 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelevance-based Margin for Contrastively-trained Video Retrieval Models
Apr 27, 2022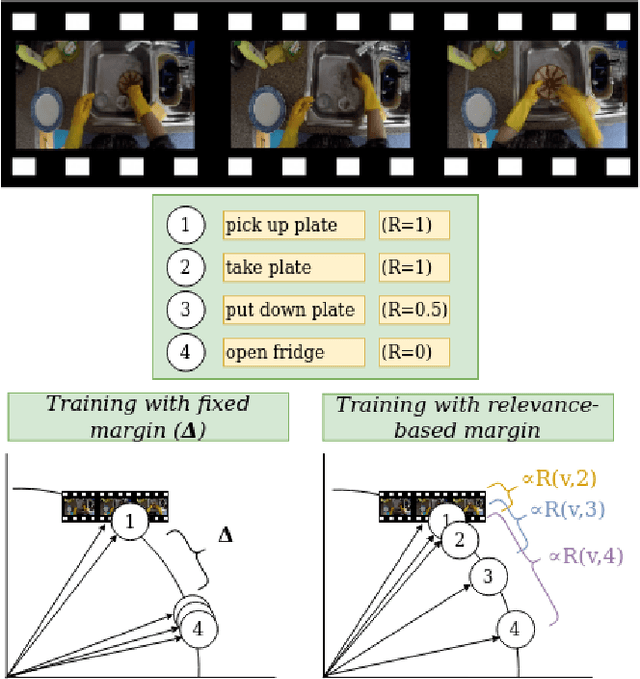
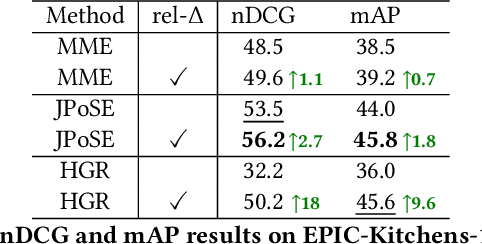
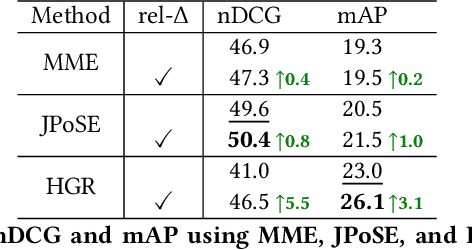
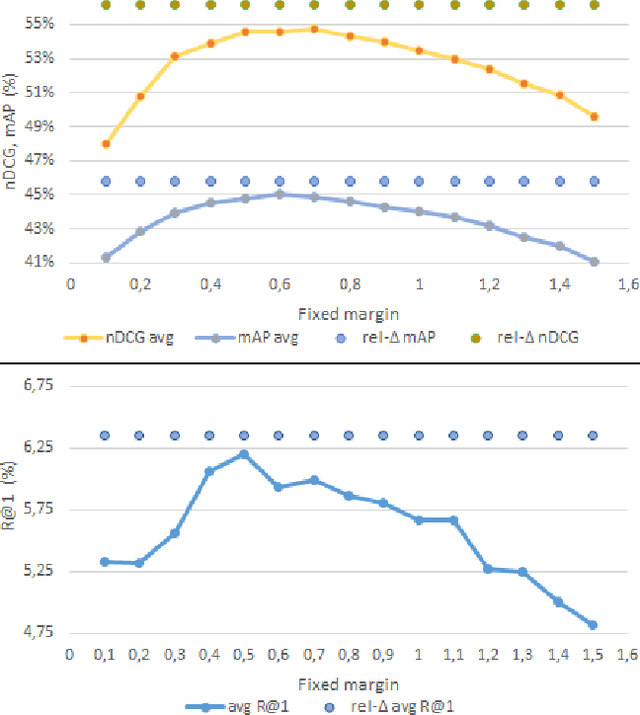
Video retrieval using natural language queries has attracted increasing interest due to its relevance in real-world applications, from intelligent access in private media galleries to web-scale video search. Learning the cross-similarity of video and text in a joint embedding space is the dominant approach. To do so, a contrastive loss is usually employed because it organizes the embedding space by putting similar items close and dissimilar items far. This framework leads to competitive recall rates, as they solely focus on the rank of the groundtruth items. Yet, assessing the quality of the ranking list is of utmost importance when considering intelligent retrieval systems, since multiple items may share similar semantics, hence a high relevance. Moreover, the aforementioned framework uses a fixed margin to separate similar and dissimilar items, treating all non-groundtruth items as equally irrelevant. In this paper we propose to use a variable margin: we argue that varying the margin used during training based on how much relevant an item is to a given query, i.e. a relevance-based margin, easily improves the quality of the ranking lists measured through nDCG and mAP. We demonstrate the advantages of our technique using different models on EPIC-Kitchens-100 and YouCook2. We show that even if we carefully tuned the fixed margin, our technique (which does not have the margin as a hyper-parameter) would still achieve better performance. Finally, extensive ablation studies and qualitative analysis support the robustness of our approach. Code will be released at \url{https://github.com/aranciokov/RelevanceMargin-ICMR22}.
Gate-Shift-Fuse for Video Action Recognition
Mar 16, 2022



