 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved Mapping Between Illuminations and Sensors for RAW Images
Aug 20, 2025RAW images are unprocessed camera sensor output with sensor-specific RGB values based on the sensor's color filter spectral sensitivities. RAW images also incur strong color casts due to the sensor's response to the spectral properties of scene illumination. The sensor- and illumination-specific nature of RAW images makes it challenging to capture RAW datasets for deep learning methods, as scenes need to be captured for each sensor and under a wide range of illumination. Methods for illumination augmentation for a given sensor and the ability to map RAW images between sensors are important for reducing the burden of data capture. To explore this problem, we introduce the first-of-its-kind dataset comprising carefully captured scenes under a wide range of illumination. Specifically, we use a customized lightbox with tunable illumination spectra to capture several scenes with different cameras. Our illumination and sensor mapping dataset has 390 illuminations, four cameras, and 18 scenes. Using this dataset, we introduce a lightweight neural network approach for illumination and sensor mapping that outperforms competing methods. We demonstrate the utility of our approach on the downstream task of training a neural ISP. Link to project page: https://github.com/SamsungLabs/illum-sensor-mapping.
What Do You See? Enhancing Zero-Shot Image Classification with Multimodal Large Language Models
May 24, 2024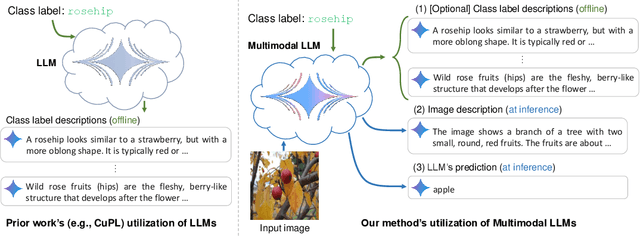
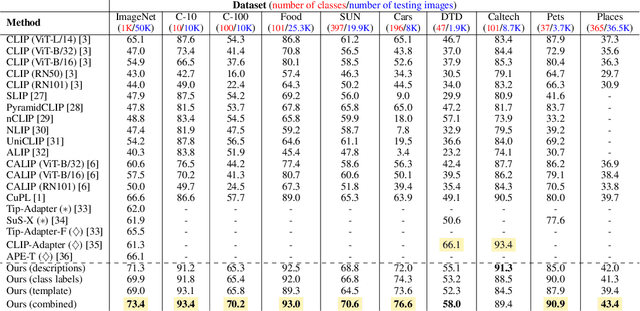
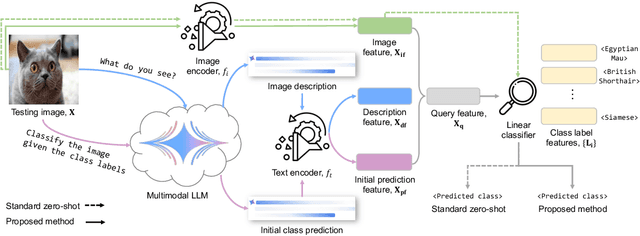
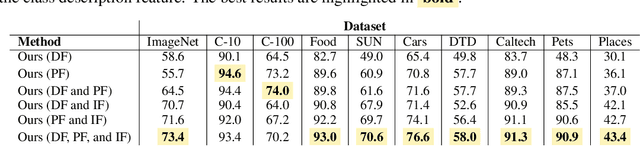
Large language models (LLMs) has been effectively used for many computer vision tasks, including image classification. In this paper, we present a simple yet effective approach for zero-shot image classification using multimodal LLMs. By employing multimodal LLMs, we generate comprehensive textual representations from input images. These textual representations are then utilized to generate fixed-dimensional features in a cross-modal embedding space. Subsequently, these features are fused together to perform zero-shot classification using a linear classifier. Our method does not require prompt engineering for each dataset; instead, we use a single, straightforward, set of prompts across all datasets. We evaluated our method on several datasets, and our results demonstrate its remarkable effectiveness, surpassing benchmark accuracy on multiple datasets. On average over ten benchmarks, our method achieved an accuracy gain of 4.1 percentage points, with an increase of 6.8 percentage points on the ImageNet dataset, compared to prior methods. Our findings highlight the potential of multimodal LLMs to enhance computer vision tasks such as zero-shot image classification, offering a significant improvement over traditional methods.
