 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSocial-Pose: Enhancing Trajectory Prediction with Human Body Pose
Jul 30, 2025
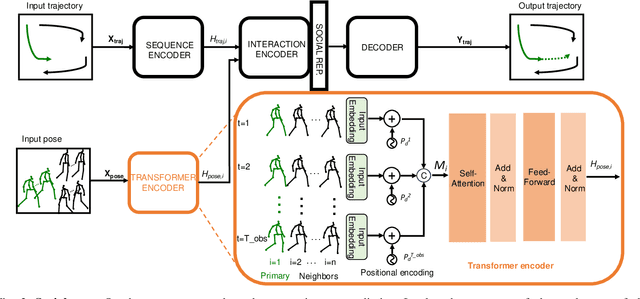
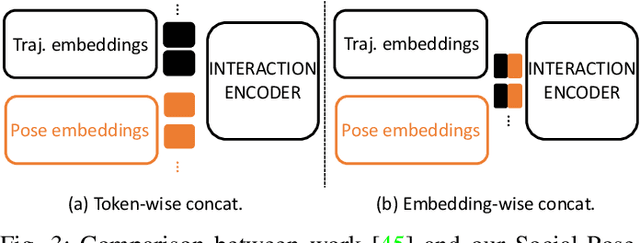
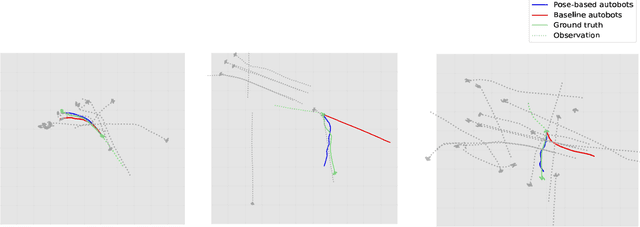
Accurate human trajectory prediction is one of the most crucial tasks for autonomous driving, ensuring its safety. Yet, existing models often fail to fully leverage the visual cues that humans subconsciously communicate when navigating the space. In this work, we study the benefits of predicting human trajectories using human body poses instead of solely their Cartesian space locations in time. We propose `Social-pose', an attention-based pose encoder that effectively captures the poses of all humans in a scene and their social relations. Our method can be integrated into various trajectory prediction architectures. We have conducted extensive experiments on state-of-the-art models (based on LSTM, GAN, MLP, and Transformer), and showed improvements over all of them on synthetic (Joint Track Auto) and real (Human3.6M, Pedestrians and Cyclists in Road Traffic, and JRDB) datasets. We also explored the advantages of using 2D versus 3D poses, as well as the effect of noisy poses and the application of our pose-based predictor in robot navigation scenarios.
MotionMap: Representing Multimodality in Human Pose Forecasting
Dec 25, 2024Human pose forecasting is inherently multimodal since multiple futures exist for an observed pose sequence. However, evaluating multimodality is challenging since the task is ill-posed. Therefore, we first propose an alternative paradigm to make the task well-posed. Next, while state-of-the-art methods predict multimodality, this requires oversampling a large volume of predictions. This raises key questions: (1) Can we capture multimodality by efficiently sampling a smaller number of predictions? (2) Subsequently, which of the predicted futures is more likely for an observed pose sequence? We address these questions with MotionMap, a simple yet effective heatmap based representation for multimodality. We extend heatmaps to represent a spatial distribution over the space of all possible motions, where different local maxima correspond to different forecasts for a given observation. MotionMap can capture a variable number of modes per observation and provide confidence measures for different modes. Further, MotionMap allows us to introduce the notion of uncertainty and controllability over the forecasted pose sequence. Finally, MotionMap captures rare modes that are non-trivial to evaluate yet critical for safety. We support our claims through multiple qualitative and quantitative experiments using popular 3D human pose datasets: Human3.6M and AMASS, highlighting the strengths and limitations of our proposed method. Project Page: https://www.epfl.ch/labs/vita/research/prediction/motionmap/
Certified Human Trajectory Prediction
Mar 20, 2024Trajectory prediction plays an essential role in autonomous vehicles. While numerous strategies have been developed to enhance the robustness of trajectory prediction models, these methods are predominantly heuristic and do not offer guaranteed robustness against adversarial attacks and noisy observations. In this work, we propose a certification approach tailored for the task of trajectory prediction. To this end, we address the inherent challenges associated with trajectory prediction, including unbounded outputs, and mutli-modality, resulting in a model that provides guaranteed robustness. Furthermore, we integrate a denoiser into our method to further improve the performance. Through comprehensive evaluations, we demonstrate the effectiveness of the proposed technique across various baselines and using standard trajectory prediction datasets. The code will be made available online: https://s-attack.github.io/