Convolutional Neural Networks are the de facto models for image recognition. However 3D CNNs, the straight forward extension of 2D CNNs for video recognition, have not achieved the same success on standard action recognition benchmarks. One of the main reasons for this reduced performance of 3D CNNs is the increased computational complexity requiring large scale annotated datasets to train them in scale. 3D kernel factorization approaches have been proposed to reduce the complexity of 3D CNNs. Existing kernel factorization approaches follow hand-designed and hard-wired techniques. In this paper we propose Gate-Shift-Fuse (GSF), a novel spatio-temporal feature extraction module which controls interactions in spatio-temporal decomposition and learns to adaptively route features through time and combine them in a data dependent manner. GSF leverages grouped spatial gating to decompose input tensor and channel weighting to fuse the decomposed tensors. GSF can be inserted into existing 2D CNNs to convert them into an efficient and high performing spatio-temporal feature extractor, with negligible parameter and compute overhead. We perform an extensive analysis of GSF using two popular 2D CNN families and achieve state-of-the-art or competitive performance on five standard action recognition benchmarks. Code and models will be made publicly available at https://github.com/swathikirans/GSF.
SAIC_Cambridge-HuPBA-FBK Submission to the EPIC-Kitchens-100 Action Recognition Challenge 2021
Oct 06, 2021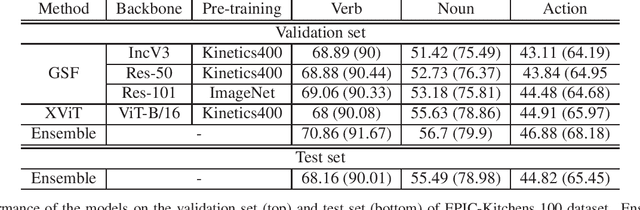
This report presents the technical details of our submission to the EPIC-Kitchens-100 Action Recognition Challenge 2021. To participate in the challenge we deployed spatio-temporal feature extraction and aggregation models we have developed recently: GSF and XViT. GSF is an efficient spatio-temporal feature extracting module that can be plugged into 2D CNNs for video action recognition. XViT is a convolution free video feature extractor based on transformer architecture. We design an ensemble of GSF and XViT model families with different backbones and pretraining to generate the prediction scores. Our submission, visible on the public leaderboard, achieved a top-1 action recognition accuracy of 44.82%, using only RGB.
Space-time Mixing Attention for Video Transformer
Jun 11, 2021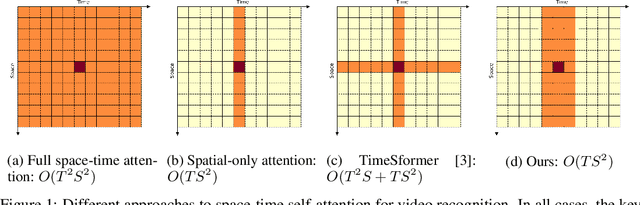
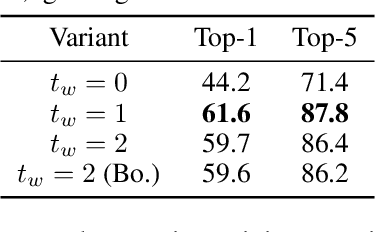


