 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHiStream: Efficient High-Resolution Video Generation via Redundancy-Eliminated Streaming
Dec 24, 2025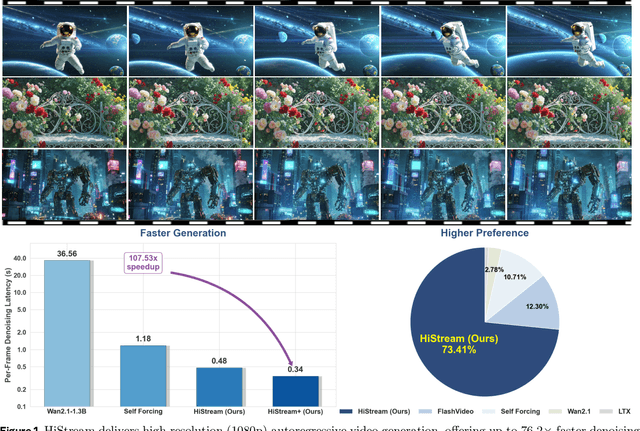
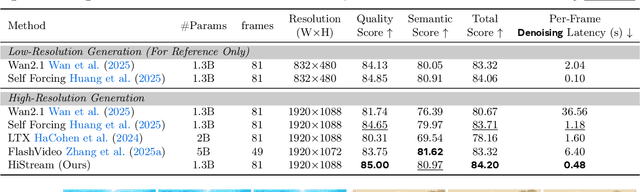
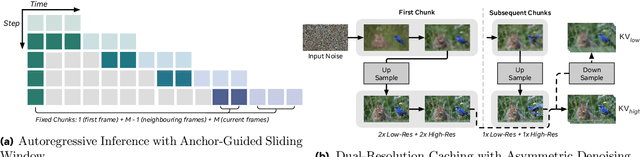
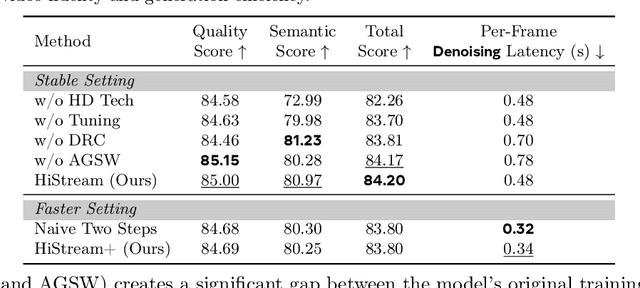
High-resolution video generation, while crucial for digital media and film, is computationally bottlenecked by the quadratic complexity of diffusion models, making practical inference infeasible. To address this, we introduce HiStream, an efficient autoregressive framework that systematically reduces redundancy across three axes: i) Spatial Compression: denoising at low resolution before refining at high resolution with cached features; ii) Temporal Compression: a chunk-by-chunk strategy with a fixed-size anchor cache, ensuring stable inference speed; and iii) Timestep Compression: applying fewer denoising steps to subsequent, cache-conditioned chunks. On 1080p benchmarks, our primary HiStream model (i+ii) achieves state-of-the-art visual quality while demonstrating up to 76.2x faster denoising compared to the Wan2.1 baseline and negligible quality loss. Our faster variant, HiStream+, applies all three optimizations (i+ii+iii), achieving a 107.5x acceleration over the baseline, offering a compelling trade-off between speed and quality, thereby making high-resolution video generation both practical and scalable.
Hyper-VolTran: Fast and Generalizable One-Shot Image to 3D Object Structure via HyperNetworks
Jan 05, 2024



Solving image-to-3D from a single view is an ill-posed problem, and current neural reconstruction methods addressing it through diffusion models still rely on scene-specific optimization, constraining their generalization capability. To overcome the limitations of existing approaches regarding generalization and consistency, we introduce a novel neural rendering technique. Our approach employs the signed distance function as the surface representation and incorporates generalizable priors through geometry-encoding volumes and HyperNetworks. Specifically, our method builds neural encoding volumes from generated multi-view inputs. We adjust the weights of the SDF network conditioned on an input image at test-time to allow model adaptation to novel scenes in a feed-forward manner via HyperNetworks. To mitigate artifacts derived from the synthesized views, we propose the use of a volume transformer module to improve the aggregation of image features instead of processing each viewpoint separately. Through our proposed method, dubbed as Hyper-VolTran, we avoid the bottleneck of scene-specific optimization and maintain consistency across the images generated from multiple viewpoints. Our experiments show the advantages of our proposed approach with consistent results and rapid generation.
GenTron: Delving Deep into Diffusion Transformers for Image and Video Generation
Dec 07, 2023



