 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAugmenting Perceptual Super-Resolution via Image Quality Predictors
Apr 25, 2025



Super-resolution (SR), a classical inverse problem in computer vision, is inherently ill-posed, inducing a distribution of plausible solutions for every input. However, the desired result is not simply the expectation of this distribution, which is the blurry image obtained by minimizing pixelwise error, but rather the sample with the highest image quality. A variety of techniques, from perceptual metrics to adversarial losses, are employed to this end. In this work, we explore an alternative: utilizing powerful non-reference image quality assessment (NR-IQA) models in the SR context. We begin with a comprehensive analysis of NR-IQA metrics on human-derived SR data, identifying both the accuracy (human alignment) and complementarity of different metrics. Then, we explore two methods of applying NR-IQA models to SR learning: (i) altering data sampling, by building on an existing multi-ground-truth SR framework, and (ii) directly optimizing a differentiable quality score. Our results demonstrate a more human-centric perception-distortion tradeoff, focusing less on non-perceptual pixel-wise distortion, instead improving the balance between perceptual fidelity and human-tuned NR-IQA measures.
CIC-BART-SSA: Controllable Image Captioning with Structured Semantic Augmentation
Jul 16, 2024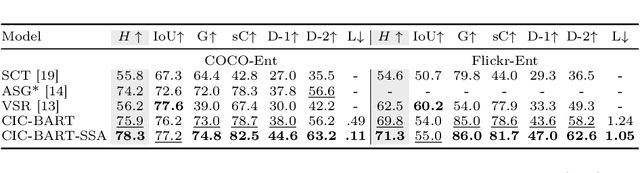
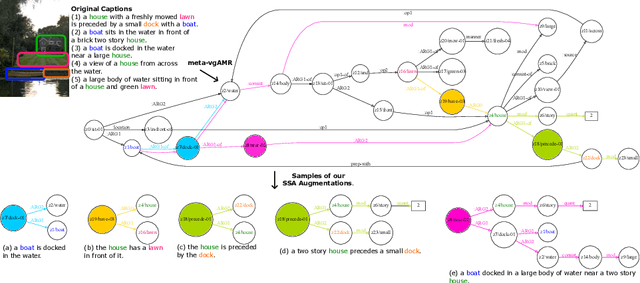


Controllable Image Captioning (CIC) aims at generating natural language descriptions for an image, conditioned on information provided by end users, e.g., regions, entities or events of interest. However, available image--language datasets mainly contain captions that describe the entirety of an image, making them ineffective for training CIC models that can potentially attend to any subset of regions or relationships. To tackle this challenge, we propose a novel, fully automatic method to sample additional focused and visually grounded captions using a unified structured semantic representation built on top of the existing set of captions associated with an image. We leverage Abstract Meaning Representation (AMR), a cross-lingual graph-based semantic formalism, to encode all possible spatio-semantic relations between entities, beyond the typical spatial-relations-only focus of current methods. We use this Structured Semantic Augmentation (SSA) framework to augment existing image--caption datasets with the grounded controlled captions, increasing their spatial and semantic diversity and focal coverage. We then develop a new model, CIC-BART-SSA, specifically tailored for the CIC task, that sources its control signals from SSA-diversified datasets. We empirically show that, compared to SOTA CIC models, CIC-BART-SSA generates captions that are superior in diversity and text quality, are competitive in controllability, and, importantly, minimize the gap between broad and highly focused controlled captioning performance by efficiently generalizing to the challenging highly focused scenarios. Code is available at https://github.com/SamsungLabs/CIC-BART-SSA.
