 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Language-based solution to enable Metaverse Retrieval
Dec 22, 2023
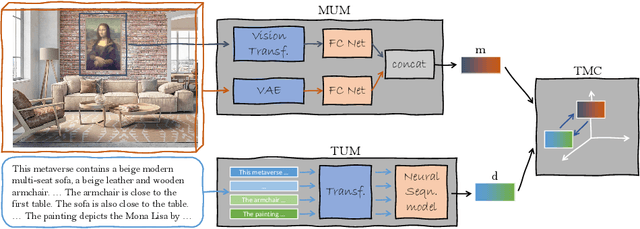

Recently, the Metaverse is becoming increasingly attractive, with millions of users accessing the many available virtual worlds. However, how do users find the one Metaverse which best fits their current interests? So far, the search process is mostly done by word of mouth, or by advertisement on technology-oriented websites. However, the lack of search engines similar to those available for other multimedia formats (e.g., YouTube for videos) is showing its limitations, since it is often cumbersome to find a Metaverse based on some specific interests using the available methods, while also making it difficult to discover user-created ones which lack strong advertisement. To address this limitation, we propose to use language to naturally describe the desired contents of the Metaverse a user wishes to find. Second, we highlight that, differently from more conventional 3D scenes, Metaverse scenarios represent a more complex data format since they often contain one or more types of multimedia which influence the relevance of the scenario itself to a user query. Therefore, in this work, we create a novel task, called Text-to-Metaverse retrieval, which aims at modeling these aspects while also taking the cross-modal relations with the textual data into account. Since we are the first ones to tackle this problem, we also collect a dataset of 33000 Metaverses, each of which consists of a 3D scene enriched with multimedia content. Finally, we design and implement a deep learning framework based on contrastive learning, resulting in a thorough experimental setup.
FArMARe: a Furniture-Aware Multi-task methodology for Recommending Apartments based on the user interests
Sep 06, 2023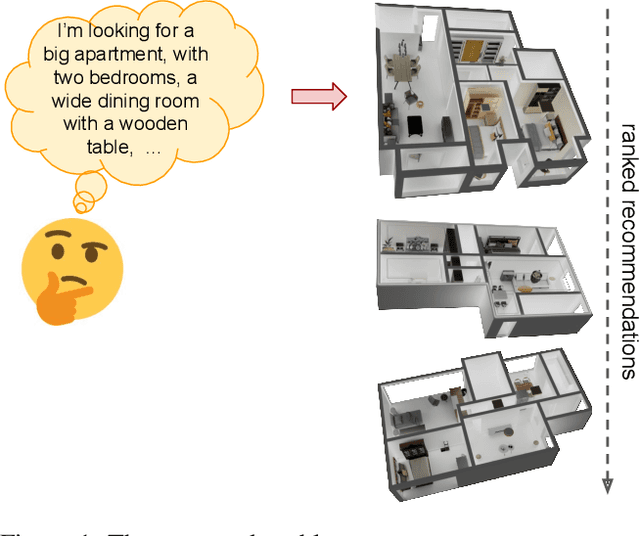



Nowadays, many people frequently have to search for new accommodation options. Searching for a suitable apartment is a time-consuming process, especially because visiting them is often mandatory to assess the truthfulness of the advertisements found on the Web. While this process could be alleviated by visiting the apartments in the metaverse, the Web-based recommendation platforms are not suitable for the task. To address this shortcoming, in this paper, we define a new problem called text-to-apartment recommendation, which requires ranking the apartments based on their relevance to a textual query expressing the user's interests. To tackle this problem, we introduce FArMARe, a multi-task approach that supports cross-modal contrastive training with a furniture-aware objective. Since public datasets related to indoor scenes do not contain detailed descriptions of the furniture, we collect and annotate a dataset comprising more than 6000 apartments. A thorough experimentation with three different methods and two raw feature extraction procedures reveals the effectiveness of FArMARe in dealing with the problem at hand.
UniUD Submission to the EPIC-Kitchens-100 Multi-Instance Retrieval Challenge 2023
Jul 16, 2023
In this report, we present the technical details of our submission to the EPIC-Kitchens-100 Multi-Instance Retrieval Challenge 2023. To participate in the challenge, we ensembled two models trained with two different loss functions on 25% of the training data. Our submission, visible on the public leaderboard, obtains an average score of 56.81% nDCG and 42.63% mAP.
