 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoseDriver: A Unified Approach to Multi-Category Skeleton Detection for Autonomous Driving
Mar 25, 2026Object skeletons offer a concise representation of structural information, capturing essential aspects of posture and orientation that are crucial for autonomous driving applications. However, a unified architecture that simultaneously handles multiple instances and categories using only the input image remains elusive. In this paper, we introduce PoseDriver, a unified framework for bottom-up multi-category skeleton detection tailored to common objects in driving scenarios. We model each category as a distinct task to systematically address the challenges of multi-task learning. Specifically, we propose a novel approach for lane detection based on skeleton representations, achieving state-of-the-art performance on the OpenLane dataset. Moreover, we present a new dataset for bicycle skeleton detection and assess the transferability of our framework to novel categories. Experimental results validate the effectiveness of the proposed approach.
Toward Reliable Human Pose Forecasting with Uncertainty
Apr 13, 2023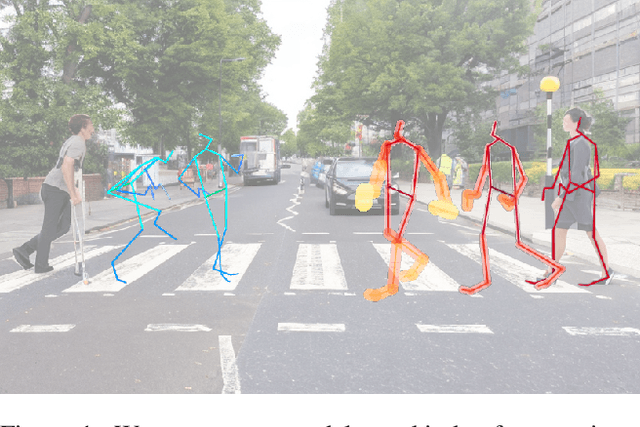
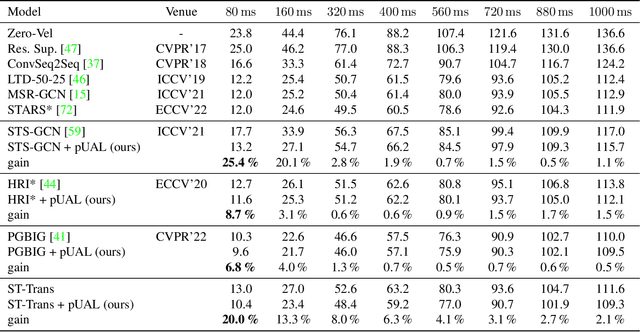
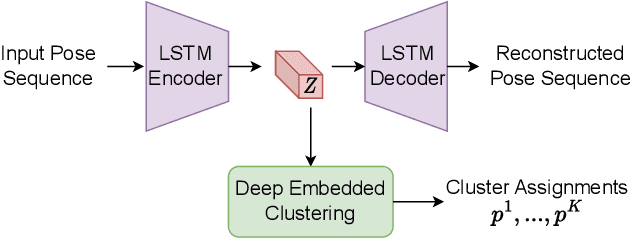
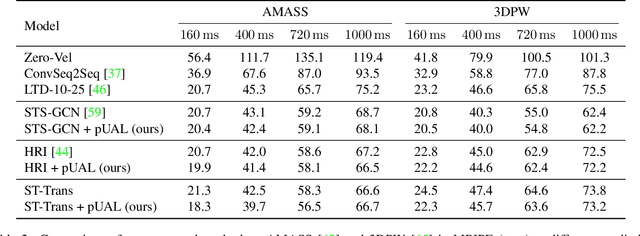
Recently, there has been an arms race of pose forecasting methods aimed at solving the spatio-temporal task of predicting a sequence of future 3D poses of a person given a sequence of past observed ones. However, the lack of unified benchmarks and limited uncertainty analysis have hindered progress in the field. To address this, we first develop an open-source library for human pose forecasting, featuring multiple models, datasets, and standardized evaluation metrics, with the aim of promoting research and moving toward a unified and fair evaluation. Second, we devise two types of uncertainty in the problem to increase performance and convey better trust: 1) we propose a method for modeling aleatoric uncertainty by using uncertainty priors to inject knowledge about the behavior of uncertainty. This focuses the capacity of the model in the direction of more meaningful supervision while reducing the number of learned parameters and improving stability; 2) we introduce a novel approach for quantifying the epistemic uncertainty of any model through clustering and measuring the entropy of its assignments. Our experiments demonstrate up to $25\%$ improvements in accuracy and better performance in uncertainty estimation.