Social-Transmotion: Promptable Human Trajectory Prediction
Dec 26, 2023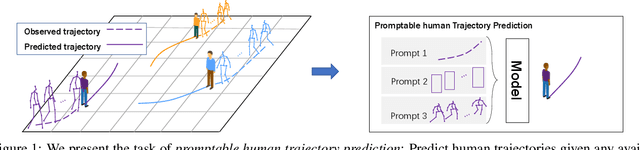
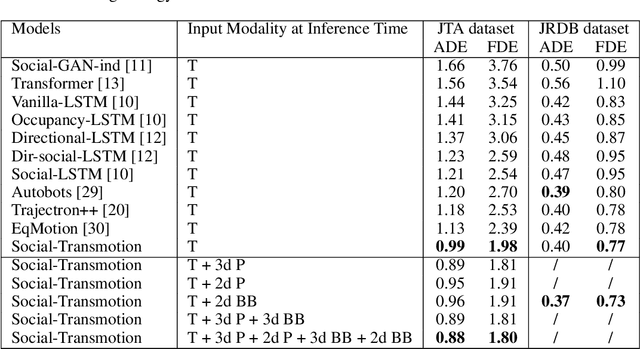
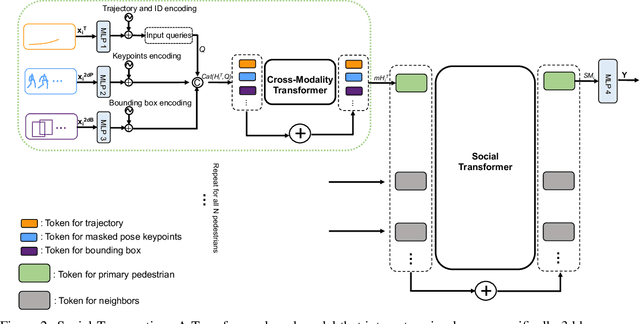

Accurate human trajectory prediction is crucial for applications such as autonomous vehicles, robotics, and surveillance systems. Yet, existing models often fail to fully leverage the non-verbal social cues human subconsciously communicate when navigating the space. To address this, we introduce Social-Transmotion, a generic model that exploits the power of transformers to handle diverse and numerous visual cues, capturing the multi-modal nature of human behavior. We translate the idea of a prompt from Natural Language Processing (NLP) to the task of human trajectory prediction, where a prompt can be a sequence of x-y coordinates on the ground, bounding boxes or body poses. This, in turn, augments trajectory data, leading to enhanced human trajectory prediction. Our model exhibits flexibility and adaptability by capturing spatiotemporal interactions between pedestrians based on the available visual cues, whether they are poses, bounding boxes, or a combination thereof. By the masking technique, we ensure our model's effectiveness even when certain visual cues are unavailable, although performance is further boosted with the presence of comprehensive visual data. We delve into the merits of using 2d versus 3d poses, and a limited set of poses. Additionally, we investigate the spatial and temporal attention map to identify which keypoints and frames of poses are vital for optimizing human trajectory prediction. Our approach is validated on multiple datasets, including JTA, JRDB, Pedestrians and Cyclists in Road Traffic, and ETH-UCY. The code is publicly available: https://github.com/vita-epfl/social-transmotion
JRDB-Traj: A Dataset and Benchmark for Trajectory Forecasting in Crowds
Nov 05, 2023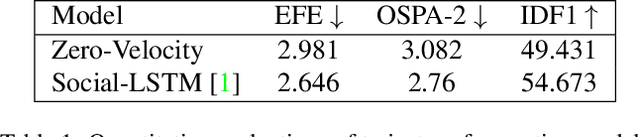
Predicting future trajectories is critical in autonomous navigation, especially in preventing accidents involving humans, where a predictive agent's ability to anticipate in advance is of utmost importance. Trajectory forecasting models, employed in fields such as robotics, autonomous vehicles, and navigation, face challenges in real-world scenarios, often due to the isolation of model components. To address this, we introduce a novel dataset for end-to-end trajectory forecasting, facilitating the evaluation of models in scenarios involving less-than-ideal preceding modules such as tracking. This dataset, an extension of the JRDB dataset, provides comprehensive data, including the locations of all agents, scene images, and point clouds, all from the robot's perspective. The objective is to predict the future positions of agents relative to the robot using raw sensory input data. It bridges the gap between isolated models and practical applications, promoting a deeper understanding of navigation dynamics. Additionally, we introduce a novel metric for assessing trajectory forecasting models in real-world scenarios where ground-truth identities are inaccessible, addressing issues related to undetected or over-detected agents. Researchers are encouraged to use our benchmark for model evaluation and benchmarking.