In this study, we explore Transformer-based diffusion models for image and video generation. Despite the dominance of Transformer architectures in various fields due to their flexibility and scalability, the visual generative domain primarily utilizes CNN-based U-Net architectures, particularly in diffusion-based models. We introduce GenTron, a family of Generative models employing Transformer-based diffusion, to address this gap. Our initial step was to adapt Diffusion Transformers (DiTs) from class to text conditioning, a process involving thorough empirical exploration of the conditioning mechanism. We then scale GenTron from approximately 900M to over 3B parameters, observing significant improvements in visual quality. Furthermore, we extend GenTron to text-to-video generation, incorporating novel motion-free guidance to enhance video quality. In human evaluations against SDXL, GenTron achieves a 51.1% win rate in visual quality (with a 19.8% draw rate), and a 42.3% win rate in text alignment (with a 42.9% draw rate). GenTron also excels in the T2I-CompBench, underscoring its strengths in compositional generation. We believe this work will provide meaningful insights and serve as a valuable reference for future research.
FLATTEN: optical FLow-guided ATTENtion for consistent text-to-video editing
Oct 09, 2023

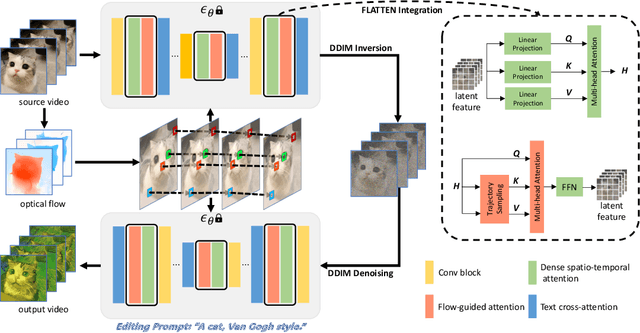

Text-to-video editing aims to edit the visual appearance of a source video conditional on textual prompts. A major challenge in this task is to ensure that all frames in the edited video are visually consistent. Most recent works apply advanced text-to-image diffusion models to this task by inflating 2D spatial attention in the U-Net into spatio-temporal attention. Although temporal context can be added through spatio-temporal attention, it may introduce some irrelevant information for each patch and therefore cause inconsistency in the edited video. In this paper, for the first time, we introduce optical flow into the attention module in the diffusion model's U-Net to address the inconsistency issue for text-to-video editing. Our method, FLATTEN, enforces the patches on the same flow path across different frames to attend to each other in the attention module, thus improving the visual consistency in the edited videos. Additionally, our method is training-free and can be seamlessly integrated into any diffusion-based text-to-video editing methods and improve their visual consistency. Experiment results on existing text-to-video editing benchmarks show that our proposed method achieves the new state-of-the-art performance. In particular, our method excels in maintaining the visual consistency in the edited videos.
Multi-Modal Few-Shot Temporal Action Detection via Vision-Language Meta-Adaptation
Nov 27, 2022



Few-shot (FS) and zero-shot (ZS) learning are two different approaches for scaling temporal action detection (TAD) to new classes. The former adapts a pretrained vision model to a new task represented by as few as a single video per class, whilst the latter requires no training examples by exploiting a semantic description of the new class. In this work, we introduce a new multi-modality few-shot (MMFS) TAD problem, which can be considered as a marriage of FS-TAD and ZS-TAD by leveraging few-shot support videos and new class names jointly. To tackle this problem, we further introduce a novel MUlti-modality PromPt mETa-learning (MUPPET) method. This is enabled by efficiently bridging pretrained vision and language models whilst maximally reusing already learned capacity. Concretely, we construct multi-modal prompts by mapping support videos into the textual token space of a vision-language model using a meta-learned adapter-equipped visual semantics tokenizer. To tackle large intra-class variation, we further design a query feature regulation scheme. Extensive experiments on ActivityNetv1.3 and THUMOS14 demonstrate that our MUPPET outperforms state-of-the-art alternative methods, often by a large margin. We also show that our MUPPET can be easily extended to tackle the few-shot object detection problem and again achieves the state-of-the-art performance on MS-COCO dataset. The code will be available in https://github.com/sauradip/MUPPET
Where is my Wallet? Modeling Object Proposal Sets for Egocentric Visual Query Localization
Nov 18, 2022



