 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnZipLoRA: Separating Content and Style from a Single Image
Dec 05, 2024
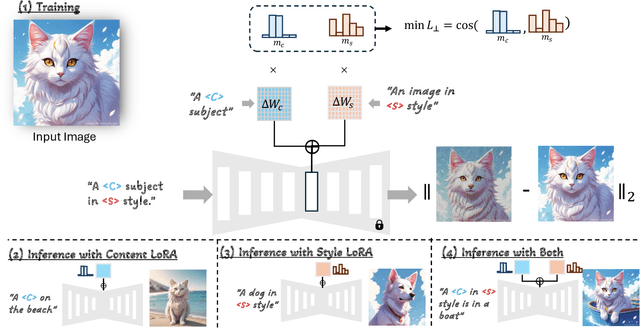
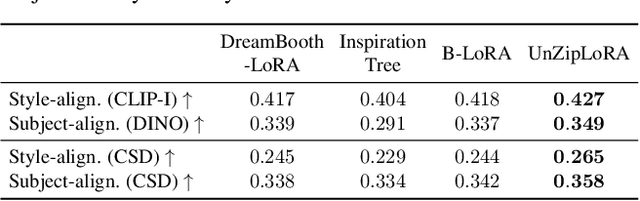
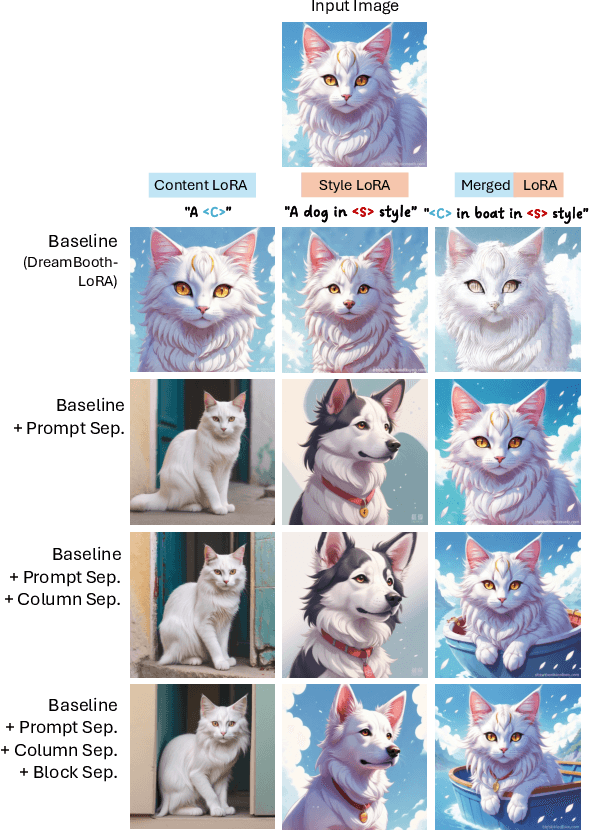
This paper introduces UnZipLoRA, a method for decomposing an image into its constituent subject and style, represented as two distinct LoRAs (Low-Rank Adaptations). Unlike existing personalization techniques that focus on either subject or style in isolation, or require separate training sets for each, UnZipLoRA disentangles these elements from a single image by training both the LoRAs simultaneously. UnZipLoRA ensures that the resulting LoRAs are compatible, i.e., they can be seamlessly combined using direct addition. UnZipLoRA enables independent manipulation and recontextualization of subject and style, including generating variations of each, applying the extracted style to new subjects, and recombining them to reconstruct the original image or create novel variations. To address the challenge of subject and style entanglement, UnZipLoRA employs a novel prompt separation technique, as well as column and block separation strategies to accurately preserve the characteristics of subject and style, and ensure compatibility between the learned LoRAs. Evaluation with human studies and quantitative metrics demonstrates UnZipLoRA's effectiveness compared to other state-of-the-art methods, including DreamBooth-LoRA, Inspiration Tree, and B-LoRA.
Street TryOn: Learning In-the-Wild Virtual Try-On from Unpaired Person Images
Nov 27, 2023Virtual try-on has become a popular research topic, but most existing methods focus on studio images with a clean background. They can achieve plausible results for this studio try-on setting by learning to warp a garment image to fit a person's body from paired training data, i.e., garment images paired with images of people wearing the same garment. Such data is often collected from commercial websites, where each garment is demonstrated both by itself and on several models. By contrast, it is hard to collect paired data for in-the-wild scenes, and therefore, virtual try-on for casual images of people against cluttered backgrounds is rarely studied. In this work, we fill the gap in the current virtual try-on research by (1) introducing a Street TryOn benchmark to evaluate performance on street scenes and (2) proposing a novel method that can learn without paired data, from a set of in-the-wild person images directly. Our method can achieve robust performance across shop and street domains using a novel DensePose warping correction method combined with diffusion-based inpainting controlled by pose and semantic segmentation. Our experiments demonstrate competitive performance for standard studio try-on tasks and SOTA performance for street try-on and cross-domain try-on tasks.
One-Shot Stylization for Full-Body Human Images
Apr 14, 2023



