 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGate-Shift Networks for Video Action Recognition
Paper and Code
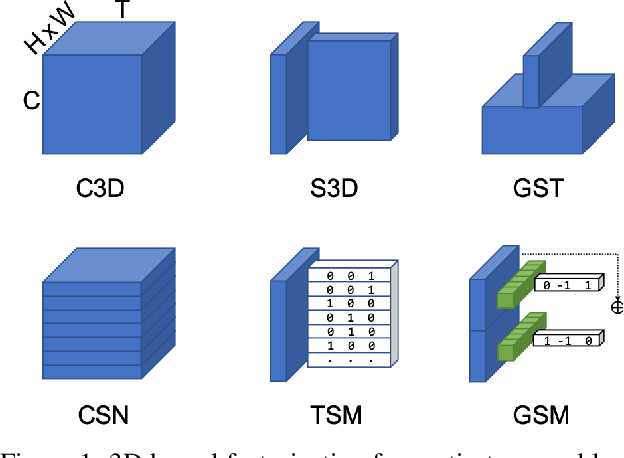

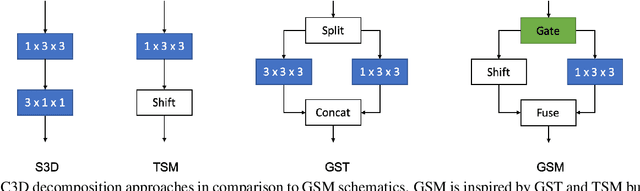
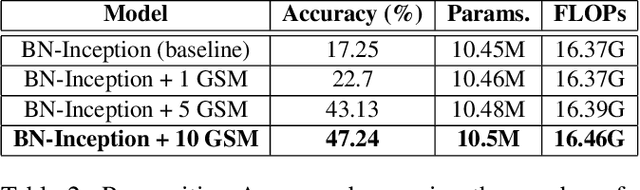
Deep 3D CNNs for video action recognition are designed to learn powerful representations in the joint spatio-temporal feature space. In practice however, because of the large number of parameters and computations involved, they may under-perform in the lack of sufficiently large datasets for training them at scale. In this paper we introduce spatial gating in spatial-temporal decomposition of 3D kernels. We implement this concept with Gate-Shift Module (GSM). GSM is lightweight and turns a 2D-CNN into a highly efficient spatio-temporal feature extractor. With GSM plugged in, a 2D-CNN learns to adaptively route features through time and combine them, at almost no additional parameters and computational overhead. We perform an extensive evaluation of the proposed module to study its effectiveness in video action recognition, achieving state-of-the-art results on Something Something-V1 and Diving48 datasets, and obtaining competitive results on EPIC-Kitchens with far less model complexity. With GSM plugged into TSN, on Something Something-V1 we obtain an absolute +32% boost in recognition accuracy (from 17.52% to 49.56%) with less than 1% additional parameters and computations. By ensembling models trained at different temporal scales, we reach beyond 55%.