 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Recognize Actions on Objects in Egocentric Video with Attention Dictionaries
Paper and Code


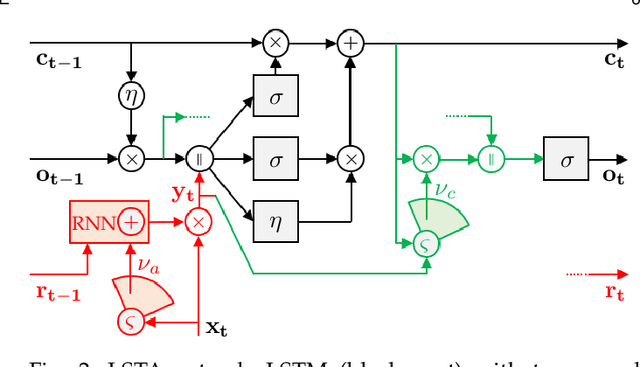

We present EgoACO, a deep neural architecture for video action recognition that learns to pool action-context-object descriptors from frame level features by leveraging the verb-noun structure of action labels in egocentric video datasets. The core component of EgoACO is class activation pooling (CAP), a differentiable pooling operation that combines ideas from bilinear pooling for fine-grained recognition and from feature learning for discriminative localization. CAP uses self-attention with a dictionary of learnable weights to pool from the most relevant feature regions. Through CAP, EgoACO learns to decode object and scene context descriptors from video frame features. For temporal modeling in EgoACO, we design a recurrent version of class activation pooling termed Long Short-Term Attention (LSTA). LSTA extends convolutional gated LSTM with built-in spatial attention and a re-designed output gate. Action, object and context descriptors are fused by a multi-head prediction that accounts for the inter-dependencies between noun-verb-action structured labels in egocentric video datasets. EgoACO features built-in visual explanations, helping learning and interpretation. Results on the two largest egocentric action recognition datasets currently available, EPIC-KITCHENS and EGTEA, show that by explicitly decoding action-context-object descriptors, EgoACO achieves state-of-the-art recognition performance.