Toward Reliable Human Pose Forecasting with Uncertainty
Apr 13, 2023
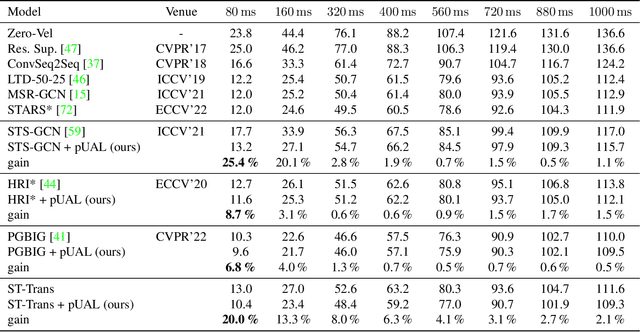
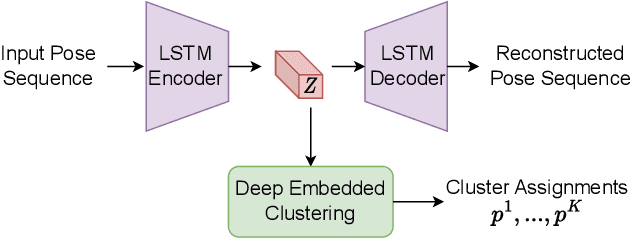
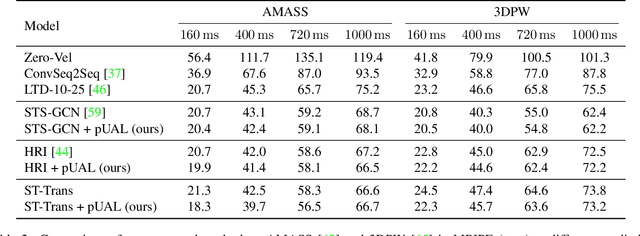
Recently, there has been an arms race of pose forecasting methods aimed at solving the spatio-temporal task of predicting a sequence of future 3D poses of a person given a sequence of past observed ones. However, the lack of unified benchmarks and limited uncertainty analysis have hindered progress in the field. To address this, we first develop an open-source library for human pose forecasting, featuring multiple models, datasets, and standardized evaluation metrics, with the aim of promoting research and moving toward a unified and fair evaluation. Second, we devise two types of uncertainty in the problem to increase performance and convey better trust: 1) we propose a method for modeling aleatoric uncertainty by using uncertainty priors to inject knowledge about the behavior of uncertainty. This focuses the capacity of the model in the direction of more meaningful supervision while reducing the number of learned parameters and improving stability; 2) we introduce a novel approach for quantifying the epistemic uncertainty of any model through clustering and measuring the entropy of its assignments. Our experiments demonstrate up to $25\%$ improvements in accuracy and better performance in uncertainty estimation.