This paper is on video recognition using Transformers. Very recent attempts in this area have demonstrated promising results in terms of recognition accuracy, yet they have been also shown to induce, in many cases, significant computational overheads due to the additional modelling of the temporal information. In this work, we propose a Video Transformer model the complexity of which scales linearly with the number of frames in the video sequence and hence induces no overhead compared to an image-based Transformer model. To achieve this, our model makes two approximations to the full space-time attention used in Video Transformers: (a) It restricts time attention to a local temporal window and capitalizes on the Transformer's depth to obtain full temporal coverage of the video sequence. (b) It uses efficient space-time mixing to attend jointly spatial and temporal locations without inducing any additional cost on top of a spatial-only attention model. We also show how to integrate 2 very lightweight mechanisms for global temporal-only attention which provide additional accuracy improvements at minimal computational cost. We demonstrate that our model produces very high recognition accuracy on the most popular video recognition datasets while at the same time being significantly more efficient than other Video Transformer models. Code will be made available.
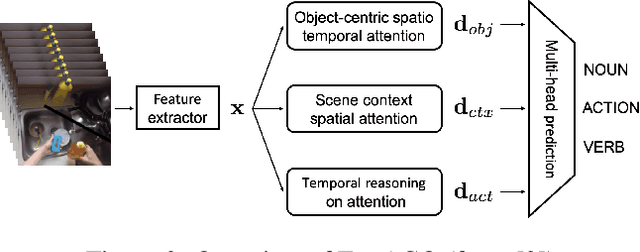
Learning to Recognize Actions on Objects in Egocentric Video with Attention Dictionaries
Feb 16, 2021

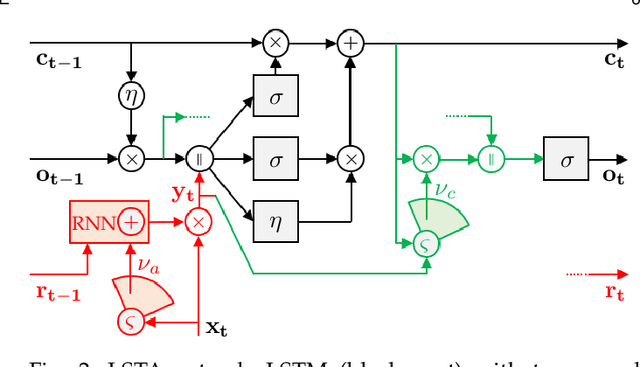

We present EgoACO, a deep neural architecture for video action recognition that learns to pool action-context-object descriptors from frame level features by leveraging the verb-noun structure of action labels in egocentric video datasets. The core component of EgoACO is class activation pooling (CAP), a differentiable pooling operation that combines ideas from bilinear pooling for fine-grained recognition and from feature learning for discriminative localization. CAP uses self-attention with a dictionary of learnable weights to pool from the most relevant feature regions. Through CAP, EgoACO learns to decode object and scene context descriptors from video frame features. For temporal modeling in EgoACO, we design a recurrent version of class activation pooling termed Long Short-Term Attention (LSTA). LSTA extends convolutional gated LSTM with built-in spatial attention and a re-designed output gate. Action, object and context descriptors are fused by a multi-head prediction that accounts for the inter-dependencies between noun-verb-action structured labels in egocentric video datasets. EgoACO features built-in visual explanations, helping learning and interpretation. Results on the two largest egocentric action recognition datasets currently available, EPIC-KITCHENS and EGTEA, show that by explicitly decoding action-context-object descriptors, EgoACO achieves state-of-the-art recognition performance.
FBK-HUPBA Submission to the EPIC-Kitchens Action Recognition 2020 Challenge
Jun 24, 2020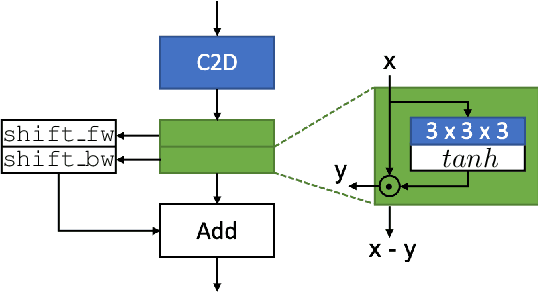