A Feature-space Multimodal Data Augmentation Technique for Text-video Retrieval
Aug 03, 2022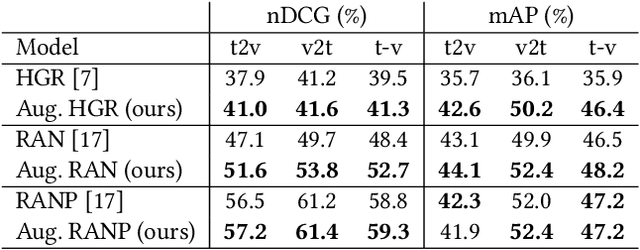

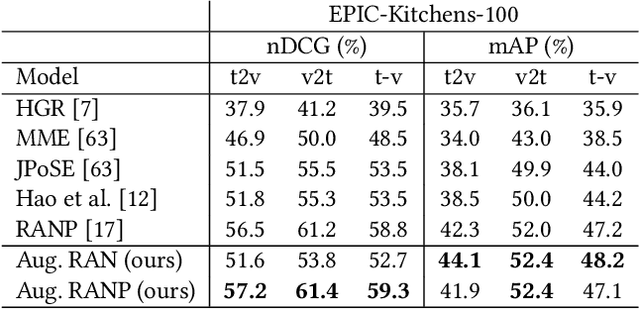
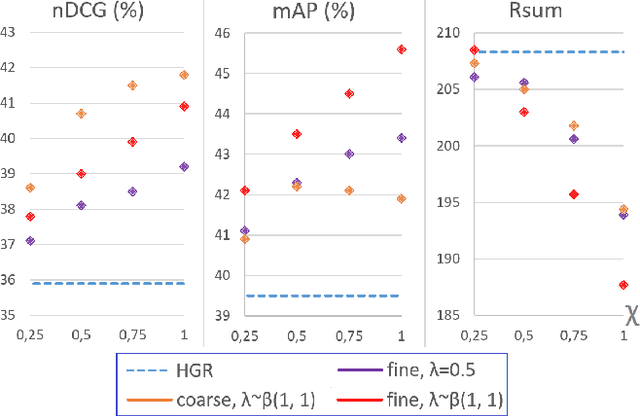
Every hour, huge amounts of visual contents are posted on social media and user-generated content platforms. To find relevant videos by means of a natural language query, text-video retrieval methods have received increased attention over the past few years. Data augmentation techniques were introduced to increase the performance on unseen test examples by creating new training samples with the application of semantics-preserving techniques, such as color space or geometric transformations on images. Yet, these techniques are usually applied on raw data, leading to more resource-demanding solutions and also requiring the shareability of the raw data, which may not always be true, e.g. copyright issues with clips from movies or TV series. To address this shortcoming, we propose a multimodal data augmentation technique which works in the feature space and creates new videos and captions by mixing semantically similar samples. We experiment our solution on a large scale public dataset, EPIC-Kitchens-100, and achieve considerable improvements over a baseline method, improved state-of-the-art performance, while at the same time performing multiple ablation studies. We release code and pretrained models on Github at https://github.com/aranciokov/FSMMDA_VideoRetrieval.
UniUD-FBK-UB-UniBZ Submission to the EPIC-Kitchens-100 Multi-Instance Retrieval Challenge 2022
Jun 22, 2022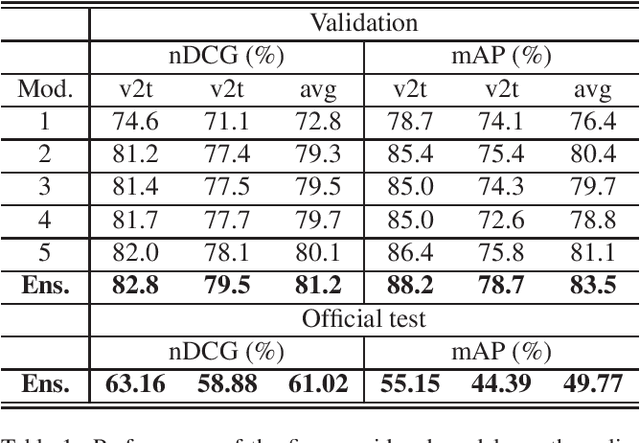
This report presents the technical details of our submission to the EPIC-Kitchens-100 Multi-Instance Retrieval Challenge 2022. To participate in the challenge, we designed an ensemble consisting of different models trained with two recently developed relevance-augmented versions of the widely used triplet loss. Our submission, visible on the public leaderboard, obtains an average score of 61.02% nDCG and 49.77% mAP.
