 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStill Camouflage, Moving Illusion: View-Induced Trajectory Manipulation in Autonomous Driving
May 12, 2026Existing physical adversarial attacks on vision-based autonomous driving induce time-evolving perception errors, including biased object tracking or trajectory prediction, through (i) sophisticated physical patch inducing detection box drift when entering the view distance, or (ii) dynamically changing patches that cause different perception errors at different time. In both cases, viewing-angle variation is treated as a challenge, requiring adversarial patches to remain effective across frames under varying views, leading to complex multi-view optimization. In contrast, we show that viewing-angle variation itself can be turned into an attack tool. We design a new attack paradigm where a static, passive adversarial camouflage is mounted on a vehicle whose view-dependent appearance naturally evolves with relative motion, inducing consistent feature drift across frames. This causes the system to infer a physically plausible but incorrect trajectory, such as a false cut-in, which propagates to downstream decision-making and triggers unnecessary braking. Unlike prior approaches that require multi-view robustness or active intervention, our attack emerges from normal driving dynamics and is easy to deploy: a parked vehicle with a natural camouflage can induce hard braking in passing autonomous vehicles. We demonstrate the novel attack on nuScenes dataset, showing the effectiveness with an end-to-end success rate of up to 87.5%, measured by hard-braking events, and robustness across different scene backgrounds, victim vehicle speeds, and perception models.
Tuna-2: Pixel Embeddings Beat Vision Encoders for Multimodal Understanding and Generation
Apr 27, 2026Unified multimodal models typically rely on pretrained vision encoders and use separate visual representations for understanding and generation, creating misalignment between the two tasks and preventing fully end-to-end optimization from raw pixels. We introduce Tuna-2, a native unified multimodal model that performs visual understanding and generation directly based on pixel embeddings. Tuna-2 drastically simplifies the model architecture by employing simple patch embedding layers to encode visual input, completely discarding the modular vision encoder designs such as the VAE or the representation encoder. Experiments show that Tuna-2 achieves state-of-the-art performance in multimodal benchmarks, demonstrating that unified pixel-space modelling can fully compete with latent-space approaches for high-quality image generation. Moreover, while the encoder-based variant converges faster in early pretraining, Tuna-2's encoder-free design achieves stronger multimodal understanding at scale, particularly on tasks requiring fine-grained visual perception. These results show that pretrained vision encoders are not necessary for multimodal modelling, and end-to-end pixel-space learning offers a scalable path toward stronger visual representations for both generation and perception.
TransText: Alpha-as-RGB Representation for Transparent Text Animation
Mar 19, 2026We introduce the first method, to the best of our knowledge, for adapting image-to-video models to layer-aware text (glyph) animation, a capability critical for practical dynamic visual design. Existing approaches predominantly handle the transparency-encoding (alpha channel) as an extra latent dimension appended to the RGB space, necessitating the reconstruction of the underlying RGB-centric variational autoencoder (VAE). However, given the scarcity of high-quality transparent glyph data, retraining the VAE is computationally expensive and may erode the robust semantic priors learned from massive RGB corpora, potentially leading to latent pattern mixing. To mitigate these limitations, we propose TransText, a framework based on a novel Alpha-as-RGB paradigm to jointly model appearance and transparency without modifying the pre-trained generative manifold. TransText embeds the alpha channel as an RGB-compatible visual signal through latent spatial concatenation, explicitly ensuring strict cross-modal (RGB-and-Alpha) consistency while preventing feature entanglement. Our experiments demonstrate that TransText significantly outperforms baselines, generating coherent, high-fidelity transparent animations with diverse, fine-grained effects.
VecGlypher: Unified Vector Glyph Generation with Language Models
Feb 25, 2026Vector glyphs are the atomic units of digital typography, yet most learning-based pipelines still depend on carefully curated exemplar sheets and raster-to-vector postprocessing, which limits accessibility and editability. We introduce VecGlypher, a single multimodal language model that generates high-fidelity vector glyphs directly from text descriptions or image exemplars. Given a style prompt, optional reference glyph images, and a target character, VecGlypher autoregressively emits SVG path tokens, avoiding raster intermediates and producing editable, watertight outlines in one pass. A typography-aware data and training recipe makes this possible: (i) a large-scale continuation stage on 39K noisy Envato fonts to master SVG syntax and long-horizon geometry, followed by (ii) post-training on 2.5K expert-annotated Google Fonts with descriptive tags and exemplars to align language and imagery with geometry; preprocessing normalizes coordinate frames, canonicalizes paths, de-duplicates families, and quantizes coordinates for stable long-sequence decoding. On cross-family OOD evaluation, VecGlypher substantially outperforms both general-purpose LLMs and specialized vector-font baselines for text-only generation, while image-referenced generation reaches a state-of-the-art performance, with marked gains over DeepVecFont-v2 and DualVector. Ablations show that model scale and the two-stage recipe are critical and that absolute-coordinate serialization yields the best geometry. VecGlypher lowers the barrier to font creation by letting users design with words or exemplars, and provides a scalable foundation for future multimodal design tools.
