 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge360Anything: Geometry-Free Lifting of Images and Videos to 360°
Jan 22, 2026Lifting perspective images and videos to 360° panoramas enables immersive 3D world generation. Existing approaches often rely on explicit geometric alignment between the perspective and the equirectangular projection (ERP) space. Yet, this requires known camera metadata, obscuring the application to in-the-wild data where such calibration is typically absent or noisy. We propose 360Anything, a geometry-free framework built upon pre-trained diffusion transformers. By treating the perspective input and the panorama target simply as token sequences, 360Anything learns the perspective-to-equirectangular mapping in a purely data-driven way, eliminating the need for camera information. Our approach achieves state-of-the-art performance on both image and video perspective-to-360° generation, outperforming prior works that use ground-truth camera information. We also trace the root cause of the seam artifacts at ERP boundaries to zero-padding in the VAE encoder, and introduce Circular Latent Encoding to facilitate seamless generation. Finally, we show competitive results in zero-shot camera FoV and orientation estimation benchmarks, demonstrating 360Anything's deep geometric understanding and broader utility in computer vision tasks. Additional results are available at https://360anything.github.io/.
Reconstructing Heterogeneous Biomolecules via Hierarchical Gaussian Mixtures and Part Discovery
Jun 06, 2025


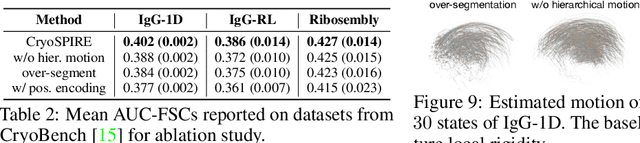
Cryo-EM is a transformational paradigm in molecular biology where computational methods are used to infer 3D molecular structure at atomic resolution from extremely noisy 2D electron microscope images. At the forefront of research is how to model the structure when the imaged particles exhibit non-rigid conformational flexibility and compositional variation where parts are sometimes missing. We introduce a novel 3D reconstruction framework with a hierarchical Gaussian mixture model, inspired in part by Gaussian Splatting for 4D scene reconstruction. In particular, the structure of the model is grounded in an initial process that infers a part-based segmentation of the particle, providing essential inductive bias in order to handle both conformational and compositional variability. The framework, called CryoSPIRE, is shown to reveal biologically meaningful structures on complex experimental datasets, and establishes a new state-of-the-art on CryoBench, a benchmark for cryo-EM heterogeneity methods.
Geometry-Aware Texture Generation for 3D Head Modeling with Artist-driven Control
May 07, 2025Creating realistic 3D head assets for virtual characters that match a precise artistic vision remains labor-intensive. We present a novel framework that streamlines this process by providing artists with intuitive control over generated 3D heads. Our approach uses a geometry-aware texture synthesis pipeline that learns correlations between head geometry and skin texture maps across different demographics. The framework offers three levels of artistic control: manipulation of overall head geometry, adjustment of skin tone while preserving facial characteristics, and fine-grained editing of details such as wrinkles or facial hair. Our pipeline allows artists to make edits to a single texture map using familiar tools, with our system automatically propagating these changes coherently across the remaining texture maps needed for realistic rendering. Experiments demonstrate that our method produces diverse results with clean geometries. We showcase practical applications focusing on intuitive control for artists, including skin tone adjustments and simplified editing workflows for adding age-related details or removing unwanted features from scanned models. This integrated approach aims to streamline the artistic workflow in virtual character creation.
Learn Your Scales: Towards Scale-Consistent Generative Novel View Synthesis
Mar 19, 2025Conventional depth-free multi-view datasets are captured using a moving monocular camera without metric calibration. The scales of camera positions in this monocular setting are ambiguous. Previous methods have acknowledged scale ambiguity in multi-view data via various ad-hoc normalization pre-processing steps, but have not directly analyzed the effect of incorrect scene scales on their application. In this paper, we seek to understand and address the effect of scale ambiguity when used to train generative novel view synthesis methods (GNVS). In GNVS, new views of a scene or object can be minimally synthesized given a single image and are, thus, unconstrained, necessitating the use of generative methods. The generative nature of these models captures all aspects of uncertainty, including any uncertainty of scene scales, which act as nuisance variables for the task. We study the effect of scene scale ambiguity in GNVS when sampled from a single image by isolating its effect on the resulting models and, based on these intuitions, define new metrics that measure the scale inconsistency of generated views. We then propose a framework to estimate scene scales jointly with the GNVS model in an end-to-end fashion. Empirically, we show that our method reduces the scale inconsistency of generated views without the complexity or downsides of previous scale normalization methods. Further, we show that removing this ambiguity improves generated image quality of the resulting GNVS model.
Geometry-Aware Diffusion Models for Multiview Scene Inpainting
Feb 18, 2025In this paper, we focus on 3D scene inpainting, where parts of an input image set, captured from different viewpoints, are masked out. The main challenge lies in generating plausible image completions that are geometrically consistent across views. Most recent work addresses this challenge by combining generative models with a 3D radiance field to fuse information across viewpoints. However, a major drawback of these methods is that they often produce blurry images due to the fusion of inconsistent cross-view images. To avoid blurry inpaintings, we eschew the use of an explicit or implicit radiance field altogether and instead fuse cross-view information in a learned space. In particular, we introduce a geometry-aware conditional generative model, capable of inpainting multi-view consistent images based on both geometric and appearance cues from reference images. A key advantage of our approach over existing methods is its unique ability to inpaint masked scenes with a limited number of views (i.e., few-view inpainting), whereas previous methods require relatively large image sets for their 3D model fitting step. Empirically, we evaluate and compare our scene-centric inpainting method on two datasets, SPIn-NeRF and NeRFiller, which contain images captured at narrow and wide baselines, respectively, and achieve state-of-the-art 3D inpainting performance on both. Additionally, we demonstrate the efficacy of our approach in the few-view setting compared to prior methods.
Efficient Neural Network Encoding for 3D Color Lookup Tables
Dec 19, 2024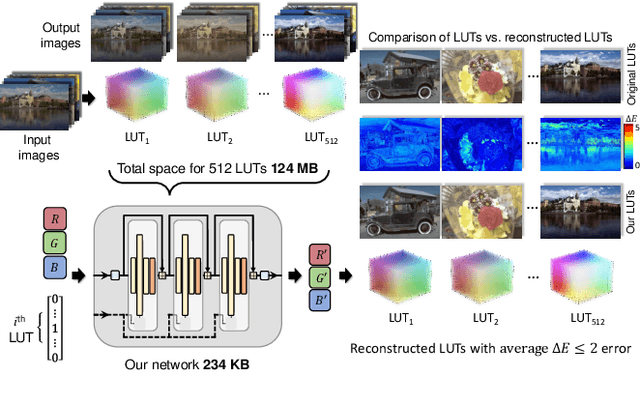

