 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Image Tokenization for Multi-Scale Image Super Resolution
May 14, 2026We introduce a multi-scale Image Super Resolution (ISR) method building on recent advances in Visual Auto-Regressive (VAR) modeling. VAR models break image tokenization into additive, gradually increasing scales, using Residual Quantization (RQ), an approach that aligns perfectly with our target ISR task. Previous works taking advantage of this synergy suffer from two main shortcomings. First, due to the limitations in RQ, they only generate images at a predefined fixed scale, failing to map intermediate outputs to the corresponding image scales. They also rely on large backbones or a large corpus of annotated data to achieve better performance. To address both shortcomings, we introduce two novel components to the VAR training for ISR, aiming at increasing its flexibility and reducing its complexity. In particular, we introduce a) a \textbf{Hierarchical Image Tokenization (HIT)} approach that progressively represents images at different scales while enforcing token overlap across scales, and b) a \textbf{Direct Preference Optimization (DPO) regularization term} that, relying solely on the (LR,HR) pair, encourages the transformer to produce the latter over the former. Our proposed HIT acts as a strong inductive bias for the VAR training, resulting in a small model (300M params vs 1B params of VARSR), that achieves state-of-the-art results without external training data, and that delivers multi-scale outputs with a single forward pass.
Restore, Assess, Repeat: A Unified Framework for Iterative Image Restoration
Mar 27, 2026Image restoration aims to recover high quality images from inputs degraded by various factors, such as adverse weather, blur, or low light. While recent studies have shown remarkable progress across individual or unified restoration tasks, they still suffer from limited generalization and inefficiency when handling unknown or composite degradations. To address these limitations, we propose RAR, a Restore, Assess and Repeat process, that integrates Image Quality Assessment (IQA) and Image Restoration (IR) into a unified framework to iteratively and efficiently achieve high quality image restoration. Specifically, we introduce a restoration process that operates entirely in the latent domain to jointly perform degradation identification, image restoration, and quality verification. The resulting model is fully trainable end to end and allows for an all-in-one assess and restore approach that dynamically adapts the restoration process. Also, the tight integration of IQA and IR into a unified model minimizes the latency and information loss that typically arises from keeping the two modules disjoint, (e.g. during image and/or text decoding). Extensive experiments show that our approach consistent improvements under single, unknown and composite degradations, thereby establishing a new state-of-the-art.
No Hard Negatives Required: Concept Centric Learning Leads to Compositionality without Degrading Zero-shot Capabilities of Contrastive Models
Mar 26, 2026Contrastive vision-language (V&L) models remain a popular choice for various applications. However, several limitations have emerged, most notably the limited ability of V&L models to learn compositional representations. Prior methods often addressed this limitation by generating custom training data to obtain hard negative samples. Hard negatives have been shown to improve performance on compositionality tasks, but are often specific to a single benchmark, do not generalize, and can cause substantial degradation of basic V&L capabilities such as zero-shot or retrieval performance, rendering them impractical. In this work we follow a different approach. We identify two root causes that limit compositionality performance of V&Ls: 1) Long training captions do not require a compositional representation; and 2) The final global pooling in the text and image encoders lead to a complete loss of the necessary information to learn binding in the first place. As a remedy, we propose two simple solutions: 1) We obtain short concept centric caption parts using standard NLP software and align those with the image; and 2) We introduce a parameter-free cross-modal attention-pooling to obtain concept centric visual embeddings from the image encoder. With these two changes and simple auxiliary contrastive losses, we obtain SOTA performance on standard compositionality benchmarks, while maintaining or improving strong zero-shot and retrieval capabilities. This is achieved without increasing inference cost. We release the code for this work at https://github.com/SamsungLabs/concept_centric_clip.
More Images, More Problems? A Controlled Analysis of VLM Failure Modes
Jan 12, 2026Large Vision Language Models (LVLMs) have demonstrated remarkable capabilities, yet their proficiency in understanding and reasoning over multiple images remains largely unexplored. While existing benchmarks have initiated the evaluation of multi-image models, a comprehensive analysis of their core weaknesses and their causes is still lacking. In this work, we introduce MIMIC (Multi-Image Model Insights and Challenges), a new benchmark designed to rigorously evaluate the multi-image capabilities of LVLMs. Using MIMIC, we conduct a series of diagnostic experiments that reveal pervasive issues: LVLMs often fail to aggregate information across images and struggle to track or attend to multiple concepts simultaneously. To address these failures, we propose two novel complementary remedies. On the data side, we present a procedural data-generation strategy that composes single-image annotations into rich, targeted multi-image training examples. On the optimization side, we analyze layer-wise attention patterns and derive an attention-masking scheme tailored for multi-image inputs. Experiments substantially improved cross-image aggregation, while also enhancing performance on existing multi-image benchmarks, outperforming prior state of the art across tasks. Data and code will be made available at https://github.com/anurag-198/MIMIC.
