 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQonvolution: Towards Learning High-Frequency Signals with Queried Convolution
Dec 15, 2025Accurately learning high-frequency signals is a challenge in computer vision and graphics, as neural networks often struggle with these signals due to spectral bias or optimization difficulties. While current techniques like Fourier encodings have made great strides in improving performance, there remains scope for improvement when presented with high-frequency information. This paper introduces Queried-Convolutions (Qonvolutions), a simple yet powerful modification using the neighborhood properties of convolution. Qonvolution convolves a low-frequency signal with queries (such as coordinates) to enhance the learning of intricate high-frequency signals. We empirically demonstrate that Qonvolutions enhance performance across a variety of high-frequency learning tasks crucial to both the computer vision and graphics communities, including 1D regression, 2D super-resolution, 2D image regression, and novel view synthesis (NVS). In particular, by combining Gaussian splatting with Qonvolutions for NVS, we showcase state-of-the-art performance on real-world complex scenes, even outperforming powerful radiance field models on image quality.
Augmenting Perceptual Super-Resolution via Image Quality Predictors
Apr 25, 2025Super-resolution (SR), a classical inverse problem in computer vision, is inherently ill-posed, inducing a distribution of plausible solutions for every input. However, the desired result is not simply the expectation of this distribution, which is the blurry image obtained by minimizing pixelwise error, but rather the sample with the highest image quality. A variety of techniques, from perceptual metrics to adversarial losses, are employed to this end. In this work, we explore an alternative: utilizing powerful non-reference image quality assessment (NR-IQA) models in the SR context. We begin with a comprehensive analysis of NR-IQA metrics on human-derived SR data, identifying both the accuracy (human alignment) and complementarity of different metrics. Then, we explore two methods of applying NR-IQA models to SR learning: (i) altering data sampling, by building on an existing multi-ground-truth SR framework, and (ii) directly optimizing a differentiable quality score. Our results demonstrate a more human-centric perception-distortion tradeoff, focusing less on non-perceptual pixel-wise distortion, instead improving the balance between perceptual fidelity and human-tuned NR-IQA measures.
Towards Unsupervised Blind Face Restoration using Diffusion Prior
Oct 06, 2024Blind face restoration methods have shown remarkable performance, particularly when trained on large-scale synthetic datasets with supervised learning. These datasets are often generated by simulating low-quality face images with a handcrafted image degradation pipeline. The models trained on such synthetic degradations, however, cannot deal with inputs of unseen degradations. In this paper, we address this issue by using only a set of input images, with unknown degradations and without ground truth targets, to fine-tune a restoration model that learns to map them to clean and contextually consistent outputs. We utilize a pre-trained diffusion model as a generative prior through which we generate high quality images from the natural image distribution while maintaining the input image content through consistency constraints. These generated images are then used as pseudo targets to fine-tune a pre-trained restoration model. Unlike many recent approaches that employ diffusion models at test time, we only do so during training and thus maintain an efficient inference-time performance. Extensive experiments show that the proposed approach can consistently improve the perceptual quality of pre-trained blind face restoration models while maintaining great consistency with the input contents. Our best model also achieves the state-of-the-art results on both synthetic and real-world datasets.
Reconstructive Latent-Space Neural Radiance Fields for Efficient 3D Scene Representations
Oct 27, 2023



Neural Radiance Fields (NeRFs) have proven to be powerful 3D representations, capable of high quality novel view synthesis of complex scenes. While NeRFs have been applied to graphics, vision, and robotics, problems with slow rendering speed and characteristic visual artifacts prevent adoption in many use cases. In this work, we investigate combining an autoencoder (AE) with a NeRF, in which latent features (instead of colours) are rendered and then convolutionally decoded. The resulting latent-space NeRF can produce novel views with higher quality than standard colour-space NeRFs, as the AE can correct certain visual artifacts, while rendering over three times faster. Our work is orthogonal to other techniques for improving NeRF efficiency. Further, we can control the tradeoff between efficiency and image quality by shrinking the AE architecture, achieving over 13 times faster rendering with only a small drop in performance. We hope that our approach can form the basis of an efficient, yet high-fidelity, 3D scene representation for downstream tasks, especially when retaining differentiability is useful, as in many robotics scenarios requiring continual learning.
Dual-Camera Joint Deblurring-Denoising
Sep 16, 2023Recent image enhancement methods have shown the advantages of using a pair of long and short-exposure images for low-light photography. These image modalities offer complementary strengths and weaknesses. The former yields an image that is clean but blurry due to camera or object motion, whereas the latter is sharp but noisy due to low photon count. Motivated by the fact that modern smartphones come equipped with multiple rear-facing camera sensors, we propose a novel dual-camera method for obtaining a high-quality image. Our method uses a synchronized burst of short exposure images captured by one camera and a long exposure image simultaneously captured by another. Having a synchronized short exposure burst alongside the long exposure image enables us to (i) obtain better denoising by using a burst instead of a single image, (ii) recover motion from the burst and use it for motion-aware deblurring of the long exposure image, and (iii) fuse the two results to further enhance quality. Our method is able to achieve state-of-the-art results on synthetic dual-camera images from the GoPro dataset with five times fewer training parameters compared to the next best method. We also show that our method qualitatively outperforms competing approaches on real synchronized dual-camera captures.