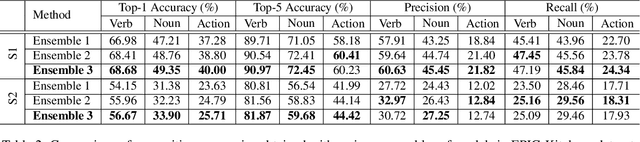
In this report we describe the technical details of our submission to the EPIC-Kitchens Action Recognition 2020 Challenge. To participate in the challenge we deployed spatio-temporal feature extraction and aggregation models we have developed recently: Gate-Shift Module (GSM) [1] and EgoACO, an extension of Long Short-Term Attention (LSTA) [2]. We design an ensemble of GSM and EgoACO model families with different backbones and pre-training to generate the prediction scores. Our submission, visible on the public leaderboard with team name FBK-HUPBA, achieved a top-1 action recognition accuracy of 40.0% on S1 setting, and 25.71% on S2 setting, using only RGB.
Gate-Shift Networks for Video Action Recognition
Dec 01, 2019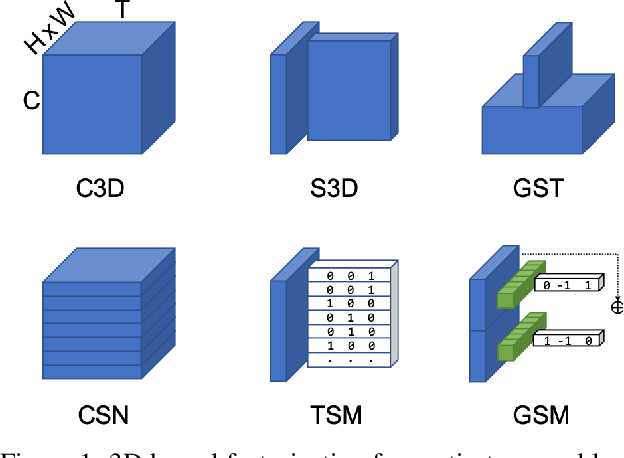

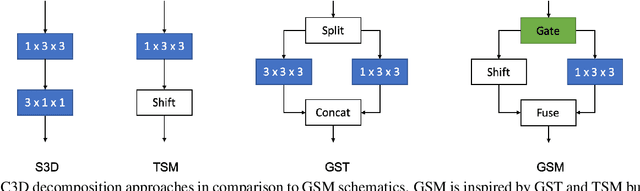
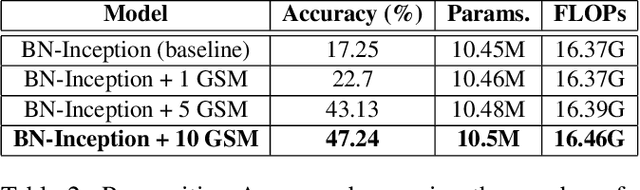
Deep 3D CNNs for video action recognition are designed to learn powerful representations in the joint spatio-temporal feature space. In practice however, because of the large number of parameters and computations involved, they may under-perform in the lack of sufficiently large datasets for training them at scale. In this paper we introduce spatial gating in spatial-temporal decomposition of 3D kernels. We implement this concept with Gate-Shift Module (GSM). GSM is lightweight and turns a 2D-CNN into a highly efficient spatio-temporal feature extractor. With GSM plugged in, a 2D-CNN learns to adaptively route features through time and combine them, at almost no additional parameters and computational overhead. We perform an extensive evaluation of the proposed module to study its effectiveness in video action recognition, achieving state-of-the-art results on Something Something-V1 and Diving48 datasets, and obtaining competitive results on EPIC-Kitchens with far less model complexity. With GSM plugged into TSN, on Something Something-V1 we obtain an absolute +32% boost in recognition accuracy (from 17.52% to 49.56%) with less than 1% additional parameters and computations. By ensembling models trained at different temporal scales, we reach beyond 55%.
An Analysis of Deep Neural Networks with Attention for Action Recognition from a Neurophysiological Perspective
Jul 02, 2019

