 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Neural Network Encoding for 3D Color Lookup Tables
Dec 19, 2024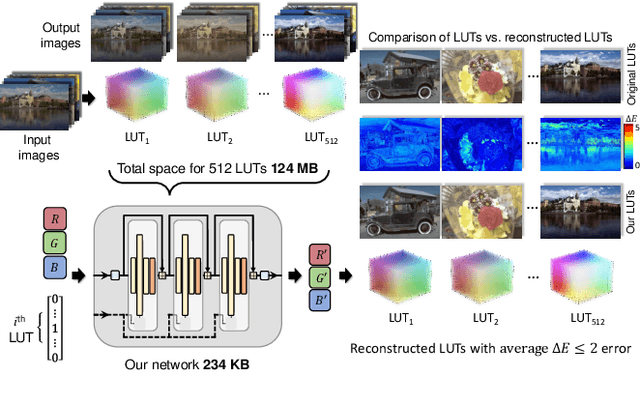

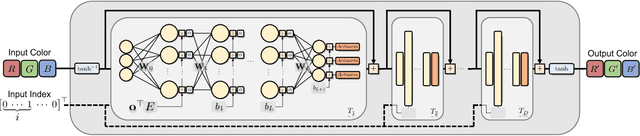

3D color lookup tables (LUTs) enable precise color manipulation by mapping input RGB values to specific output RGB values. 3D LUTs are instrumental in various applications, including video editing, in-camera processing, photographic filters, computer graphics, and color processing for displays. While an individual LUT does not incur a high memory overhead, software and devices may need to store dozens to hundreds of LUTs that can take over 100 MB. This work aims to develop a neural network architecture that can encode hundreds of LUTs in a single compact representation. To this end, we propose a model with a memory footprint of less than 0.25 MB that can reconstruct 512 LUTs with only minor color distortion ($\bar{\Delta}E_M$ $\leq$ 2.0) over the entire color gamut. We also show that our network can weight colors to provide further quality gains on natural image colors ($\bar{\Delta}{E}_M$ $\leq$ 1.0). Finally, we show that minor modifications to the network architecture enable a bijective encoding that produces LUTs that are invertible, allowing for reverse color processing. Our code is available at https://github.com/vahidzee/ennelut.
OCDaf: Ordered Causal Discovery with Autoregressive Flows
Aug 14, 2023