Watch Your Steps: Local Image and Scene Editing by Text Instructions
Aug 17, 2023Denoising diffusion models have enabled high-quality image generation and editing. We present a method to localize the desired edit region implicit in a text instruction. We leverage InstructPix2Pix (IP2P) and identify the discrepancy between IP2P predictions with and without the instruction. This discrepancy is referred to as the relevance map. The relevance map conveys the importance of changing each pixel to achieve the edits, and is used to to guide the modifications. This guidance ensures that the irrelevant pixels remain unchanged. Relevance maps are further used to enhance the quality of text-guided editing of 3D scenes in the form of neural radiance fields. A field is trained on relevance maps of training views, denoted as the relevance field, defining the 3D region within which modifications should be made. We perform iterative updates on the training views guided by rendered relevance maps from the relevance field. Our method achieves state-of-the-art performance on both image and NeRF editing tasks. Project page: https://ashmrz.github.io/WatchYourSteps/
Reference-guided Controllable Inpainting of Neural Radiance Fields
Apr 20, 2023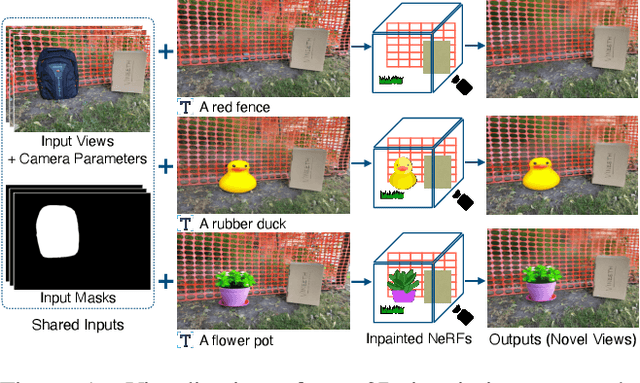
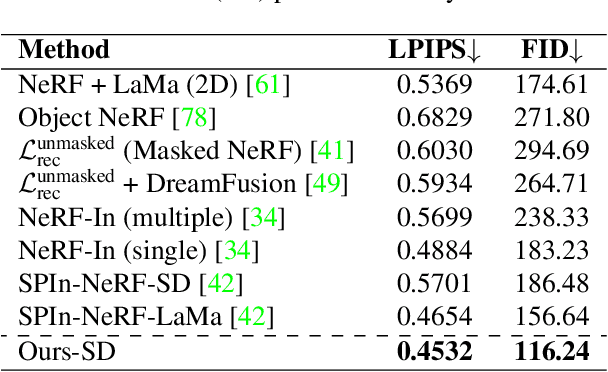

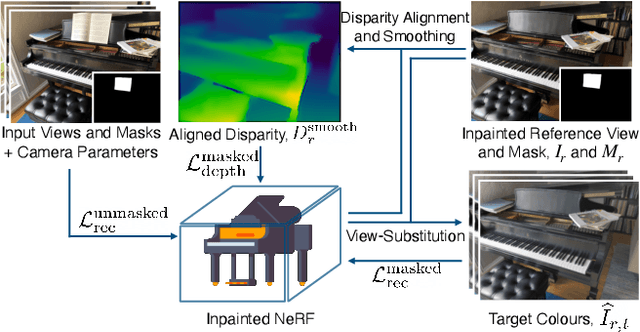
The popularity of Neural Radiance Fields (NeRFs) for view synthesis has led to a desire for NeRF editing tools. Here, we focus on inpainting regions in a view-consistent and controllable manner. In addition to the typical NeRF inputs and masks delineating the unwanted region in each view, we require only a single inpainted view of the scene, i.e., a reference view. We use monocular depth estimators to back-project the inpainted view to the correct 3D positions. Then, via a novel rendering technique, a bilateral solver can construct view-dependent effects in non-reference views, making the inpainted region appear consistent from any view. For non-reference disoccluded regions, which cannot be supervised by the single reference view, we devise a method based on image inpainters to guide both the geometry and appearance. Our approach shows superior performance to NeRF inpainting baselines, with the additional advantage that a user can control the generated scene via a single inpainted image. Project page: https://ashmrz.github.io/reference-guided-3d
Efficient Flow-Guided Multi-frame De-fencing
Jan 25, 2023
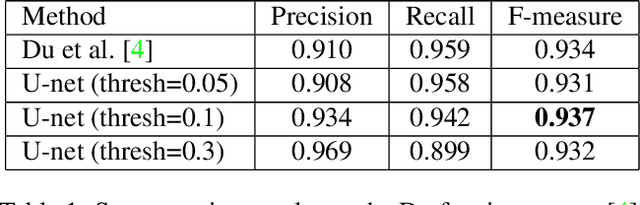


Taking photographs ''in-the-wild'' is often hindered by fence obstructions that stand between the camera user and the scene of interest, and which are hard or impossible to avoid. De-fencing is the algorithmic process of automatically removing such obstructions from images, revealing the invisible parts of the scene. While this problem can be formulated as a combination of fence segmentation and image inpainting, this often leads to implausible hallucinations of the occluded regions. Existing multi-frame approaches rely on propagating information to a selected keyframe from its temporal neighbors, but they are often inefficient and struggle with alignment of severely obstructed images. In this work we draw inspiration from the video completion literature and develop a simplified framework for multi-frame de-fencing that computes high quality flow maps directly from obstructed frames and uses them to accurately align frames. Our primary focus is efficiency and practicality in a real-world setting: the input to our algorithm is a short image burst (5 frames) - a data modality commonly available in modern smartphones - and the output is a single reconstructed keyframe, with the fence removed. Our approach leverages simple yet effective CNN modules, trained on carefully generated synthetic data, and outperforms more complicated alternatives real bursts, both quantitatively and qualitatively, while running real-time.