Bridging Structure and Appearance: Topological Features for Robust Self-Supervised Segmentation
Dec 30, 2025Self-supervised semantic segmentation methods often fail when faced with appearance ambiguities. We argue that this is due to an over-reliance on unstable, appearance-based features such as shadows, glare, and local textures. We propose \textbf{GASeg}, a novel framework that bridges appearance and geometry by leveraging stable topological information. The core of our method is Differentiable Box-Counting (\textbf{DBC}) module, which quantifies multi-scale topological statistics from two parallel streams: geometric-based features and appearance-based features. To force the model to learn these stable structural representations, we introduce Topological Augmentation (\textbf{TopoAug}), an adversarial strategy that simulates real-world ambiguities by applying morphological operators to the input images. A multi-objective loss, \textbf{GALoss}, then explicitly enforces cross-modal alignment between geometric-based and appearance-based features. Extensive experiments demonstrate that GASeg achieves state-of-the-art performance on four benchmarks, including COCO-Stuff, Cityscapes, and PASCAL, validating our approach of bridging geometry and appearance via topological information.
HiStream: Efficient High-Resolution Video Generation via Redundancy-Eliminated Streaming
Dec 24, 2025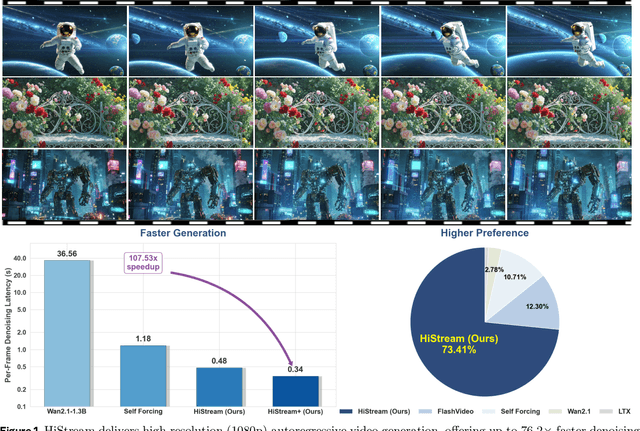
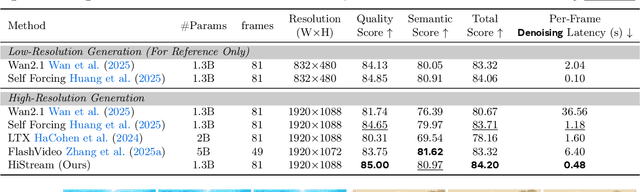
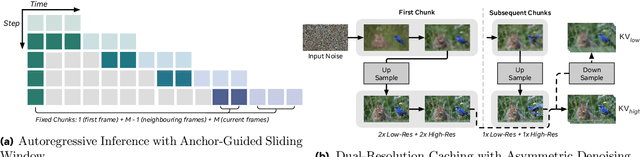
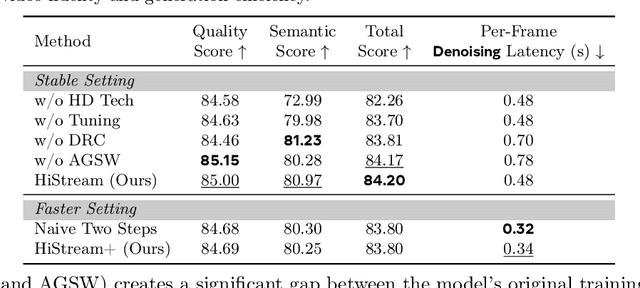
High-resolution video generation, while crucial for digital media and film, is computationally bottlenecked by the quadratic complexity of diffusion models, making practical inference infeasible. To address this, we introduce HiStream, an efficient autoregressive framework that systematically reduces redundancy across three axes: i) Spatial Compression: denoising at low resolution before refining at high resolution with cached features; ii) Temporal Compression: a chunk-by-chunk strategy with a fixed-size anchor cache, ensuring stable inference speed; and iii) Timestep Compression: applying fewer denoising steps to subsequent, cache-conditioned chunks. On 1080p benchmarks, our primary HiStream model (i+ii) achieves state-of-the-art visual quality while demonstrating up to 76.2x faster denoising compared to the Wan2.1 baseline and negligible quality loss. Our faster variant, HiStream+, applies all three optimizations (i+ii+iii), achieving a 107.5x acceleration over the baseline, offering a compelling trade-off between speed and quality, thereby making high-resolution video generation both practical and scalable.