A generic diffusion-based approach for 3D human pose prediction in the wild
Oct 11, 2022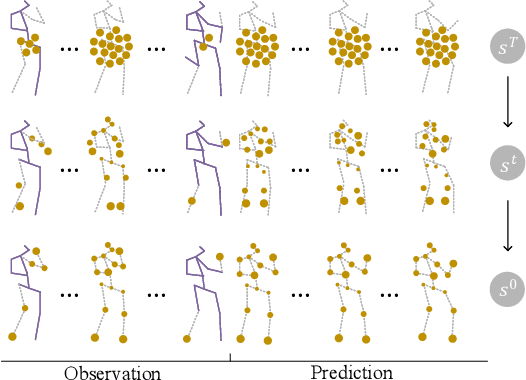
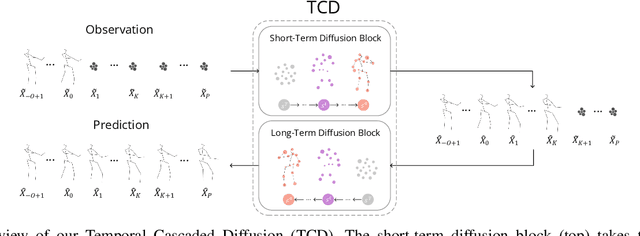

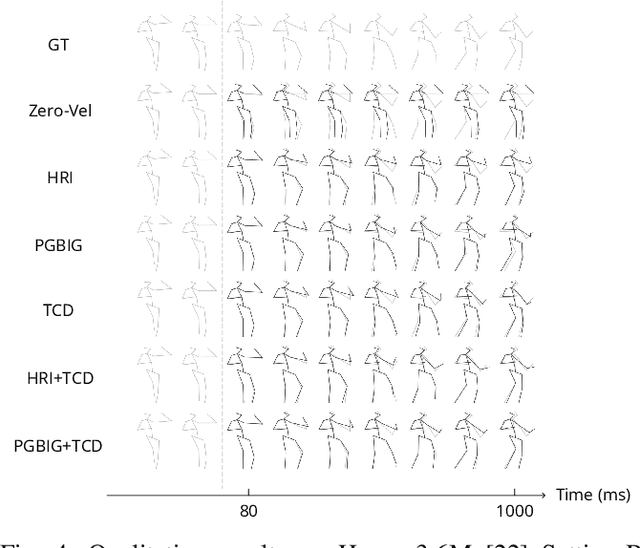
3D human pose forecasting, i.e., predicting a sequence of future human 3D poses given a sequence of past observed ones, is a challenging spatio-temporal task. It can be more challenging in real-world applications where occlusions will inevitably happen, and estimated 3D coordinates of joints would contain some noise. We provide a unified formulation in which incomplete elements (no matter in the prediction or observation) are treated as noise and propose a conditional diffusion model that denoises them and forecasts plausible poses. Instead of naively predicting all future frames at once, our model consists of two cascaded sub-models, each specialized for modeling short and long horizon distributions. We also propose a generic framework to improve any 3D pose forecasting model by leveraging our diffusion model in two additional steps: a pre-processing step to repair the inputs and a post-processing step to refine the outputs. We investigate our findings on four standard datasets (Human3.6M, HumanEva-I, AMASS, and 3DPW) and obtain significant improvements over the state-of-the-art. The code will be made available online.