Graph Guided Question Answer Generation for Procedural Question-Answering
Jan 24, 2024
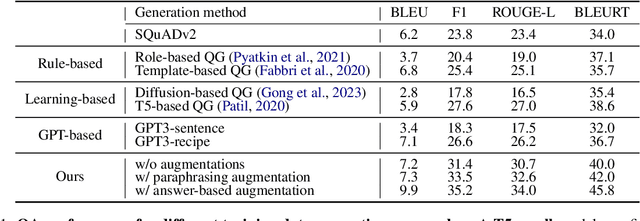
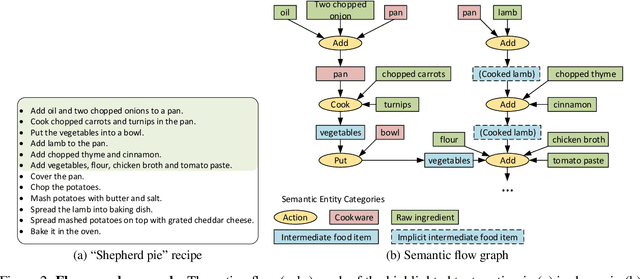
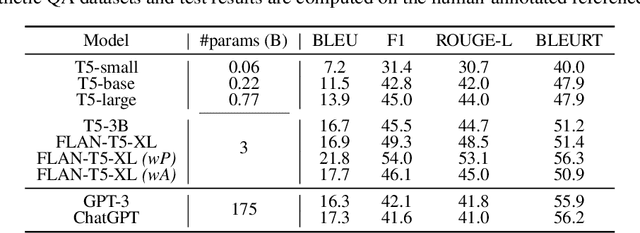
In this paper, we focus on task-specific question answering (QA). To this end, we introduce a method for generating exhaustive and high-quality training data, which allows us to train compact (e.g., run on a mobile device), task-specific QA models that are competitive against GPT variants. The key technological enabler is a novel mechanism for automatic question-answer generation from procedural text which can ingest large amounts of textual instructions and produce exhaustive in-domain QA training data. While current QA data generation methods can produce well-formed and varied data, their non-exhaustive nature is sub-optimal for training a QA model. In contrast, we leverage the highly structured aspect of procedural text and represent each step and the overall flow of the procedure as graphs. We then condition on graph nodes to automatically generate QA pairs in an exhaustive and controllable manner. Comprehensive evaluations of our method show that: 1) small models trained with our data achieve excellent performance on the target QA task, even exceeding that of GPT3 and ChatGPT despite being several orders of magnitude smaller. 2) semantic coverage is the key indicator for downstream QA performance. Crucially, while large language models excel at syntactic diversity, this does not necessarily result in improvements on the end QA model. In contrast, the higher semantic coverage provided by our method is critical for QA performance.
GePSAn: Generative Procedure Step Anticipation in Cooking Videos
Oct 12, 2023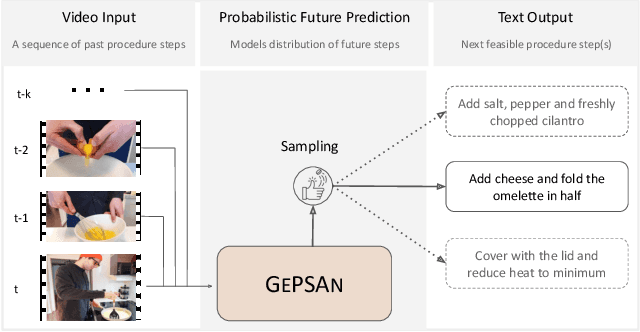
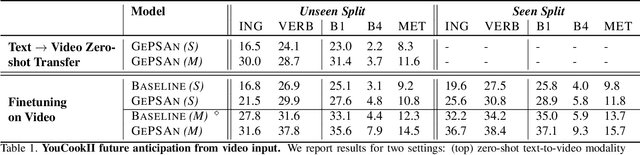
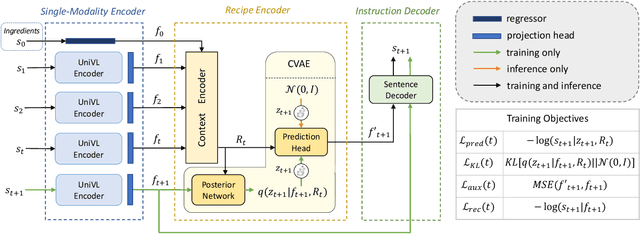
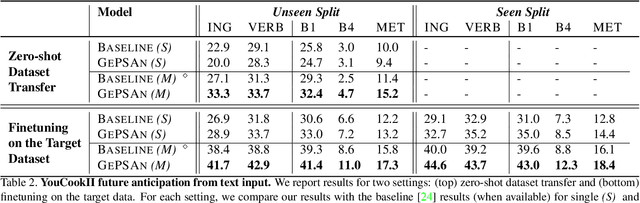
We study the problem of future step anticipation in procedural videos. Given a video of an ongoing procedural activity, we predict a plausible next procedure step described in rich natural language. While most previous work focus on the problem of data scarcity in procedural video datasets, another core challenge of future anticipation is how to account for multiple plausible future realizations in natural settings. This problem has been largely overlooked in previous work. To address this challenge, we frame future step prediction as modelling the distribution of all possible candidates for the next step. Specifically, we design a generative model that takes a series of video clips as input, and generates multiple plausible and diverse candidates (in natural language) for the next step. Following previous work, we side-step the video annotation scarcity by pretraining our model on a large text-based corpus of procedural activities, and then transfer the model to the video domain. Our experiments, both in textual and video domains, show that our model captures diversity in the next step prediction and generates multiple plausible future predictions. Moreover, our model establishes new state-of-the-art results on YouCookII, where it outperforms existing baselines on the next step anticipation. Finally, we also show that our model can successfully transfer from text to the video domain zero-shot, ie, without fine-tuning or adaptation, and produces good-quality future step predictions from video.