Multi-scale Image Super Resolution with a Single Auto-Regressive Model
Jun 05, 2025In this paper we tackle Image Super Resolution (ISR), using recent advances in Visual Auto-Regressive (VAR) modeling. VAR iteratively estimates the residual in latent space between gradually increasing image scales, a process referred to as next-scale prediction. Thus, the strong priors learned during pre-training align well with the downstream task (ISR). To our knowledge, only VARSR has exploited this synergy so far, showing promising results. However, due to the limitations of existing residual quantizers, VARSR works only at a fixed resolution, i.e. it fails to map intermediate outputs to the corresponding image scales. Additionally, it relies on a 1B transformer architecture (VAR-d24), and leverages a large-scale private dataset to achieve state-of-the-art results. We address these limitations through two novel components: a) a Hierarchical Image Tokenization approach with a multi-scale image tokenizer that progressively represents images at different scales while simultaneously enforcing token overlap across scales, and b) a Direct Preference Optimization (DPO) regularization term that, relying solely on the LR and HR tokenizations, encourages the transformer to produce the latter over the former. To the best of our knowledge, this is the first time a quantizer is trained to force semantically consistent residuals at different scales, and the first time that preference-based optimization is used to train a VAR. Using these two components, our model can denoise the LR image and super-resolve at half and full target upscale factors in a single forward pass. Additionally, we achieve \textit{state-of-the-art results on ISR}, while using a small model (300M params vs ~1B params of VARSR), and without using external training data.
Edge-SD-SR: Low Latency and Parameter Efficient On-device Super-Resolution with Stable Diffusion via Bidirectional Conditioning
Dec 09, 2024



There has been immense progress recently in the visual quality of Stable Diffusion-based Super Resolution (SD-SR). However, deploying large diffusion models on computationally restricted devices such as mobile phones remains impractical due to the large model size and high latency. This is compounded for SR as it often operates at high res (e.g. 4Kx3K). In this work, we introduce Edge-SD-SR, the first parameter efficient and low latency diffusion model for image super-resolution. Edge-SD-SR consists of ~169M parameters, including UNet, encoder and decoder, and has a complexity of only ~142 GFLOPs. To maintain a high visual quality on such low compute budget, we introduce a number of training strategies: (i) A novel conditioning mechanism on the low resolution input, coined bidirectional conditioning, which tailors the SD model for the SR task. (ii) Joint training of the UNet and encoder, while decoupling the encodings of the HR and LR images and using a dedicated schedule. (iii) Finetuning the decoder using the UNet's output to directly tailor the decoder to the latents obtained at inference time. Edge-SD-SR runs efficiently on device, e.g. it can upscale a 128x128 patch to 512x512 in 38 msec while running on a Samsung S24 DSP, and of a 512x512 to 2048x2048 (requiring 25 model evaluations) in just ~1.1 sec. Furthermore, we show that Edge-SD-SR matches or even outperforms state-of-the-art SR approaches on the most established SR benchmarks.
Discriminative Fine-tuning of LVLMs
Dec 05, 2024



Contrastively-trained Vision-Language Models (VLMs) like CLIP have become the de facto approach for discriminative vision-language representation learning. However, these models have limited language understanding, often exhibiting a "bag of words" behavior. At the same time, Large Vision-Language Models (LVLMs), which combine vision encoders with LLMs, have been shown capable of detailed vision-language reasoning, yet their autoregressive nature renders them less suitable for discriminative tasks. In this work, we propose to combine "the best of both worlds": a new training approach for discriminative fine-tuning of LVLMs that results in strong discriminative and compositional capabilities. Essentially, our approach converts a generative LVLM into a discriminative one, unlocking its capability for powerful image-text discrimination combined with enhanced language understanding. Our contributions include: (1) A carefully designed training/optimization framework that utilizes image-text pairs of variable length and granularity for training the model with both contrastive and next-token prediction losses. This is accompanied by ablation studies that justify the necessity of our framework's components. (2) A parameter-efficient adaptation method using a combination of soft prompting and LoRA adapters. (3) Significant improvements over state-of-the-art CLIP-like models of similar size, including standard image-text retrieval benchmarks and notable gains in compositionality.
FAM Diffusion: Frequency and Attention Modulation for High-Resolution Image Generation with Stable Diffusion
Nov 27, 2024



Diffusion models are proficient at generating high-quality images. They are however effective only when operating at the resolution used during training. Inference at a scaled resolution leads to repetitive patterns and structural distortions. Retraining at higher resolutions quickly becomes prohibitive. Thus, methods enabling pre-existing diffusion models to operate at flexible test-time resolutions are highly desirable. Previous works suffer from frequent artifacts and often introduce large latency overheads. We propose two simple modules that combine to solve these issues. We introduce a Frequency Modulation (FM) module that leverages the Fourier domain to improve the global structure consistency, and an Attention Modulation (AM) module which improves the consistency of local texture patterns, a problem largely ignored in prior works. Our method, coined Fam diffusion, can seamlessly integrate into any latent diffusion model and requires no additional training. Extensive qualitative results highlight the effectiveness of our method in addressing structural and local artifacts, while quantitative results show state-of-the-art performance. Also, our method avoids redundant inference tricks for improved consistency such as patch-based or progressive generation, leading to negligible latency overheads.