Day-to-Night Image Synthesis for Training Nighttime Neural ISPs
Jun 06, 2022
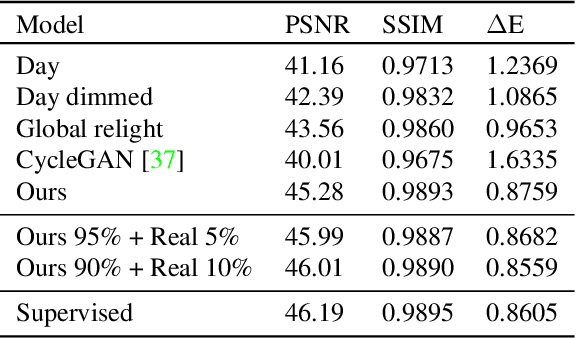

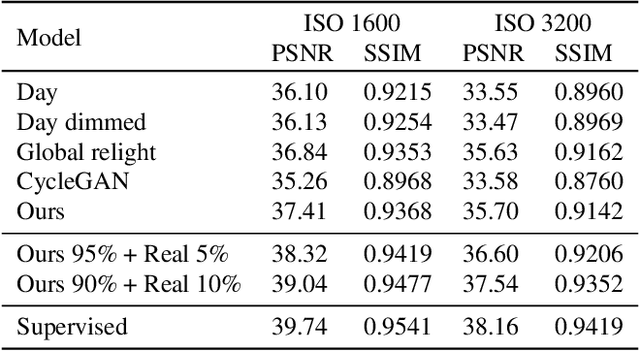
Many flagship smartphone cameras now use a dedicated neural image signal processor (ISP) to render noisy raw sensor images to the final processed output. Training nightmode ISP networks relies on large-scale datasets of image pairs with: (1) a noisy raw image captured with a short exposure and a high ISO gain; and (2) a ground truth low-noise raw image captured with a long exposure and low ISO that has been rendered through the ISP. Capturing such image pairs is tedious and time-consuming, requiring careful setup to ensure alignment between the image pairs. In addition, ground truth images are often prone to motion blur due to the long exposure. To address this problem, we propose a method that synthesizes nighttime images from daytime images. Daytime images are easy to capture, exhibit low-noise (even on smartphone cameras) and rarely suffer from motion blur. We outline a processing framework to convert daytime raw images to have the appearance of realistic nighttime raw images with different levels of noise. Our procedure allows us to easily produce aligned noisy and clean nighttime image pairs. We show the effectiveness of our synthesis framework by training neural ISPs for nightmode rendering. Furthermore, we demonstrate that using our synthetic nighttime images together with small amounts of real data (e.g., 5% to 10%) yields performance almost on par with training exclusively on real nighttime images. Our dataset and code are available at https://github.com/SamsungLabs/day-to-night.
CIE XYZ Net: Unprocessing Images for Low-Level Computer Vision Tasks
Jun 23, 2020

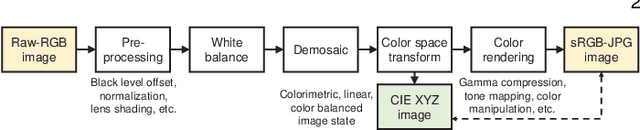

Cameras currently allow access to two image states: (i) a minimally processed linear raw-RGB image state (i.e., raw sensor data) or (ii) a highly-processed nonlinear image state (e.g., sRGB). There are many computer vision tasks that work best with a linear image state, such as image deblurring and image dehazing. Unfortunately, the vast majority of images are saved in the nonlinear image state. Because of this, a number of methods have been proposed to "unprocess" nonlinear images back to a raw-RGB state. However, existing unprocessing methods have a drawback because raw-RGB images are sensor-specific. As a result, it is necessary to know which camera produced the sRGB output and use a method or network tailored for that sensor to properly unprocess it. This paper addresses this limitation by exploiting another camera image state that is not available as an output, but it is available inside the camera pipeline. In particular, cameras apply a colorimetric conversion step to convert the raw-RGB image to a device-independent space based on the CIE XYZ color space before they apply the nonlinear photo-finishing. Leveraging this canonical image state, we propose a deep learning framework, CIE XYZ Net, that can unprocess a nonlinear image back to the canonical CIE XYZ image. This image can then be processed by any low-level computer vision operator and re-rendered back to the nonlinear image. We demonstrate the usefulness of the CIE XYZ Net on several low-level vision tasks and show significant gains that can be obtained by this processing framework. Code and dataset are publicly available at https://github.com/mahmoudnafifi/CIE_XYZ_NET.