SAGE: Saliency-Guided Mixup with Optimal Rearrangements
Oct 31, 2022



Data augmentation is a key element for training accurate models by reducing overfitting and improving generalization. For image classification, the most popular data augmentation techniques range from simple photometric and geometrical transformations, to more complex methods that use visual saliency to craft new training examples. As augmentation methods get more complex, their ability to increase the test accuracy improves, yet, such methods become cumbersome, inefficient and lead to poor out-of-domain generalization, as we show in this paper. This motivates a new augmentation technique that allows for high accuracy gains while being simple, efficient (i.e., minimal computation overhead) and generalizable. To this end, we introduce Saliency-Guided Mixup with Optimal Rearrangements (SAGE), which creates new training examples by rearranging and mixing image pairs using visual saliency as guidance. By explicitly leveraging saliency, SAGE promotes discriminative foreground objects and produces informative new images useful for training. We demonstrate on CIFAR-10 and CIFAR-100 that SAGE achieves better or comparable performance to the state of the art while being more efficient. Additionally, evaluations in the out-of-distribution setting, and few-shot learning on mini-ImageNet, show that SAGE achieves improved generalization performance without trading off robustness.
Visual Semantic Parsing: From Images to Abstract Meaning Representation
Oct 27, 2022The success of scene graphs for visual scene understanding has brought attention to the benefits of abstracting a visual input (e.g., image) into a structured representation, where entities (people and objects) are nodes connected by edges specifying their relations. Building these representations, however, requires expensive manual annotation in the form of images paired with their scene graphs or frames. These formalisms remain limited in the nature of entities and relations they can capture. In this paper, we propose to leverage a widely-used meaning representation in the field of natural language processing, the Abstract Meaning Representation (AMR), to address these shortcomings. Compared to scene graphs, which largely emphasize spatial relationships, our visual AMR graphs are more linguistically informed, with a focus on higher-level semantic concepts extrapolated from visual input. Moreover, they allow us to generate meta-AMR graphs to unify information contained in multiple image descriptions under one representation. Through extensive experimentation and analysis, we demonstrate that we can re-purpose an existing text-to-AMR parser to parse images into AMRs. Our findings point to important future research directions for improved scene understanding.
