 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Minor Edits Matter: LLM-Driven Prompt Attack for Medical VLM Robustness in Ultrasound
Mar 22, 2026Ultrasound is widely used in clinical practice due to its portability, cost-effectiveness, safety, and real-time imaging capabilities. However, image acquisition and interpretation remain highly operator dependent, motivating the development of robust AI-assisted analysis methods. Vision-language models (VLMs) have recently demonstrated strong multimodal reasoning capabilities and competitive performance in medical image analysis, including ultrasound. However, emerging evidence highlights significant concerns about their trustworthiness. In particular, adversarial robustness is critical because Med-VLMs operate via natural-language instructions, rendering prompt formulation a realistic and practically exploitable point of vulnerability. Small variations (typos, shorthand, underspecified requests, or ambiguous wording) can meaningfully shift model outputs. We propose a scalable adversarial evaluation framework that leverages a large language model (LLM) to generate clinically plausible adversarial prompt variants via "humanized" rewrites and minimal edits that mimic routine clinical communication. Using ultrasound multiple-choice question answering benchmarks, we systematically assess the vulnerability of SOTA Med-VLMs to these attacks, examine how attacker LLM capacity influences attack success, analyze the relationship between attack success and model confidence, and identify consistent failure patterns across models. Our results highlight realistic robustness gaps that must be addressed for safe clinical translation. Code will be released publicly following the review process.
Prompt2Perturb (P2P): Text-Guided Diffusion-Based Adversarial Attacks on Breast Ultrasound Images
Dec 13, 2024Deep neural networks (DNNs) offer significant promise for improving breast cancer diagnosis in medical imaging. However, these models are highly susceptible to adversarial attacks--small, imperceptible changes that can mislead classifiers--raising critical concerns about their reliability and security. Traditional attacks rely on fixed-norm perturbations, misaligning with human perception. In contrast, diffusion-based attacks require pre-trained models, demanding substantial data when these models are unavailable, limiting practical use in data-scarce scenarios. In medical imaging, however, this is often unfeasible due to the limited availability of datasets. Building on recent advancements in learnable prompts, we propose Prompt2Perturb (P2P), a novel language-guided attack method capable of generating meaningful attack examples driven by text instructions. During the prompt learning phase, our approach leverages learnable prompts within the text encoder to create subtle, yet impactful, perturbations that remain imperceptible while guiding the model towards targeted outcomes. In contrast to current prompt learning-based approaches, our P2P stands out by directly updating text embeddings, avoiding the need for retraining diffusion models. Further, we leverage the finding that optimizing only the early reverse diffusion steps boosts efficiency while ensuring that the generated adversarial examples incorporate subtle noise, thus preserving ultrasound image quality without introducing noticeable artifacts. We show that our method outperforms state-of-the-art attack techniques across three breast ultrasound datasets in FID and LPIPS. Moreover, the generated images are both more natural in appearance and more effective compared to existing adversarial attacks. Our code will be publicly available https://github.com/yasamin-med/P2P.
MEDDAP: Medical Dataset Enhancement via Diversified Augmentation Pipeline
Mar 26, 2024The effectiveness of Deep Neural Networks (DNNs) heavily relies on the abundance and accuracy of available training data. However, collecting and annotating data on a large scale is often both costly and time-intensive, particularly in medical cases where practitioners are already occupied with their duties. Moreover, ensuring that the model remains robust across various scenarios of image capture is crucial in medical domains, especially when dealing with ultrasound images that vary based on the settings of different devices and the manual operation of the transducer. To address this challenge, we introduce a novel pipeline called MEDDAP, which leverages Stable Diffusion (SD) models to augment existing small datasets by automatically generating new informative labeled samples. Pretrained checkpoints for SD are typically based on natural images, and training them for medical images requires significant GPU resources due to their heavy parameters. To overcome this challenge, we introduce USLoRA (Ultrasound Low-Rank Adaptation), a novel fine-tuning method tailored specifically for ultrasound applications. USLoRA allows for selective fine-tuning of weights within SD, requiring fewer than 0.1\% of parameters compared to fully fine-tuning only the UNet portion of SD. To enhance dataset diversity, we incorporate different adjectives into the generation process prompts, thereby desensitizing the classifiers to intensity changes across different images. This approach is inspired by clinicians' decision-making processes regarding breast tumors, where tumor shape often plays a more crucial role than intensity. In conclusion, our pipeline not only outperforms classifiers trained on the original dataset but also demonstrates superior performance when encountering unseen datasets. The source code is available at https://github.com/yasamin-med/MEDDAP.
