separate training sets for each, UnZipLoRA disentangles these elements from a single image by training both the LoRAs simultaneously. UnZipLoRA ensures that the resulting LoRAs are compatible, i.e., they can be seamlessly combined using direct addition. UnZipLoRA enables independent manipulation and recontextualization of subject and style, including generating variations of each, applying the extracted style to new subjects, and recombining them to reconstruct the original image or create novel variations. To address the challenge of subject and style entanglement, UnZipLoRA employs a novel prompt separation technique, as well as column and block separation strategies to accurately preserve the characteristics of subject and style, and ensure compatibility between the learned LoRAs. Evaluation with human studies and quantitative metrics demonstrates UnZipLoRA's effectiveness compared to other state-of-the-art methods, including DreamBooth-LoRA, Inspiration Tree, and B-LoRA.
Shadows Don't Lie and Lines Can't Bend! Generative Models don't know Projective Geometryfor now
Nov 28, 2023



Generative models can produce impressively realistic images. This paper demonstrates that generated images have geometric features different from those of real images. We build a set of collections of generated images, prequalified to fool simple, signal-based classifiers into believing they are real. We then show that prequalified generated images can be identified reliably by classifiers that only look at geometric properties. We use three such classifiers. All three classifiers are denied access to image pixels, and look only at derived geometric features. The first classifier looks at the perspective field of the image, the second looks at lines detected in the image, and the third looks at relations between detected objects and shadows. Our procedure detects generated images more reliably than SOTA local signal based detectors, for images from a number of distinct generators. Saliency maps suggest that the classifiers can identify geometric problems reliably. We conclude that current generators cannot reliably reproduce geometric properties of real images.
Street TryOn: Learning In-the-Wild Virtual Try-On from Unpaired Person Images
Nov 27, 2023Virtual try-on has become a popular research topic, but most existing methods focus on studio images with a clean background. They can achieve plausible results for this studio try-on setting by learning to warp a garment image to fit a person's body from paired training data, i.e., garment images paired with images of people wearing the same garment. Such data is often collected from commercial websites, where each garment is demonstrated both by itself and on several models. By contrast, it is hard to collect paired data for in-the-wild scenes, and therefore, virtual try-on for casual images of people against cluttered backgrounds is rarely studied. In this work, we fill the gap in the current virtual try-on research by (1) introducing a Street TryOn benchmark to evaluate performance on street scenes and (2) proposing a novel method that can learn without paired data, from a set of in-the-wild person images directly. Our method can achieve robust performance across shop and street domains using a novel DensePose warping correction method combined with diffusion-based inpainting controlled by pose and semantic segmentation. Our experiments demonstrate competitive performance for standard studio try-on tasks and SOTA performance for street try-on and cross-domain try-on tasks.
ZipLoRA: Any Subject in Any Style by Effectively Merging LoRAs
Nov 22, 2023



Methods for finetuning generative models for concept-driven personalization generally achieve strong results for subject-driven or style-driven generation. Recently, low-rank adaptations (LoRA) have been proposed as a parameter-efficient way of achieving concept-driven personalization. While recent work explores the combination of separate LoRAs to achieve joint generation of learned styles and subjects, existing techniques do not reliably address the problem; they often compromise either subject fidelity or style fidelity. We propose ZipLoRA, a method to cheaply and effectively merge independently trained style and subject LoRAs in order to achieve generation of any user-provided subject in any user-provided style. Experiments on a wide range of subject and style combinations show that ZipLoRA can generate compelling results with meaningful improvements over baselines in subject and style fidelity while preserving the ability to recontextualize. Project page: https://ziplora.github.io
JoIN: Joint GANs Inversion for Intrinsic Image Decomposition
May 18, 2023In this work, we propose to solve ill-posed inverse imaging problems using a bank of Generative Adversarial Networks (GAN) as a prior and apply our method to the case of Intrinsic Image Decomposition for faces and materials. Our method builds on the demonstrated success of GANs to capture complex image distributions. At the core of our approach is the idea that the latent space of a GAN is a well-suited optimization domain to solve inverse problems. Given an input image, we propose to jointly inverse the latent codes of a set of GANs and combine their outputs to reproduce the input. Contrary to most GAN inversion methods which are limited to inverting only a single GAN, we demonstrate that it is possible to maintain distribution priors while inverting several GANs jointly. We show that our approach is modular, allowing various forward imaging models, that it can successfully decompose both synthetic and real images, and provides additional advantages such as leveraging properties of GAN latent space for image relighting.
One-Shot Stylization for Full-Body Human Images
Apr 14, 2023