OneStory: Coherent Multi-Shot Video Generation with Adaptive Memory
Dec 08, 2025
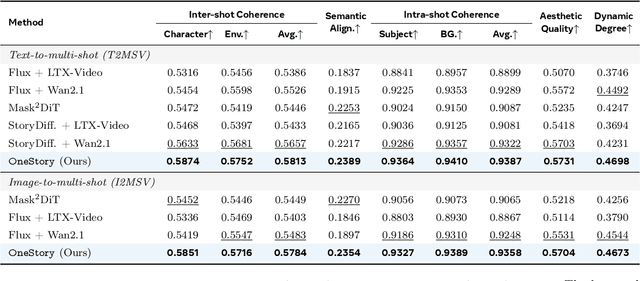
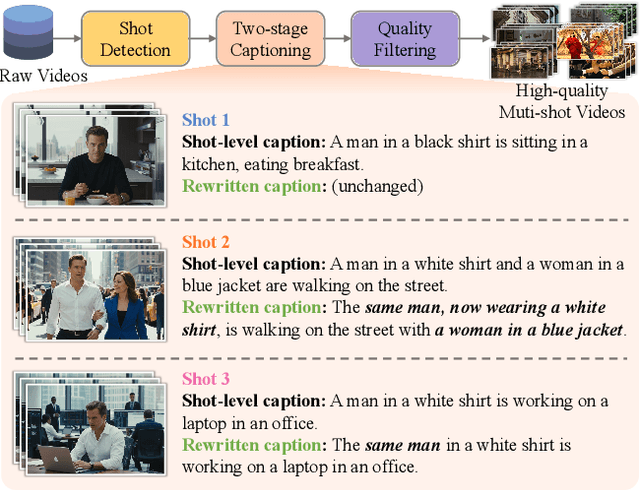

Storytelling in real-world videos often unfolds through multiple shots -- discontinuous yet semantically connected clips that together convey a coherent narrative. However, existing multi-shot video generation (MSV) methods struggle to effectively model long-range cross-shot context, as they rely on limited temporal windows or single keyframe conditioning, leading to degraded performance under complex narratives. In this work, we propose OneStory, enabling global yet compact cross-shot context modeling for consistent and scalable narrative generation. OneStory reformulates MSV as a next-shot generation task, enabling autoregressive shot synthesis while leveraging pretrained image-to-video (I2V) models for strong visual conditioning. We introduce two key modules: a Frame Selection module that constructs a semantically-relevant global memory based on informative frames from prior shots, and an Adaptive Conditioner that performs importance-guided patchification to generate compact context for direct conditioning. We further curate a high-quality multi-shot dataset with referential captions to mirror real-world storytelling patterns, and design effective training strategies under the next-shot paradigm. Finetuned from a pretrained I2V model on our curated 60K dataset, OneStory achieves state-of-the-art narrative coherence across diverse and complex scenes in both text- and image-conditioned settings, enabling controllable and immersive long-form video storytelling.
Mixture of States: Routing Token-Level Dynamics for Multimodal Generation
Nov 15, 2025We introduce MoS (Mixture of States), a novel fusion paradigm for multimodal diffusion models that merges modalities using flexible, state-based interactions. The core of MoS is a learnable, token-wise router that creates denoising timestep- and input-dependent interactions between modalities' hidden states, precisely aligning token-level features with the diffusion trajectory. This router sparsely selects the top-$k$ hidden states and is trained with an $ε$-greedy strategy, efficiently selecting contextual features with minimal learnable parameters and negligible computational overhead. We validate our design with text-to-image generation (MoS-Image) and editing (MoS-Editing), which achieve state-of-the-art results. With only 3B to 5B parameters, our models match or surpass counterparts up to $4\times$ larger. These findings establish MoS as a flexible and compute-efficient paradigm for scaling multimodal diffusion models.