NTIRE 2020 Challenge on Real Image Denoising: Dataset, Methods and Results
May 08, 2020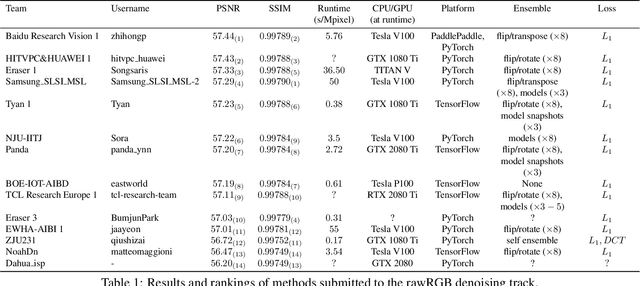
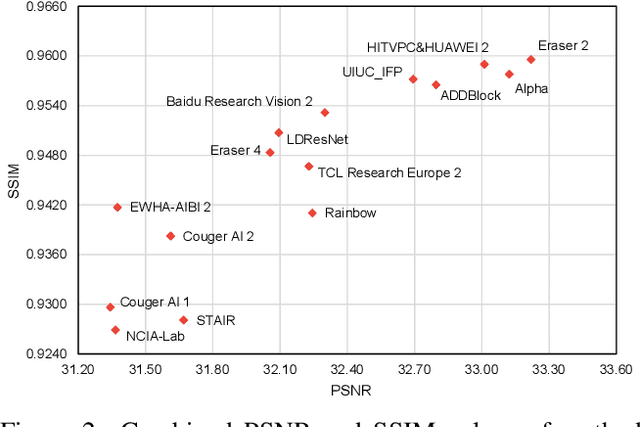
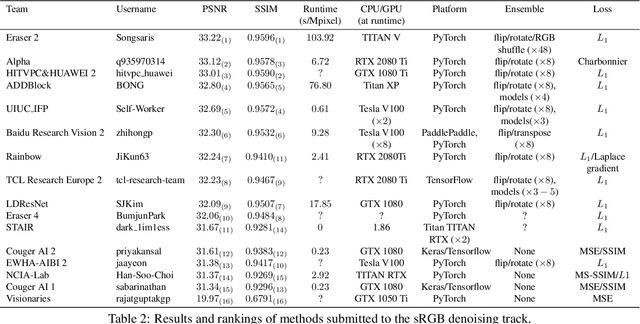
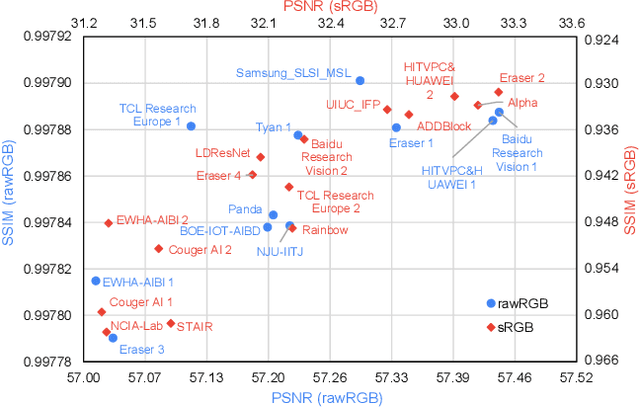
This paper reviews the NTIRE 2020 challenge on real image denoising with focus on the newly introduced dataset, the proposed methods and their results. The challenge is a new version of the previous NTIRE 2019 challenge on real image denoising that was based on the SIDD benchmark. This challenge is based on a newly collected validation and testing image datasets, and hence, named SIDD+. This challenge has two tracks for quantitatively evaluating image denoising performance in (1) the Bayer-pattern rawRGB and (2) the standard RGB (sRGB) color spaces. Each track ~250 registered participants. A total of 22 teams, proposing 24 methods, competed in the final phase of the challenge. The proposed methods by the participating teams represent the current state-of-the-art performance in image denoising targeting real noisy images. The newly collected SIDD+ datasets are publicly available at: https://bit.ly/siddplus_data.