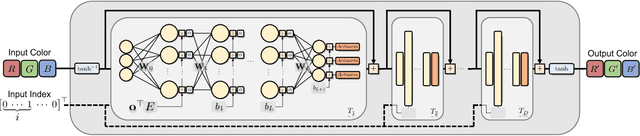

3D color lookup tables (LUTs) enable precise color manipulation by mapping input RGB values to specific output RGB values. 3D LUTs are instrumental in various applications, including video editing, in-camera processing, photographic filters, computer graphics, and color processing for displays. While an individual LUT does not incur a high memory overhead, software and devices may need to store dozens to hundreds of LUTs that can take over 100 MB. This work aims to develop a neural network architecture that can encode hundreds of LUTs in a single compact representation. To this end, we propose a model with a memory footprint of less than 0.25 MB that can reconstruct 512 LUTs with only minor color distortion ($\bar{\Delta}E_M$ $\leq$ 2.0) over the entire color gamut. We also show that our network can weight colors to provide further quality gains on natural image colors ($\bar{\Delta}{E}_M$ $\leq$ 1.0). Finally, we show that minor modifications to the network architecture enable a bijective encoding that produces LUTs that are invertible, allowing for reverse color processing. Our code is available at https://github.com/vahidzee/ennelut.
Improving Ab-Initio Cryo-EM Reconstruction with Semi-Amortized Pose Inference
Jun 15, 2024
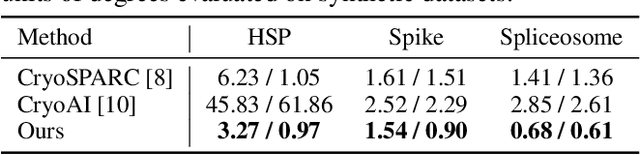