The goal of human stylization is to transfer full-body human photos to a style specified by a single art character reference image. Although previous work has succeeded in example-based stylization of faces and generic scenes, full-body human stylization is a more complex domain. This work addresses several unique challenges of stylizing full-body human images. We propose a method for one-shot fine-tuning of a pose-guided human generator to preserve the "content" (garments, face, hair, pose) of the input photo and the "style" of the artistic reference. Since body shape deformation is an essential component of an art character's style, we incorporate a novel skeleton deformation module to reshape the pose of the input person and modify the DiOr pose-guided person generator to be more robust to the rescaled poses falling outside the distribution of the realistic poses that the generator is originally trained on. Several human studies verify the effectiveness of our approach.
Learning Garment DensePose for Robust Warping in Virtual Try-On
Mar 30, 2023


Virtual try-on, i.e making people virtually try new garments, is an active research area in computer vision with great commercial applications. Current virtual try-on methods usually work in a two-stage pipeline. First, the garment image is warped on the person's pose using a flow estimation network. Then in the second stage, the warped garment is fused with the person image to render a new try-on image. Unfortunately, such methods are heavily dependent on the quality of the garment warping which often fails when dealing with hard poses (e.g., a person lifting or crossing arms). In this work, we propose a robust warping method for virtual try-on based on a learned garment DensePose which has a direct correspondence with the person's DensePose. Due to the lack of annotated data, we show how to leverage an off-the-shelf person DensePose model and a pretrained flow model to learn the garment DensePose in a weakly supervised manner. The garment DensePose allows a robust warping to any person's pose without any additional computation. Our method achieves the state-of-the-art equivalent on virtual try-on benchmarks and shows warping robustness on in-the-wild person images with hard poses, making it more suited for real-world virtual try-on applications.
Dressing in Order: Recurrent Person Image Generation for Pose Transfer, Virtual Try-on and Outfit Editing
Apr 14, 2021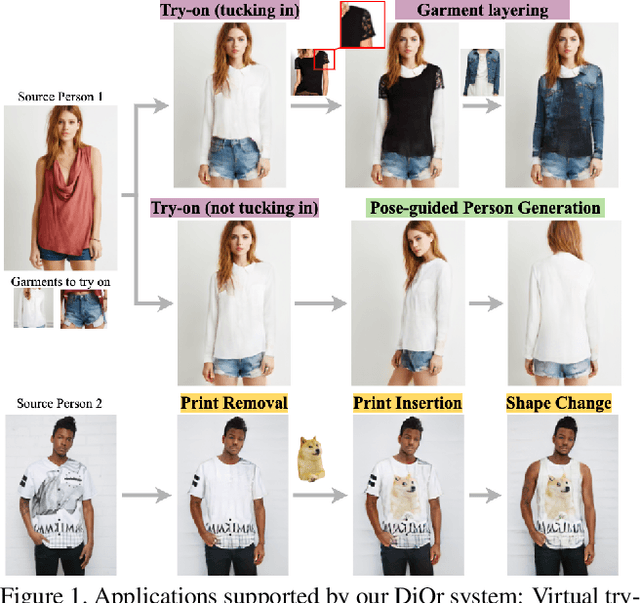
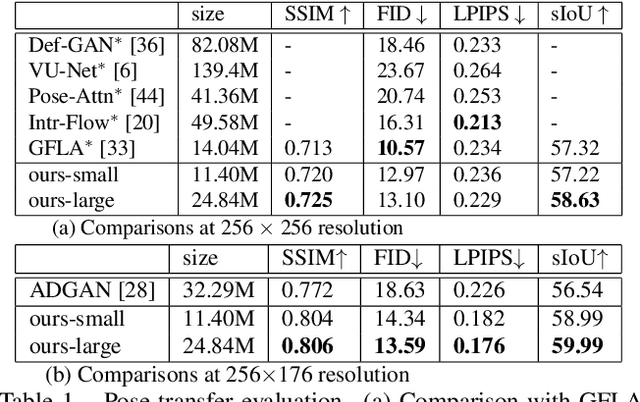


This paper proposes a flexible person generation framework called Dressing in Order (DiOr), which supports 2D pose transfer, virtual try-on, and several fashion editing tasks. Key to DiOr is a novel recurrent generation pipeline to sequentially put garments on a person, so that trying on the same garments in different orders will result in different looks. Our system can produce dressing effects not achievable by existing work, including different interactions of garments (e.g., wearing a top tucked into the bottom or over it), as well as layering of multiple garments of the same type (e.g., jacket over shirt over t-shirt). DiOr explicitly encodes the shape and texture of each garment, enabling these elements to be edited separately. Joint training on pose transfer and inpainting helps with detail preservation and coherence of generated garments. Extensive evaluations show that DiOr outperforms other recent methods like ADGAN in terms of output quality, and handles a wide range of editing functions for which there is no direct supervision.