Relevance-based Margin for Contrastively-trained Video Retrieval Models
Apr 27, 2022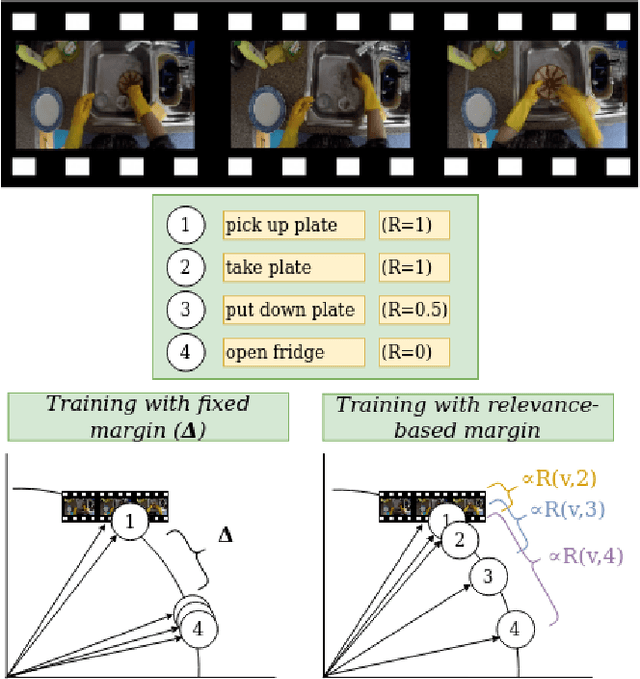
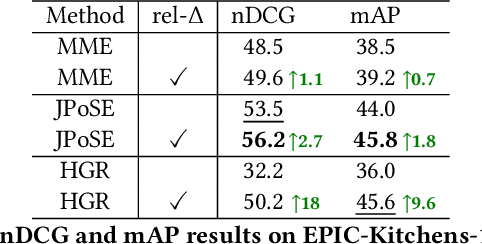
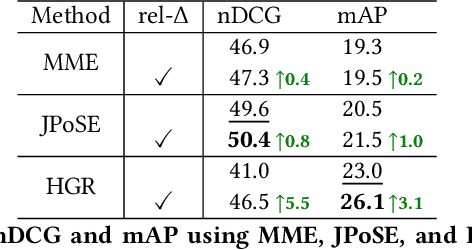
Video retrieval using natural language queries has attracted increasing interest due to its relevance in real-world applications, from intelligent access in private media galleries to web-scale video search. Learning the cross-similarity of video and text in a joint embedding space is the dominant approach. To do so, a contrastive loss is usually employed because it organizes the embedding space by putting similar items close and dissimilar items far. This framework leads to competitive recall rates, as they solely focus on the rank of the groundtruth items. Yet, assessing the quality of the ranking list is of utmost importance when considering intelligent retrieval systems, since multiple items may share similar semantics, hence a high relevance. Moreover, the aforementioned framework uses a fixed margin to separate similar and dissimilar items, treating all non-groundtruth items as equally irrelevant. In this paper we propose to use a variable margin: we argue that varying the margin used during training based on how much relevant an item is to a given query, i.e. a relevance-based margin, easily improves the quality of the ranking lists measured through nDCG and mAP. We demonstrate the advantages of our technique using different models on EPIC-Kitchens-100 and YouCook2. We show that even if we carefully tuned the fixed margin, our technique (which does not have the margin as a hyper-parameter) would still achieve better performance. Finally, extensive ablation studies and qualitative analysis support the robustness of our approach. Code will be released at \url{https://github.com/aranciokov/RelevanceMargin-ICMR22}.