Graph2Vid: Flow graph to Video Grounding forWeakly-supervised Multi-Step Localization
Oct 10, 2022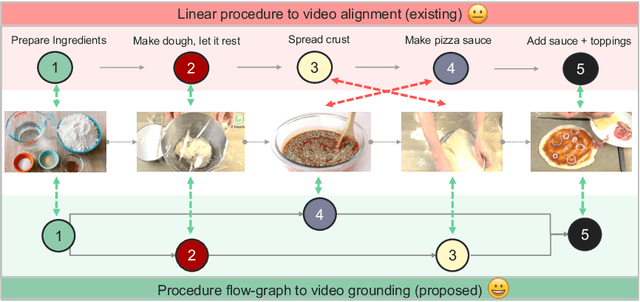
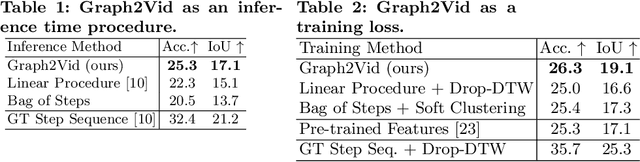

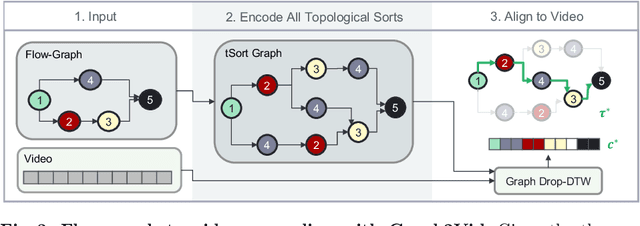
In this work, we consider the problem of weakly-supervised multi-step localization in instructional videos. An established approach to this problem is to rely on a given list of steps. However, in reality, there is often more than one way to execute a procedure successfully, by following the set of steps in slightly varying orders. Thus, for successful localization in a given video, recent works require the actual order of procedure steps in the video, to be provided by human annotators at both training and test times. Instead, here, we only rely on generic procedural text that is not tied to a specific video. We represent the various ways to complete the procedure by transforming the list of instructions into a procedure flow graph which captures the partial order of steps. Using the flow graphs reduces both training and test time annotation requirements. To this end, we introduce the new problem of flow graph to video grounding. In this setup, we seek the optimal step ordering consistent with the procedure flow graph and a given video. To solve this problem, we propose a new algorithm - Graph2Vid - that infers the actual ordering of steps in the video and simultaneously localizes them. To show the advantage of our proposed formulation, we extend the CrossTask dataset with procedure flow graph information. Our experiments show that Graph2Vid is both more efficient than the baselines and yields strong step localization results, without the need for step order annotation.
* ECCV'22, oral
Uncertainty-based Cross-Modal Retrieval with Probabilistic Representations
Apr 20, 2022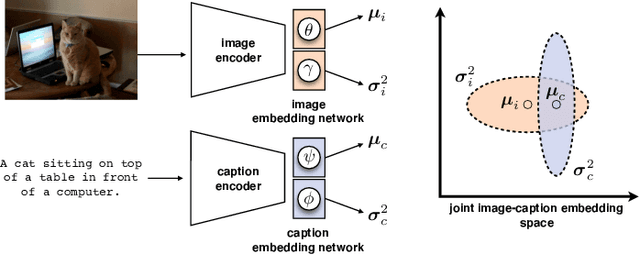
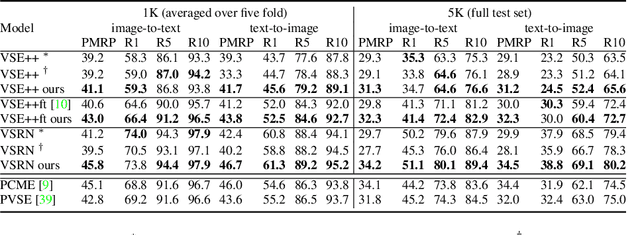
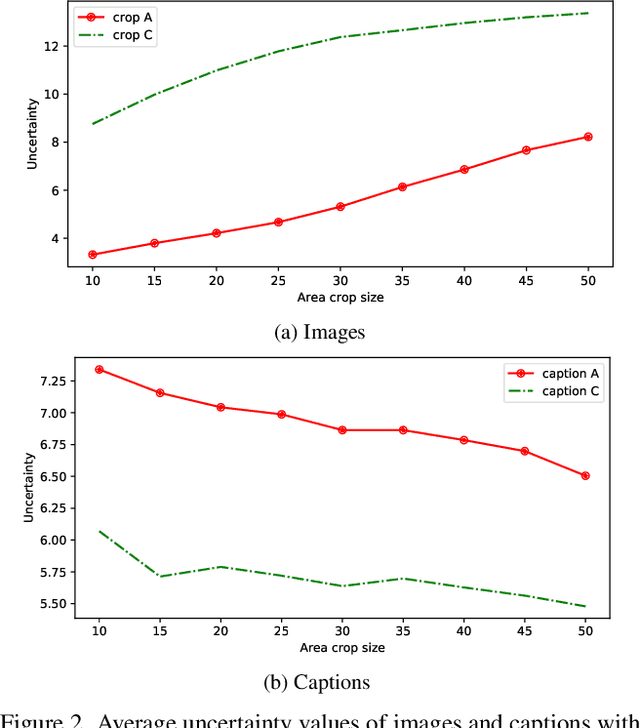
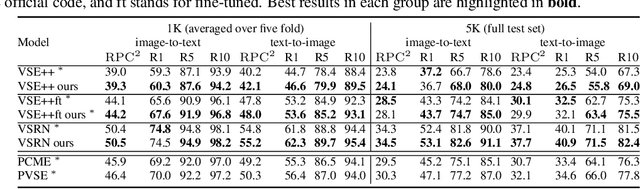