A generic diffusion-based approach for 3D human pose prediction in the wild
Oct 11, 2022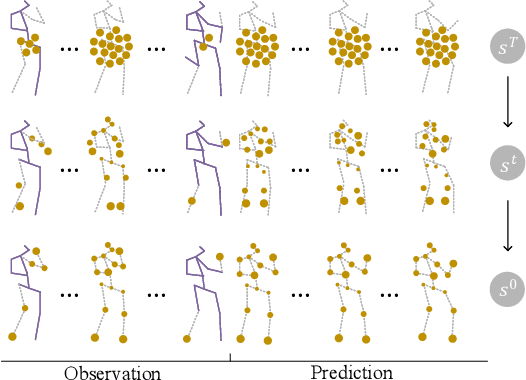
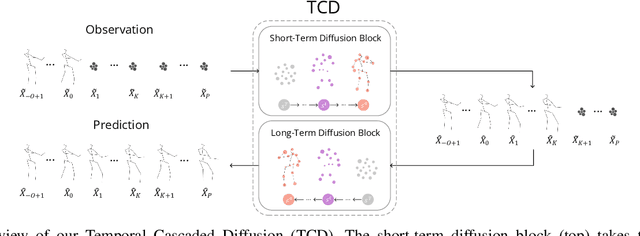

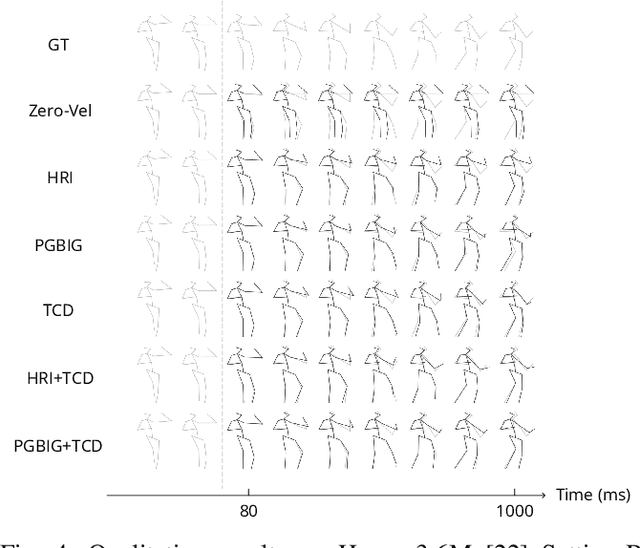
3D human pose forecasting, i.e., predicting a sequence of future human 3D poses given a sequence of past observed ones, is a challenging spatio-temporal task. It can be more challenging in real-world applications where occlusions will inevitably happen, and estimated 3D coordinates of joints would contain some noise. We provide a unified formulation in which incomplete elements (no matter in the prediction or observation) are treated as noise and propose a conditional diffusion model that denoises them and forecasts plausible poses. Instead of naively predicting all future frames at once, our model consists of two cascaded sub-models, each specialized for modeling short and long horizon distributions. We also propose a generic framework to improve any 3D pose forecasting model by leveraging our diffusion model in two additional steps: a pre-processing step to repair the inputs and a post-processing step to refine the outputs. We investigate our findings on four standard datasets (Human3.6M, HumanEva-I, AMASS, and 3DPW) and obtain significant improvements over the state-of-the-art. The code will be made available online.