Noise Flow: Noise Modeling with Conditional Normalizing Flows
Aug 22, 2019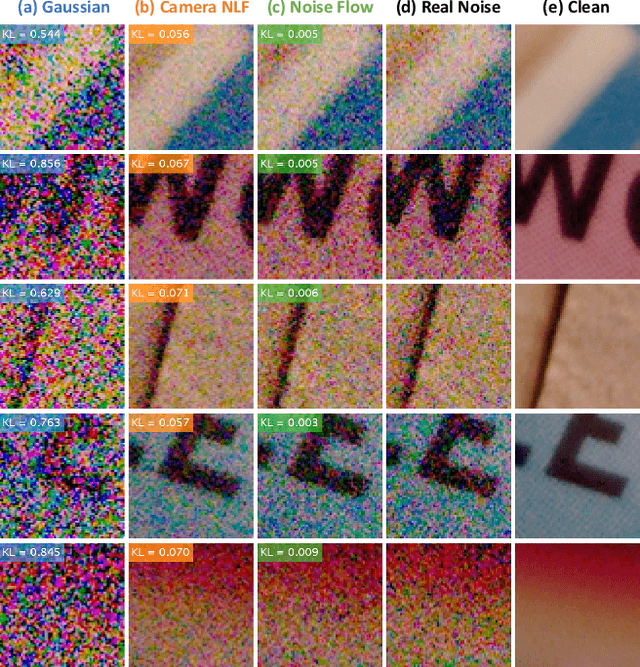


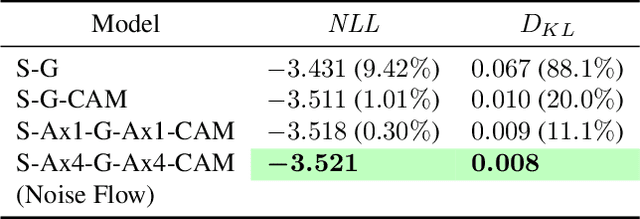
Modeling and synthesizing image noise is an important aspect in many computer vision applications. The long-standing additive white Gaussian and heteroscedastic (signal-dependent) noise models widely used in the literature provide only a coarse approximation of real sensor noise. This paper introduces Noise Flow, a powerful and accurate noise model based on recent normalizing flow architectures. Noise Flow combines well-established basic parametric noise models (e.g., signal-dependent noise) with the flexibility and expressiveness of normalizing flow networks. The result is a single, comprehensive, compact noise model containing fewer than 2500 parameters yet able to represent multiple cameras and gain factors. Noise Flow dramatically outperforms existing noise models, with 0.42 nats/pixel improvement over the camera-calibrated noise level functions, which translates to 52% improvement in the likelihood of sampled noise. Noise Flow represents the first serious attempt to go beyond simple parametric models to one that leverages the power of deep learning and data-driven noise distributions.
AFIF4: Deep Gender Classification based on AdaBoost-based Fusion of Isolated Facial Features and Foggy Faces
Nov 18, 2017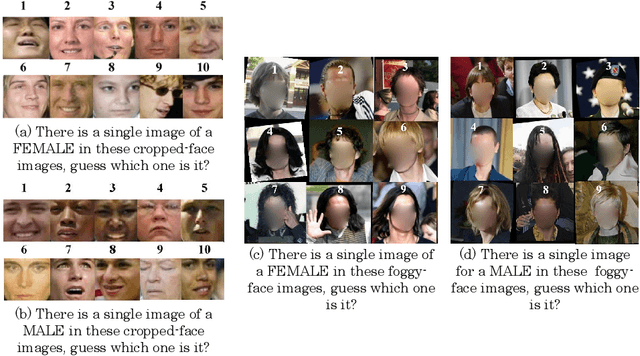
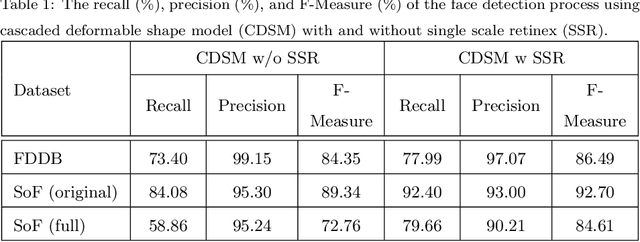

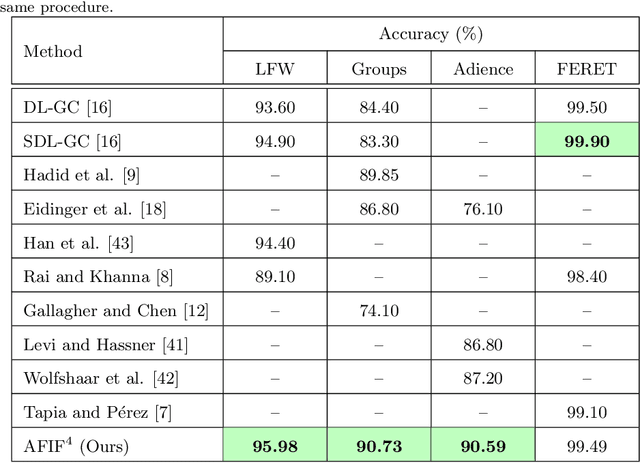
Gender classification aims at recognizing a person's gender. Despite the high accuracy achieved by state-of-the-art methods for this task, there is still room for improvement in generalized and unrestricted datasets. In this paper, we advocate a new strategy inspired by the behavior of humans in gender recognition. Instead of dealing with the face image as a sole feature, we rely on the combination of isolated facial features and a holistic feature which we call the foggy face. Then, we use these features to train deep convolutional neural networks followed by an AdaBoost-based score fusion to infer the final gender class. We evaluate our method on four challenging datasets to demonstrate its efficacy in achieving better or on-par accuracy with state-of-the-art methods. In addition, we present a new face dataset that intensifies the challenges of occluded faces and illumination changes, which we believe to be a much-needed resource for gender classification research.