Benchmarking Robustness to Text-Guided Corruptions
Apr 06, 2023



This study investigates the robustness of image classifiers to text-guided corruptions. We utilize diffusion models to edit images to different domains. Unlike other works that use synthetic or hand-picked data for benchmarking, we use diffusion models as they are generative models capable of learning to edit images while preserving their semantic content. Thus, the corruptions will be more realistic and the comparison will be more informative. Also, there is no need for manual labeling and we can create large-scale benchmarks with less effort. We define a prompt hierarchy based on the original ImageNet hierarchy to apply edits in different domains. As well as introducing a new benchmark we try to investigate the robustness of different vision models. The results of this study demonstrate that the performance of image classifiers decreases significantly in different language-based corruptions and edit domains. We also observe that convolutional models are more robust than transformer architectures. Additionally, we see that common data augmentation techniques can improve the performance on both the original data and the edited images. The findings of this research can help improve the design of image classifiers and contribute to the development of more robust machine learning systems. The code for generating the benchmark will be made available online upon publication.
A generic diffusion-based approach for 3D human pose prediction in the wild
Oct 11, 2022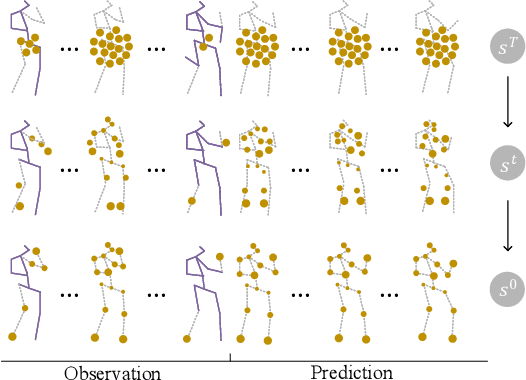
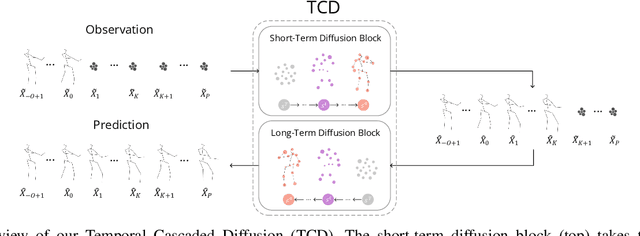

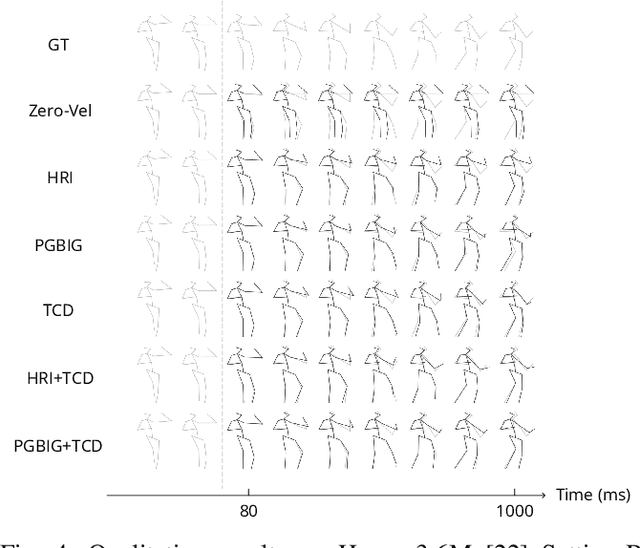
3D human pose forecasting, i.e., predicting a sequence of future human 3D poses given a sequence of past observed ones, is a challenging spatio-temporal task. It can be more challenging in real-world applications where occlusions will inevitably happen, and estimated 3D coordinates of joints would contain some noise. We provide a unified formulation in which incomplete elements (no matter in the prediction or observation) are treated as noise and propose a conditional diffusion model that denoises them and forecasts plausible poses. Instead of naively predicting all future frames at once, our model consists of two cascaded sub-models, each specialized for modeling short and long horizon distributions. We also propose a generic framework to improve any 3D pose forecasting model by leveraging our diffusion model in two additional steps: a pre-processing step to repair the inputs and a post-processing step to refine the outputs. We investigate our findings on four standard datasets (Human3.6M, HumanEva-I, AMASS, and 3DPW) and obtain significant improvements over the state-of-the-art. The code will be made available online.