Pedestrian Stop and Go Forecasting with Hybrid Feature Fusion
Mar 04, 2022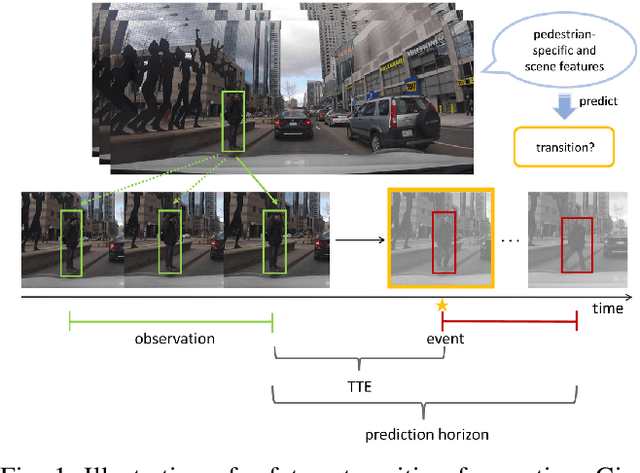
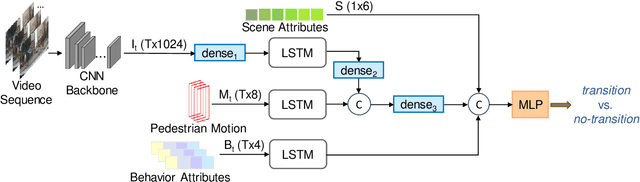
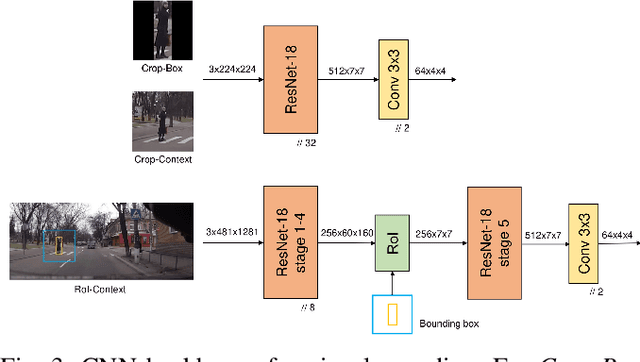
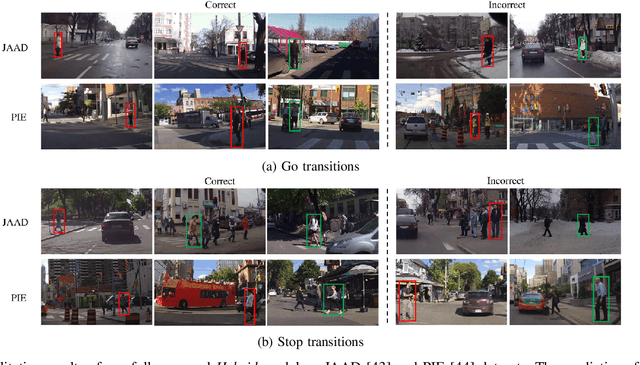
Forecasting pedestrians' future motions is essential for autonomous driving systems to safely navigate in urban areas. However, existing prediction algorithms often overly rely on past observed trajectories and tend to fail around abrupt dynamic changes, such as when pedestrians suddenly start or stop walking. We suggest that predicting these highly non-linear transitions should form a core component to improve the robustness of motion prediction algorithms. In this paper, we introduce the new task of pedestrian stop and go forecasting. Considering the lack of suitable existing datasets for it, we release TRANS, a benchmark for explicitly studying the stop and go behaviors of pedestrians in urban traffic. We build it from several existing datasets annotated with pedestrians' walking motions, in order to have various scenarios and behaviors. We also propose a novel hybrid model that leverages pedestrian-specific and scene features from several modalities, both video sequences and high-level attributes, and gradually fuses them to integrate multiple levels of context. We evaluate our model and several baselines on TRANS, and set a new benchmark for the community to work on pedestrian stop and go forecasting.