Cryo-Electron Microscopy (cryo-EM) is an increasingly popular experimental technique for estimating the 3D structure of macromolecular complexes such as proteins based on 2D images. These images are notoriously noisy, and the pose of the structure in each image is unknown \textit{a priori}. Ab-initio 3D reconstruction from 2D images entails estimating the pose in addition to the structure. In this work, we propose a new approach to this problem. We first adopt a multi-head architecture as a pose encoder to infer multiple plausible poses per-image in an amortized fashion. This approach mitigates the high uncertainty in pose estimation by encouraging exploration of pose space early in reconstruction. Once uncertainty is reduced, we refine poses in an auto-decoding fashion. In particular, we initialize with the most likely pose and iteratively update it for individual images using stochastic gradient descent (SGD). Through evaluation on synthetic datasets, we demonstrate that our method is able to handle multi-modal pose distributions during the amortized inference stage, while the later, more flexible stage of direct pose optimization yields faster and more accurate convergence of poses compared to baselines. Finally, on experimental data, we show that our approach is faster than state-of-the-art cryoAI and achieves higher-resolution reconstruction.
PolyOculus: Simultaneous Multi-view Image-based Novel View Synthesis
Feb 28, 2024
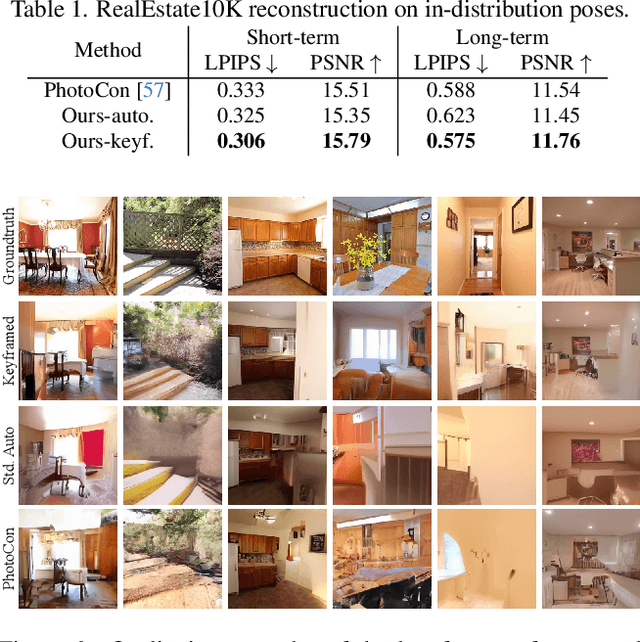
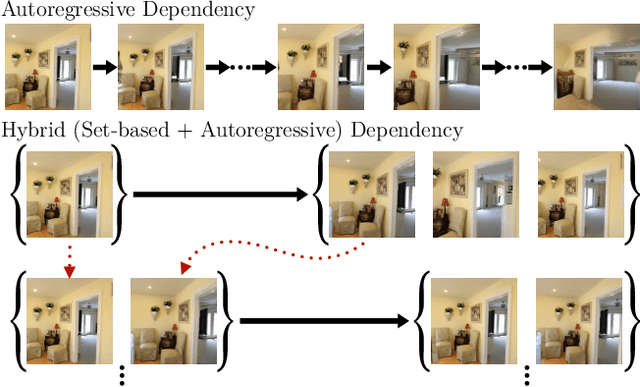

This paper considers the problem of generative novel view synthesis (GNVS), generating novel, plausible views of a scene given a limited number of known views. Here, we propose a set-based generative model that can simultaneously generate multiple, self-consistent new views, conditioned on any number of known views. Our approach is not limited to generating a single image at a time and can condition on zero, one, or more views. As a result, when generating a large number of views, our method is not restricted to a low-order autoregressive generation approach and is better able to maintain generated image quality over large sets of images. We evaluate the proposed model on standard NVS datasets and show that it outperforms the state-of-the-art image-based GNVS baselines. Further, we show that the model is capable of generating sets of camera views that have no natural sequential ordering, like loops and binocular trajectories, and significantly outperforms other methods on such tasks.
Reconstructive Latent-Space Neural Radiance Fields for Efficient 3D Scene Representations
Oct 27, 2023



Neural Radiance Fields (NeRFs) have proven to be powerful 3D representations, capable of high quality novel view synthesis of complex scenes. While NeRFs have been applied to graphics, vision, and robotics, problems with slow rendering speed and characteristic visual artifacts prevent adoption in many use cases. In this work, we investigate combining an autoencoder (AE) with a NeRF, in which latent features (instead of colours) are rendered and then convolutionally decoded. The resulting latent-space NeRF can produce novel views with higher quality than standard colour-space NeRFs, as the AE can correct certain visual artifacts, while rendering over three times faster. Our work is orthogonal to other techniques for improving NeRF efficiency. Further, we can control the tradeoff between efficiency and image quality by shrinking the AE architecture, achieving over 13 times faster rendering with only a small drop in performance. We hope that our approach can form the basis of an efficient, yet high-fidelity, 3D scene representation for downstream tasks, especially when retaining differentiability is useful, as in many robotics scenarios requiring continual learning.
Dual-Camera Joint Deblurring-Denoising
Sep 16, 2023Recent image enhancement methods have shown the advantages of using a pair of long and short-exposure images for low-light photography. These image modalities offer complementary strengths and weaknesses. The former yields an image that is clean but blurry due to camera or object motion, whereas the latter is sharp but noisy due to low photon count. Motivated by the fact that modern smartphones come equipped with multiple rear-facing camera sensors, we propose a novel dual-camera method for obtaining a high-quality image. Our method uses a synchronized burst of short exposure images captured by one camera and a long exposure image simultaneously captured by another. Having a synchronized short exposure burst alongside the long exposure image enables us to (i) obtain better denoising by using a burst instead of a single image, (ii) recover motion from the burst and use it for motion-aware deblurring of the long exposure image, and (iii) fuse the two results to further enhance quality. Our method is able to achieve state-of-the-art results on synthetic dual-camera images from the GoPro dataset with five times fewer training parameters compared to the next best method. We also show that our method qualitatively outperforms competing approaches on real synchronized dual-camera captures.