Pedestrian 3D Bounding Box Prediction
Jun 28, 2022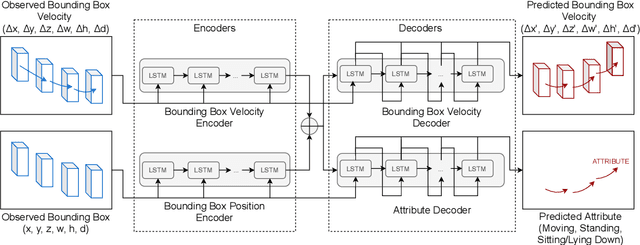



Safety is still the main issue of autonomous driving, and in order to be globally deployed, they need to predict pedestrians' motions sufficiently in advance. While there is a lot of research on coarse-grained (human center prediction) and fine-grained predictions (human body keypoints prediction), we focus on 3D bounding boxes, which are reasonable estimates of humans without modeling complex motion details for autonomous vehicles. This gives the flexibility to predict in longer horizons in real-world settings. We suggest this new problem and present a simple yet effective model for pedestrians' 3D bounding box prediction. This method follows an encoder-decoder architecture based on recurrent neural networks, and our experiments show its effectiveness in both the synthetic (JTA) and real-world (NuScenes) datasets. The learned representation has useful information to enhance the performance of other tasks, such as action anticipation. Our code is available online: https://github.com/vita-epfl/bounding-box-prediction
A Shared Representation for Photorealistic Driving Simulators
Dec 09, 2021
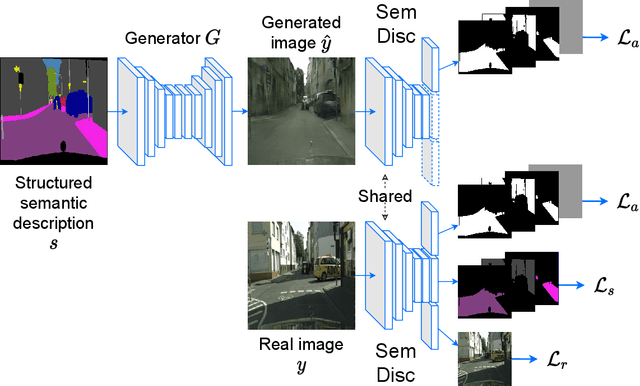


A powerful simulator highly decreases the need for real-world tests when training and evaluating autonomous vehicles. Data-driven simulators flourished with the recent advancement of conditional Generative Adversarial Networks (cGANs), providing high-fidelity images. The main challenge is synthesizing photorealistic images while following given constraints. In this work, we propose to improve the quality of generated images by rethinking the discriminator architecture. The focus is on the class of problems where images are generated given semantic inputs, such as scene segmentation maps or human body poses. We build on successful cGAN models to propose a new semantically-aware discriminator that better guides the generator. We aim to learn a shared latent representation that encodes enough information to jointly do semantic segmentation, content reconstruction, along with a coarse-to-fine grained adversarial reasoning. The achieved improvements are generic and simple enough to be applied to any architecture of conditional image synthesis. We demonstrate the strength of our method on the scene, building, and human synthesis tasks across three different datasets. The code is available at https://github.com/vita-epfl/SemDisc.
Vehicle trajectory prediction works, but not everywhere
Dec 07, 2021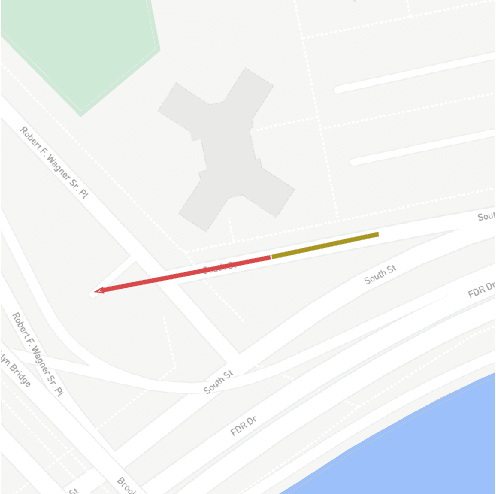


Vehicle trajectory prediction is nowadays a fundamental pillar of self-driving cars. Both the industry and research communities have acknowledged the need for such a pillar by running public benchmarks. While state-of-the-art methods are impressive, i.e., they have no off-road prediction, their generalization to cities outside of the benchmark is unknown. In this work, we show that those methods do not generalize to new scenes. We present a novel method that automatically generates realistic scenes that cause state-of-the-art models go off-road. We frame the problem through the lens of adversarial scene generation. We promote a simple yet effective generative model based on atomic scene generation functions along with physical constraints. Our experiments show that more than $60\%$ of the existing scenes from the current benchmarks can be modified in a way to make prediction methods fail (predicting off-road). We further show that (i) the generated scenes are realistic since they do exist in the real world, and (ii) can be used to make existing models robust by 30-40%. Code is available at https://s-attack.github.io/.