A Bayesian Approach to Data Point Selection
Nov 06, 2024Data point selection (DPS) is becoming a critical topic in deep learning due to the ease of acquiring uncurated training data compared to the difficulty of obtaining curated or processed data. Existing approaches to DPS are predominantly based on a bi-level optimisation (BLO) formulation, which is demanding in terms of memory and computation, and exhibits some theoretical defects regarding minibatches. Thus, we propose a novel Bayesian approach to DPS. We view the DPS problem as posterior inference in a novel Bayesian model where the posterior distributions of the instance-wise weights and the main neural network parameters are inferred under a reasonable prior and likelihood model. We employ stochastic gradient Langevin MCMC sampling to learn the main network and instance-wise weights jointly, ensuring convergence even with minibatches. Our update equation is comparable to the widely used SGD and much more efficient than existing BLO-based methods. Through controlled experiments in both the vision and language domains, we present the proof-of-concept. Additionally, we demonstrate that our method scales effectively to large language models and facilitates automated per-task optimization for instruction fine-tuning datasets.
MobileQuant: Mobile-friendly Quantization for On-device Language Models
Aug 25, 2024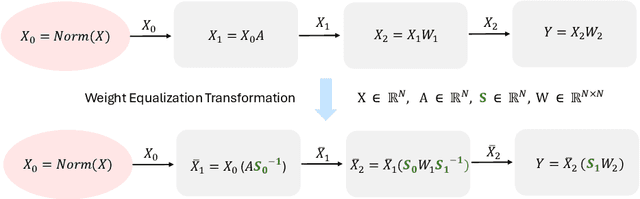
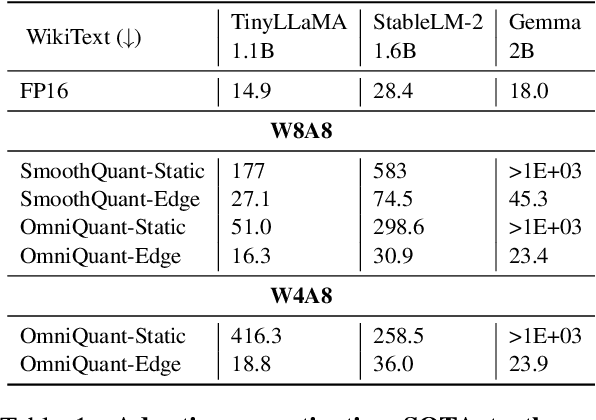

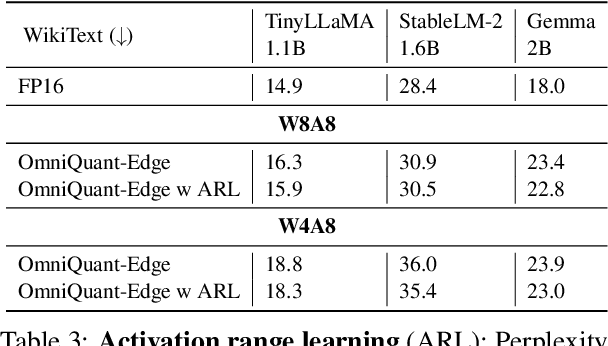
Large language models (LLMs) have revolutionized language processing, delivering outstanding results across multiple applications. However, deploying LLMs on edge devices poses several challenges with respect to memory, energy, and compute costs, limiting their widespread use in devices such as mobile phones. A promising solution is to reduce the number of bits used to represent weights and activations. While existing works have found partial success at quantizing LLMs to lower bitwidths, e.g. 4-bit weights, quantizing activations beyond 16 bits often leads to large computational overheads due to poor on-device quantization support, or a considerable accuracy drop. Yet, 8-bit activations are very attractive for on-device deployment as they would enable LLMs to fully exploit mobile-friendly hardware, e.g. Neural Processing Units (NPUs). In this work, we make a first attempt to facilitate the on-device deployment of LLMs using integer-only quantization. We first investigate the limitations of existing quantization methods for on-device deployment, with a special focus on activation quantization. We then address these limitations by introducing a simple post-training quantization method, named MobileQuant, that extends previous weight equivalent transformation works by jointly optimizing the weight transformation and activation range parameters in an end-to-end manner. MobileQuant demonstrates superior capabilities over existing methods by 1) achieving near-lossless quantization on a wide range of LLM benchmarks, 2) reducing latency and energy consumption by 20\%-50\% compared to current on-device quantization strategies, 3) requiring limited compute budget, 4) being compatible with mobile-friendly compute units, e.g. NPU.