We propose OCDaf, a novel order-based method for learning causal graphs from observational data. We establish the identifiability of causal graphs within multivariate heteroscedastic noise models, a generalization of additive noise models that allow for non-constant noise variances. Drawing upon the structural similarities between these models and affine autoregressive normalizing flows, we introduce a continuous search algorithm to find causal structures. Our experiments demonstrate state-of-the-art performance across the Sachs and SynTReN benchmarks in Structural Hamming Distance (SHD) and Structural Intervention Distance (SID). Furthermore, we validate our identifiability theory across various parametric and nonparametric synthetic datasets and showcase superior performance compared to existing baselines.
SVG-Net: An SVG-based Trajectory Prediction Model
Oct 11, 2021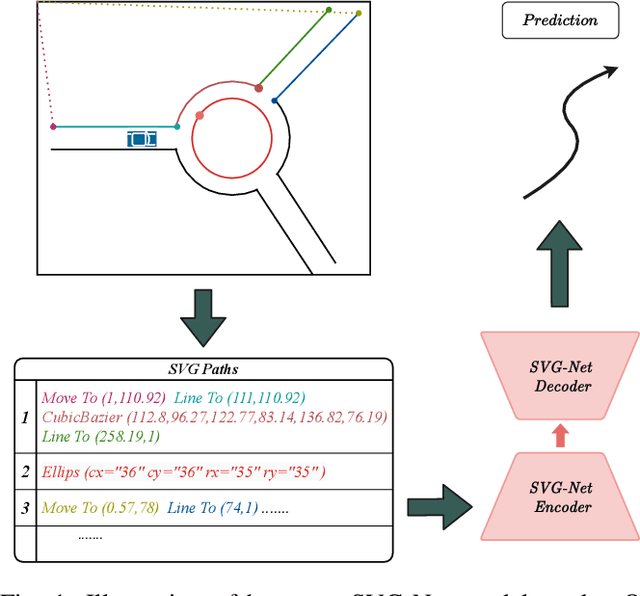
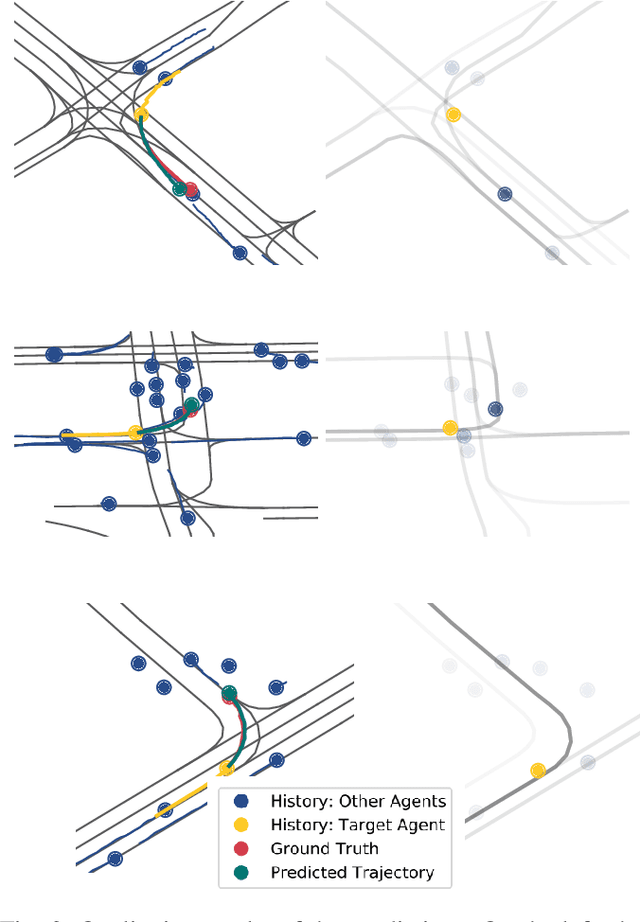
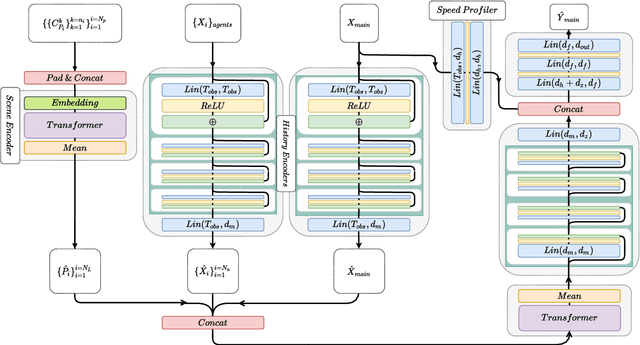
Anticipating motions of vehicles in a scene is an essential problem for safe autonomous driving systems. To this end, the comprehension of the scene's infrastructure is often the main clue for predicting future trajectories. Most of the proposed approaches represent the scene with a rasterized format and some of the more recent approaches leverage custom vectorized formats. In contrast, we propose representing the scene's information by employing Scalable Vector Graphics (SVG). SVG is a well-established format that matches the problem of trajectory prediction better than rasterized formats while being more general than arbitrary vectorized formats. SVG has the potential to provide the convenience and generality of raster-based solutions if coupled with a powerful tool such as CNNs, for which we introduce SVG-Net. SVG-Net is a Transformer-based Neural Network that can effectively capture the scene's information from SVG inputs. Thanks to the self-attention mechanism in its Transformers, SVG-Net can also adequately apprehend relations amongst the scene and the agents. We demonstrate SVG-Net's effectiveness by evaluating its performance on the publicly available Argoverse forecasting dataset. Finally, we illustrate how, by using SVG, one can benefit from datasets and advancements in other research fronts that also utilize the same input format. Our code is available at https://vita-epfl.github.io/SVGNet/.