Learning video retrieval models with relevance-aware online mining
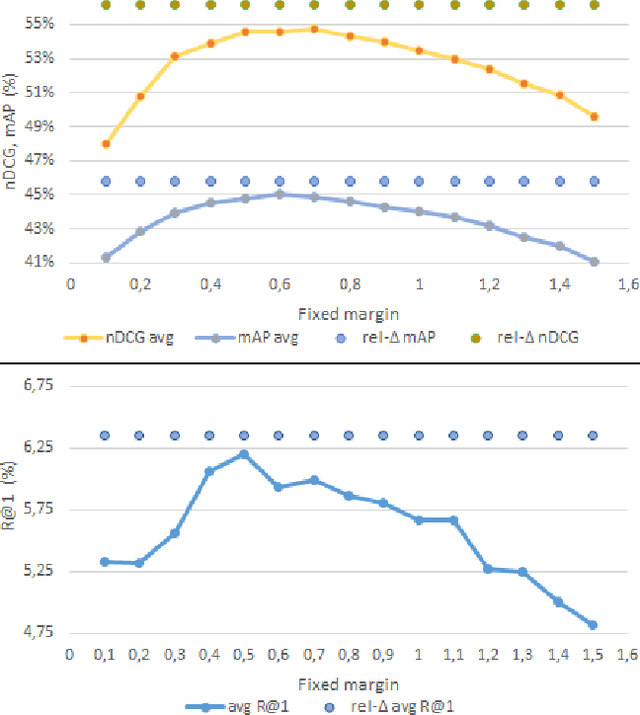
Mar 16, 2022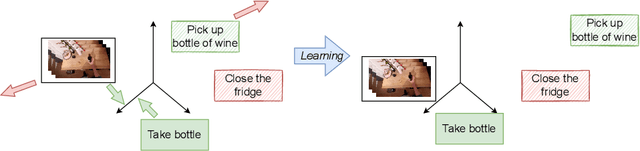
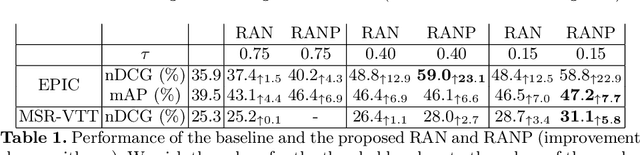
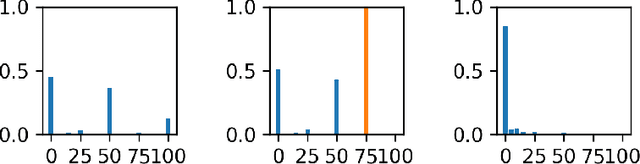
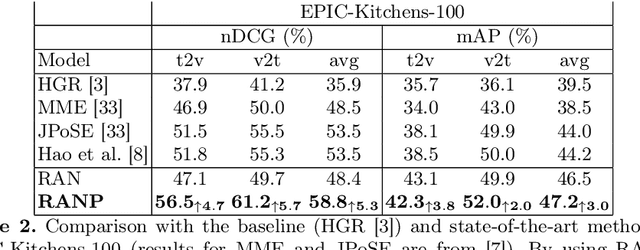
Due to the amount of videos and related captions uploaded every hour, deep learning-based solutions for cross-modal video retrieval are attracting more and more attention. A typical approach consists in learning a joint text-video embedding space, where the similarity of a video and its associated caption is maximized, whereas a lower similarity is enforced with all the other captions, called negatives. This approach assumes that only the video and caption pairs in the dataset are valid, but different captions - positives - may also describe its visual contents, hence some of them may be wrongly penalized. To address this shortcoming, we propose the Relevance-Aware Negatives and Positives mining (RANP) which, based on the semantics of the negatives, improves their selection while also increasing the similarity of other valid positives. We explore the influence of these techniques on two video-text datasets: EPIC-Kitchens-100 and MSR-VTT. By using the proposed techniques, we achieve considerable improvements in terms of nDCG and mAP, leading to state-of-the-art results, e.g. +5.3% nDCG and +3.0% mAP on EPIC-Kitchens-100. We share code and pretrained models at \url{https://github.com/aranciokov/ranp}.
SAIC_Cambridge-HuPBA-FBK Submission to the EPIC-Kitchens-100 Action Recognition Challenge 2021
Oct 06, 2021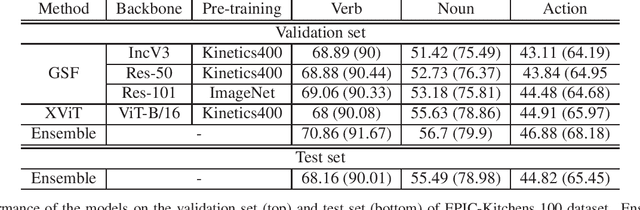
This report presents the technical details of our submission to the EPIC-Kitchens-100 Action Recognition Challenge 2021. To participate in the challenge we deployed spatio-temporal feature extraction and aggregation models we have developed recently: GSF and XViT. GSF is an efficient spatio-temporal feature extracting module that can be plugged into 2D CNNs for video action recognition. XViT is a convolution free video feature extractor based on transformer architecture. We design an ensemble of GSF and XViT model families with different backbones and pretraining to generate the prediction scores. Our submission, visible on the public leaderboard, achieved a top-1 action recognition accuracy of 44.82%, using only RGB.