This paper deals with the problem of localizing objects in image and video datasets from visual exemplars. In particular, we focus on the challenging problem of egocentric visual query localization. We first identify grave implicit biases in current query-conditioned model design and visual query datasets. Then, we directly tackle such biases at both frame and object set levels. Concretely, our method solves these issues by expanding limited annotations and dynamically dropping object proposals during training. Additionally, we propose a novel transformer-based module that allows for object-proposal set context to be considered while incorporating query information. We name our module Conditioned Contextual Transformer or CocoFormer. Our experiments show the proposed adaptations improve egocentric query detection, leading to a better visual query localization system in both 2D and 3D configurations. Thus, we are able to improve frame-level detection performance from 26.28% to 31.26 in AP, which correspondingly improves the VQ2D and VQ3D localization scores by significant margins. Our improved context-aware query object detector ranked first and second in the VQ2D and VQ3D tasks in the 2nd Ego4D challenge. In addition to this, we showcase the relevance of our proposed model in the Few-Shot Detection (FSD) task, where we also achieve SOTA results. Our code is available at https://github.com/facebookresearch/vq2d_cvpr.
Negative Frames Matter in Egocentric Visual Query 2D Localization
Aug 03, 2022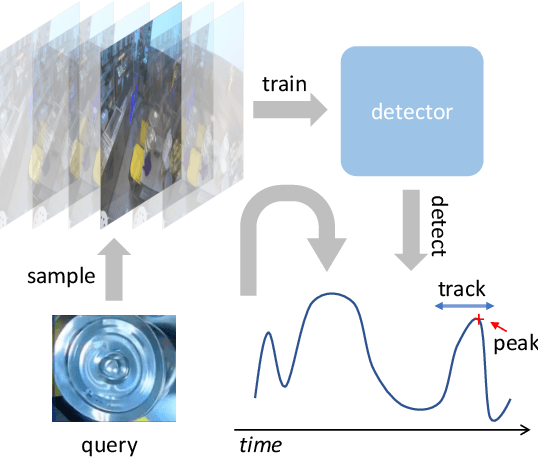
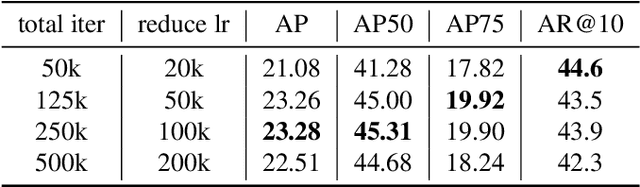