The goal of human stylization is to transfer full-body human photos to a style specified by a single art character reference image. Although previous work has succeeded in example-based stylization of faces and generic scenes, full-body human stylization is a more complex domain. This work addresses several unique challenges of stylizing full-body human images. We propose a method for one-shot fine-tuning of a pose-guided human generator to preserve the "content" (garments, face, hair, pose) of the input photo and the "style" of the artistic reference. Since body shape deformation is an essential component of an art character's style, we incorporate a novel skeleton deformation module to reshape the pose of the input person and modify the DiOr pose-guided person generator to be more robust to the rescaled poses falling outside the distribution of the realistic poses that the generator is originally trained on. Several human studies verify the effectiveness of our approach.
Robust Online Video Instance Segmentation with Track Queries
Nov 16, 2022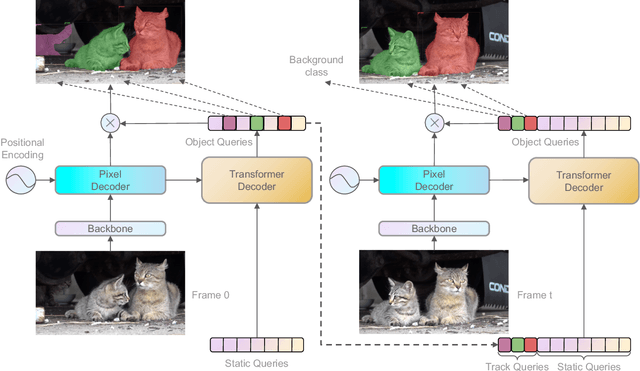
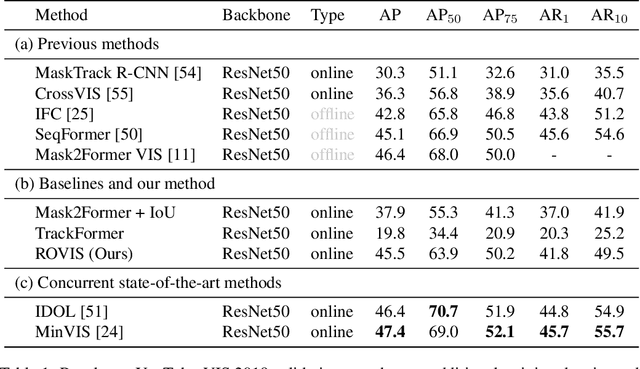

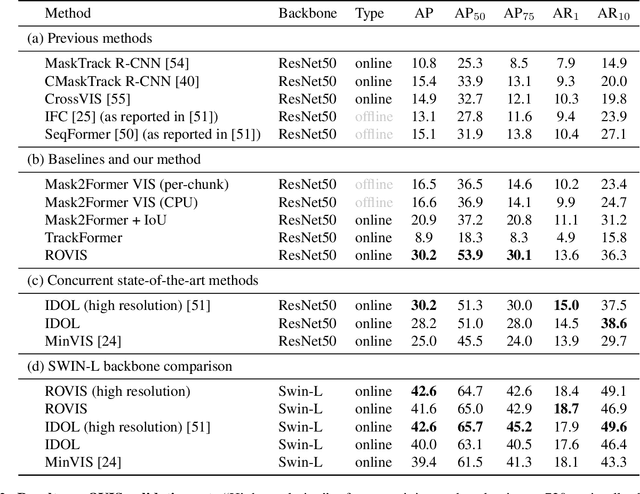
Recently, transformer-based methods have achieved impressive results on Video Instance Segmentation (VIS). However, most of these top-performing methods run in an offline manner by processing the entire video clip at once to predict instance mask volumes. This makes them incapable of handling the long videos that appear in challenging new video instance segmentation datasets like UVO and OVIS. We propose a fully online transformer-based video instance segmentation model that performs comparably to top offline methods on the YouTube-VIS 2019 benchmark and considerably outperforms them on UVO and OVIS. This method, called Robust Online Video Segmentation (ROVIS), augments the Mask2Former image instance segmentation model with track queries, a lightweight mechanism for carrying track information from frame to frame, originally introduced by the TrackFormer method for multi-object tracking. We show that, when combined with a strong enough image segmentation architecture, track queries can exhibit impressive accuracy while not being constrained to short videos.