Probabilistic embeddings have proven useful for capturing polysemous word meanings, as well as ambiguity in image matching. In this paper, we study the advantages of probabilistic embeddings in a cross-modal setting (i.e., text and images), and propose a simple approach that replaces the standard vector point embeddings in extant image-text matching models with probabilistic distributions that are parametrically learned. Our guiding hypothesis is that the uncertainty encoded in the probabilistic embeddings captures the cross-modal ambiguity in the input instances, and that it is through capturing this uncertainty that the probabilistic models can perform better at downstream tasks, such as image-to-text or text-to-image retrieval. Through extensive experiments on standard and new benchmarks, we show a consistent advantage for probabilistic representations in cross-modal retrieval, and validate the ability of our embeddings to capture uncertainty.
VASTA: A Vision and Language-assisted Smartphone Task Automation System
Nov 04, 2019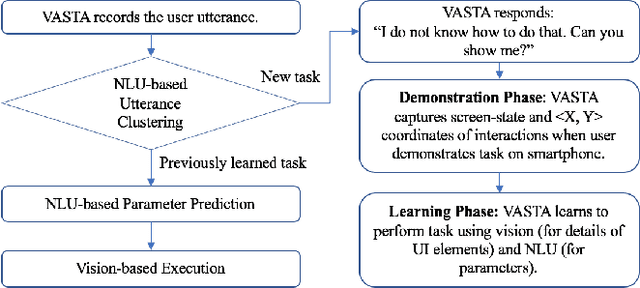

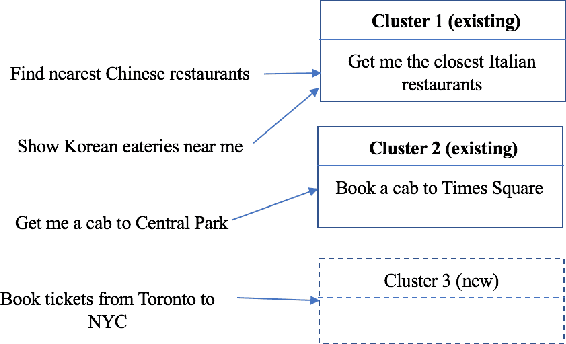
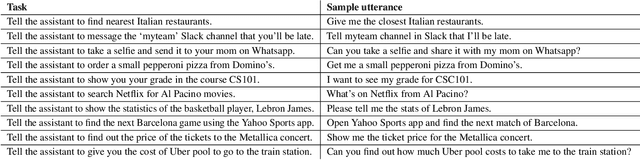
We present VASTA, a novel vision and language-assisted Programming By Demonstration (PBD) system for smartphone task automation. Development of a robust PBD automation system requires overcoming three key challenges: first, how to make a particular demonstration robust to positional and visual changes in the user interface (UI) elements; secondly, how to recognize changes in the automation parameters to make the demonstration as generalizable as possible; and thirdly, how to recognize from the user utterance what automation the user wishes to carry out. To address the first challenge, VASTA leverages state-of-the-art computer vision techniques, including object detection and optical character recognition, to accurately label interactions demonstrated by a user, without relying on the underlying UI structures. To address the second and third challenges, VASTA takes advantage of advanced natural language understanding algorithms for analyzing the user utterance to trigger the VASTA automation scripts, and to determine the automation parameters for generalization. We run an initial user study that demonstrates the effectiveness of VASTA at clustering user utterances, understanding changes in the automation parameters, detecting desired UI elements, and, most importantly, automating various tasks. A demo video of the system is available here: http://y2u.be/kr2xE-FixjI