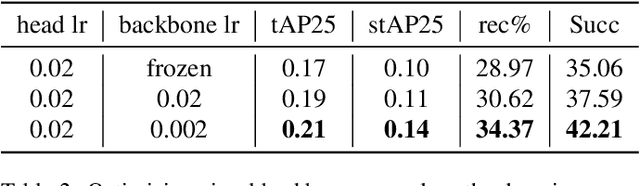
The recently released Ego4D dataset and benchmark significantly scales and diversifies the first-person visual perception data. In Ego4D, the Visual Queries 2D Localization task aims to retrieve objects appeared in the past from the recording in the first-person view. This task requires a system to spatially and temporally localize the most recent appearance of a given object query, where query is registered by a single tight visual crop of the object in a different scene. Our study is based on the three-stage baseline introduced in the Episodic Memory benchmark. The baseline solves the problem by detection and tracking: detect the similar objects in all the frames, then run a tracker from the most confident detection result. In the VQ2D challenge, we identified two limitations of the current baseline. (1) The training configuration has redundant computation. Although the training set has millions of instances, most of them are repetitive and the number of unique object is only around 14.6k. The repeated gradient computation of the same object lead to an inefficient training; (2) The false positive rate is high on background frames. This is due to the distribution gap between training and evaluation. During training, the model is only able to see the clean, stable, and labeled frames, but the egocentric videos also have noisy, blurry, or unlabeled background frames. To this end, we developed a more efficient and effective solution. Concretely, we bring the training loop from ~15 days to less than 24 hours, and we achieve 0.17% spatial-temporal AP, which is 31% higher than the baseline. Our solution got the first ranking on the public leaderboard. Our code is publicly available at https://github.com/facebookresearch/vq2d_cvpr.
SAIC_Cambridge-HuPBA-FBK Submission to the EPIC-Kitchens-100 Action Recognition Challenge 2021
Oct 06, 2021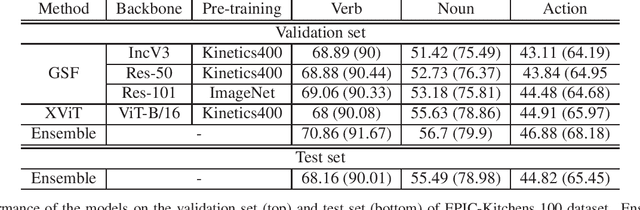
This report presents the technical details of our submission to the EPIC-Kitchens-100 Action Recognition Challenge 2021. To participate in the challenge we deployed spatio-temporal feature extraction and aggregation models we have developed recently: GSF and XViT. GSF is an efficient spatio-temporal feature extracting module that can be plugged into 2D CNNs for video action recognition. XViT is a convolution free video feature extractor based on transformer architecture. We design an ensemble of GSF and XViT model families with different backbones and pretraining to generate the prediction scores. Our submission, visible on the public leaderboard, achieved a top-1 action recognition accuracy of 44.82%, using only RGB.
TNT: Text-Conditioned Network with Transductive Inference for Few-Shot Video Classification
Jun 21, 2021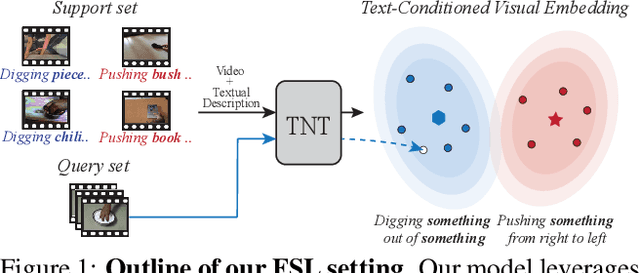
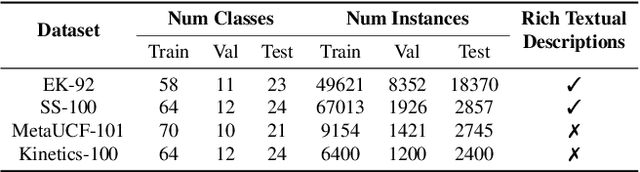
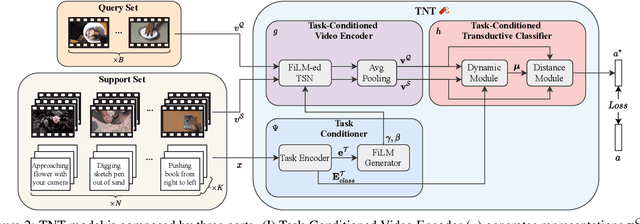
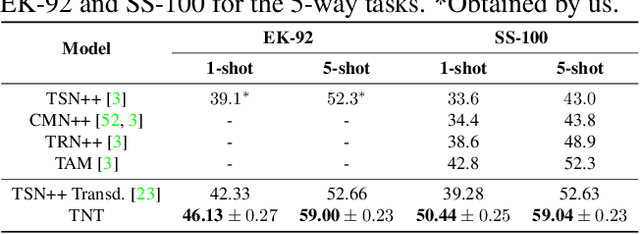
Recently, few-shot learning has received increasing interest. Existing efforts have been focused on image classification, with very few attempts dedicated to the more challenging few-shot video classification problem. These few attempts aim to effectively exploit the temporal dimension in videos for better learning in low data regimes. However, they have largely ignored a key characteristic of video which could be vital for few-shot recognition, that is, videos are often accompanied by rich text descriptions. In this paper, for the first time, we propose to leverage these human-provided textual descriptions as privileged information when training a few-shot video classification model. Specifically, we formulate a text-based task conditioner to adapt video features to the few-shot learning task. Our model follows a transductive setting where query samples and support textual descriptions can be used to update the support set class prototype to further improve the task-adaptation ability of the model. Our model obtains state-of-the-art performance on four challenging benchmarks in few-shot video action classification.
Space-time Mixing Attention for Video Transformer
Jun 11, 2021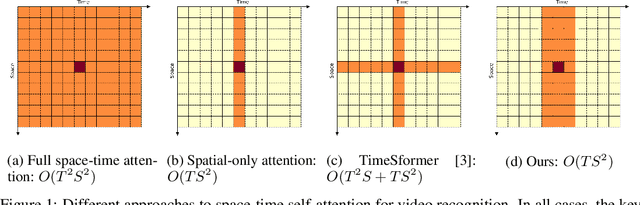
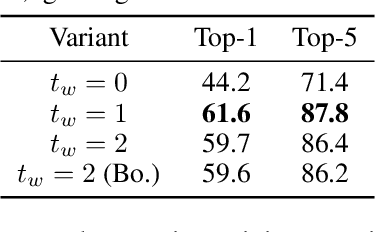


This paper is on video recognition using Transformers. Very recent attempts in this area have demonstrated promising results in terms of recognition accuracy, yet they have been also shown to induce, in many cases, significant computational overheads due to the additional modelling of the temporal information. In this work, we propose a Video Transformer model the complexity of which scales linearly with the number of frames in the video sequence and hence induces no overhead compared to an image-based Transformer model. To achieve this, our model makes two approximations to the full space-time attention used in Video Transformers: (a) It restricts time attention to a local temporal window and capitalizes on the Transformer's depth to obtain full temporal coverage of the video sequence. (b) It uses efficient space-time mixing to attend jointly spatial and temporal locations without inducing any additional cost on top of a spatial-only attention model. We also show how to integrate 2 very lightweight mechanisms for global temporal-only attention which provide additional accuracy improvements at minimal computational cost. We demonstrate that our model produces very high recognition accuracy on the most popular video recognition datasets while at the same time being significantly more efficient than other Video Transformer models. Code will be made available.