DynamicLip: Shape-Independent Continuous Authentication via Lip Articulator Dynamics
Jan 02, 2025Biometrics authentication has become increasingly popular due to its security and convenience; however, traditional biometrics are becoming less desirable in scenarios such as new mobile devices, Virtual Reality, and Smart Vehicles. For example, while face authentication is widely used, it suffers from significant privacy concerns. The collection of complete facial data makes it less desirable for privacy-sensitive applications. Lip authentication, on the other hand, has emerged as a promising biometrics method. However, existing lip-based authentication methods heavily depend on static lip shape when the mouth is closed, which can be less robust due to lip shape dynamic motion and can barely work when the user is speaking. In this paper, we revisit the nature of lip biometrics and extract shape-independent features from the lips. We study the dynamic characteristics of lip biometrics based on articulator motion. Building on the knowledge, we propose a system for shape-independent continuous authentication via lip articulator dynamics. This system enables robust, shape-independent and continuous authentication, making it particularly suitable for scenarios with high security and privacy requirements. We conducted comprehensive experiments in different environments and attack scenarios and collected a dataset of 50 subjects. The results indicate that our system achieves an overall accuracy of 99.06% and demonstrates robustness under advanced mimic attacks and AI deepfake attacks, making it a viable solution for continuous biometric authentication in various applications.
Learning Flow Fields in Attention for Controllable Person Image Generation
Dec 12, 2024
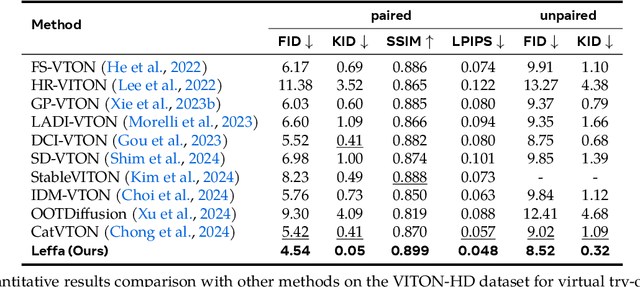
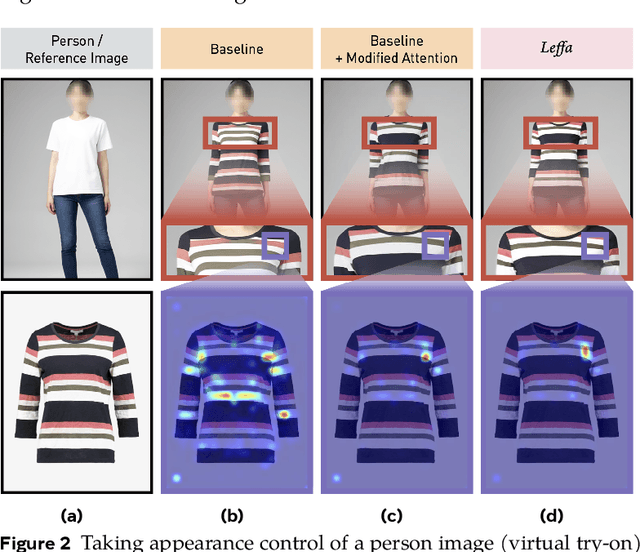
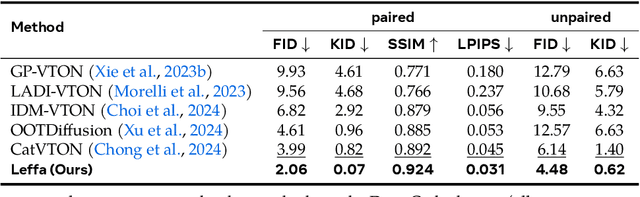
Controllable person image generation aims to generate a person image conditioned on reference images, allowing precise control over the person's appearance or pose. However, prior methods often distort fine-grained textural details from the reference image, despite achieving high overall image quality. We attribute these distortions to inadequate attention to corresponding regions in the reference image. To address this, we thereby propose learning flow fields in attention (Leffa), which explicitly guides the target query to attend to the correct reference key in the attention layer during training. Specifically, it is realized via a regularization loss on top of the attention map within a diffusion-based baseline. Our extensive experiments show that Leffa achieves state-of-the-art performance in controlling appearance (virtual try-on) and pose (pose transfer), significantly reducing fine-grained detail distortion while maintaining high image quality. Additionally, we show that our loss is model-agnostic and can be used to improve the performance of other diffusion models.