* 16 pages, 12 figures. Published at the Winter Conference on Application of Computer Vision (WACV) 2023
SPIn-NeRF: Multiview Segmentation and Perceptual Inpainting with Neural Radiance Fields
Nov 22, 2022Neural Radiance Fields (NeRFs) have emerged as a popular approach for novel view synthesis. While NeRFs are quickly being adapted for a wider set of applications, intuitively editing NeRF scenes is still an open challenge. One important editing task is the removal of unwanted objects from a 3D scene, such that the replaced region is visually plausible and consistent with its context. We refer to this task as 3D inpainting. In 3D, solutions must be both consistent across multiple views and geometrically valid. In this paper, we propose a novel 3D inpainting method that addresses these challenges. Given a small set of posed images and sparse annotations in a single input image, our framework first rapidly obtains a 3D segmentation mask for a target object. Using the mask, a perceptual optimizationbased approach is then introduced that leverages learned 2D image inpainters, distilling their information into 3D space, while ensuring view consistency. We also address the lack of a diverse benchmark for evaluating 3D scene inpainting methods by introducing a dataset comprised of challenging real-world scenes. In particular, our dataset contains views of the same scene with and without a target object, enabling more principled benchmarking of the 3D inpainting task. We first demonstrate the superiority of our approach on multiview segmentation, comparing to NeRFbased methods and 2D segmentation approaches. We then evaluate on the task of 3D inpainting, establishing state-ofthe-art performance against other NeRF manipulation algorithms, as well as a strong 2D image inpainter baseline
Day-to-Night Image Synthesis for Training Nighttime Neural ISPs
Jun 06, 2022
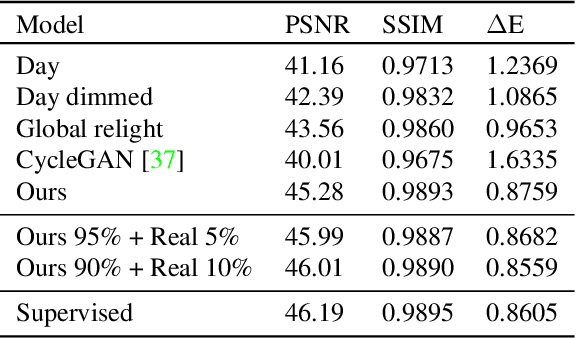

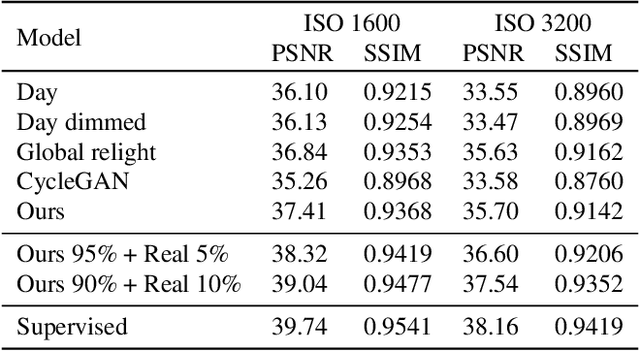
Many flagship smartphone cameras now use a dedicated neural image signal processor (ISP) to render noisy raw sensor images to the final processed output. Training nightmode ISP networks relies on large-scale datasets of image pairs with: (1) a noisy raw image captured with a short exposure and a high ISO gain; and (2) a ground truth low-noise raw image captured with a long exposure and low ISO that has been rendered through the ISP. Capturing such image pairs is tedious and time-consuming, requiring careful setup to ensure alignment between the image pairs. In addition, ground truth images are often prone to motion blur due to the long exposure. To address this problem, we propose a method that synthesizes nighttime images from daytime images. Daytime images are easy to capture, exhibit low-noise (even on smartphone cameras) and rarely suffer from motion blur. We outline a processing framework to convert daytime raw images to have the appearance of realistic nighttime raw images with different levels of noise. Our procedure allows us to easily produce aligned noisy and clean nighttime image pairs. We show the effectiveness of our synthesis framework by training neural ISPs for nightmode rendering. Furthermore, we demonstrate that using our synthetic nighttime images together with small amounts of real data (e.g., 5% to 10%) yields performance almost on par with training exclusively on real nighttime images. Our dataset and code are available at https://github.com/SamsungLabs/day-to-night.