We review three recent deep learning based methods for action recognition and present a brief comparative analysis of the methods from a neurophyisiological point of view. We posit that there are some analogy between the three presented deep learning based methods and some of the existing hypotheses regarding the functioning of human brain.
FBK-HUPBA Submission to the EPIC-Kitchens 2019 Action Recognition Challenge
Jun 21, 2019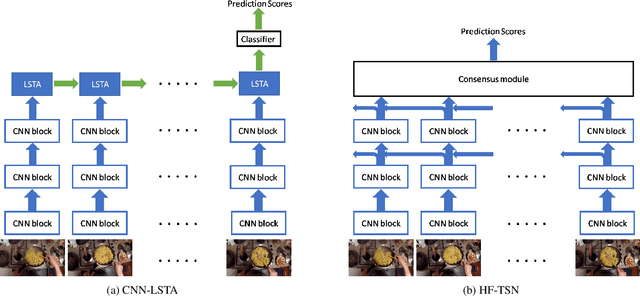
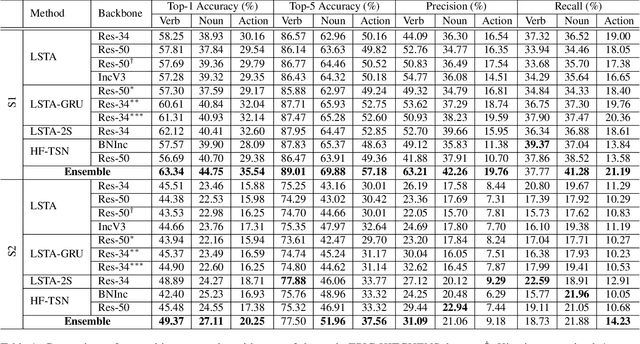
In this report we describe the technical details of our submission to the EPIC-Kitchens 2019 action recognition challenge. To participate in the challenge we have developed a number of CNN-LSTA [3] and HF-TSN [2] variants, and submitted predictions from an ensemble compiled out of these two model families. Our submission, visible on the public leaderboard with team name FBK-HUPBA, achieved a top-1 action recognition accuracy of 35.54% on S1 setting, and 20.25% on S2 setting.
Hierarchical Feature Aggregation Networks for Video Action Recognition
May 29, 2019

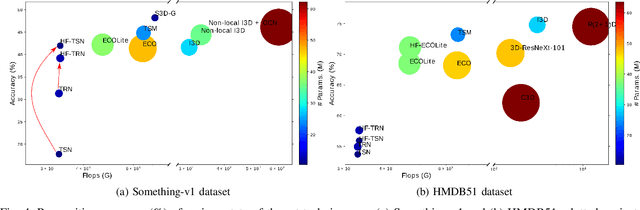

Most action recognition methods base on a) a late aggregation of frame level CNN features using average pooling, max pooling, or RNN, among others, or b) spatio-temporal aggregation via 3D convolutions. The first assume independence among frame features up to a certain level of abstraction and then perform higher-level aggregation, while the second extracts spatio-temporal features from grouped frames as early fusion. In this paper we explore the space in between these two, by letting adjacent feature branches interact as they develop into the higher level representation. The interaction happens between feature differencing and averaging at each level of the hierarchy, and it has convolutional structure that learns to select the appropriate mode locally in contrast to previous works that impose one of the modes globally (e.g. feature differencing) as a design choice. We further constrain this interaction to be conservative, e.g. a local feature subtraction in one branch is compensated by the addition on another, such that the total feature flow is preserved. We evaluate the performance of our proposal on a number of existing models, i.e. TSN, TRN and ECO, to show its flexibility and effectiveness in improving action recognition performance.