Data augmentation techniques for the Video Question Answering task
Aug 22, 2020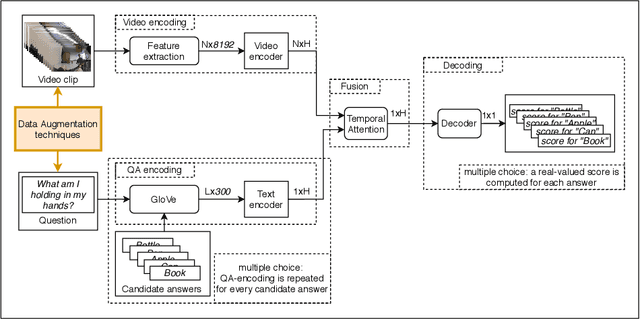

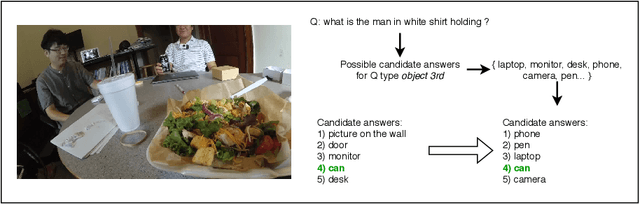
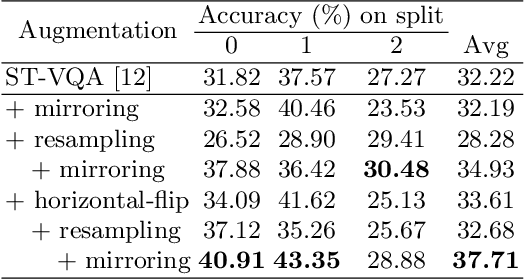
Video Question Answering (VideoQA) is a task that requires a model to analyze and understand both the visual content given by the input video and the textual part given by the question, and the interaction between them in order to produce a meaningful answer. In our work we focus on the Egocentric VideoQA task, which exploits first-person videos, because of the importance of such task which can have impact on many different fields, such as those pertaining the social assistance and the industrial training. Recently, an Egocentric VideoQA dataset, called EgoVQA, has been released. Given its small size, models tend to overfit quickly. To alleviate this problem, we propose several augmentation techniques which give us a +5.5% improvement on the final accuracy over the considered baseline.
Text-to-Image Synthesis Based on Machine Generated Captions
Oct 09, 2019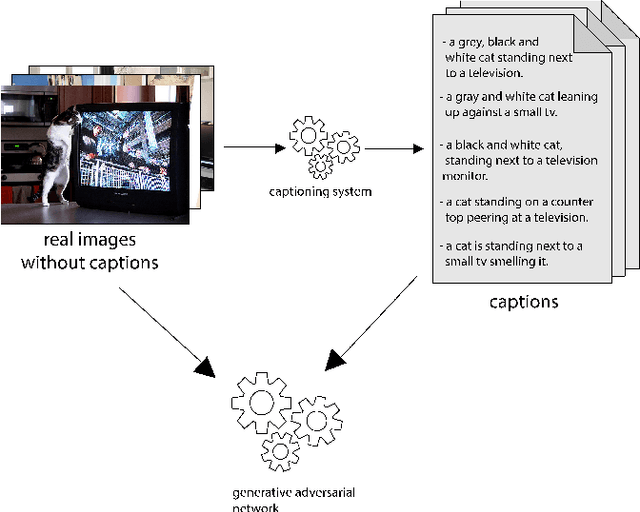
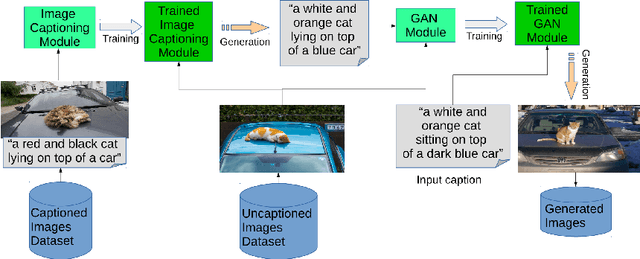


Text to Image Synthesis refers to the process of automatic generation of a photo-realistic image starting from a given text and is revolutionizing many real-world applications. In order to perform such process it is necessary to exploit datasets containing captioned images, meaning that each image is associated with one (or more) captions describing it. Despite the abundance of uncaptioned images datasets, the number of captioned datasets is limited. To address this issue, in this paper we propose an approach capable of generating images starting from a given text using conditional GANs trained on uncaptioned images dataset. In particular, uncaptioned images are fed to an Image Captioning Module to generate the descriptions. Then, the GAN Module is trained on both the input image and the machine-generated caption. To evaluate the results, the performance of our solution is compared with the results obtained by the unconditional GAN. For the experiments, we chose to use the uncaptioned dataset LSUN bedroom. The results obtained in our study are preliminary but still promising.