A Shared Representation for Photorealistic Driving Simulators
Dec 09, 2021
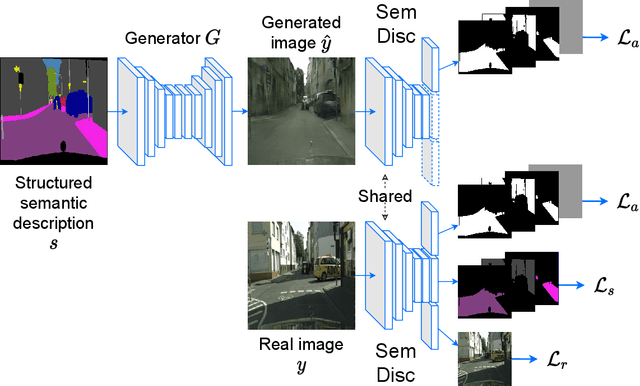


A powerful simulator highly decreases the need for real-world tests when training and evaluating autonomous vehicles. Data-driven simulators flourished with the recent advancement of conditional Generative Adversarial Networks (cGANs), providing high-fidelity images. The main challenge is synthesizing photorealistic images while following given constraints. In this work, we propose to improve the quality of generated images by rethinking the discriminator architecture. The focus is on the class of problems where images are generated given semantic inputs, such as scene segmentation maps or human body poses. We build on successful cGAN models to propose a new semantically-aware discriminator that better guides the generator. We aim to learn a shared latent representation that encodes enough information to jointly do semantic segmentation, content reconstruction, along with a coarse-to-fine grained adversarial reasoning. The achieved improvements are generic and simple enough to be applied to any architecture of conditional image synthesis. We demonstrate the strength of our method on the scene, building, and human synthesis tasks across three different datasets. The code is available at https://github.com/vita-epfl/SemDisc.
Do Pedestrians Pay Attention? Eye Contact Detection in the Wild
Dec 08, 2021
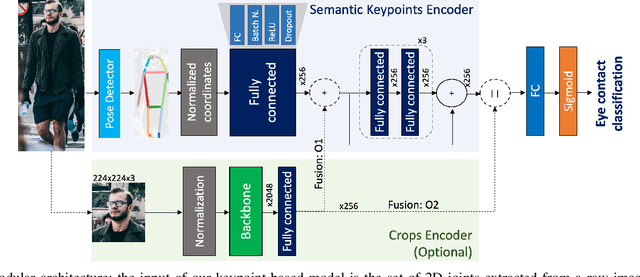
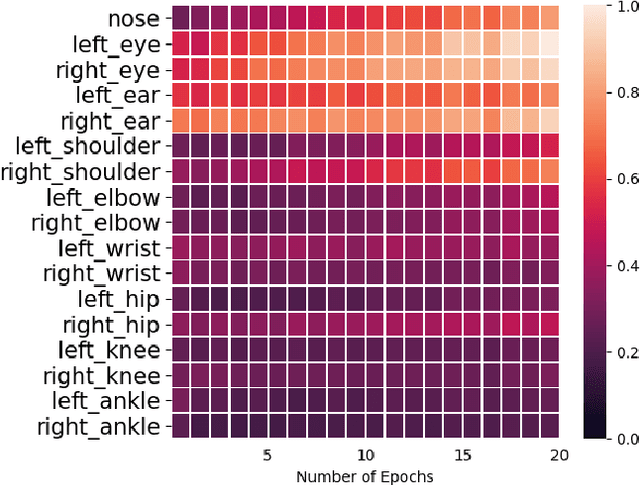

In urban or crowded environments, humans rely on eye contact for fast and efficient communication with nearby people. Autonomous agents also need to detect eye contact to interact with pedestrians and safely navigate around them. In this paper, we focus on eye contact detection in the wild, i.e., real-world scenarios for autonomous vehicles with no control over the environment or the distance of pedestrians. We introduce a model that leverages semantic keypoints to detect eye contact and show that this high-level representation (i) achieves state-of-the-art results on the publicly-available dataset JAAD, and (ii) conveys better generalization properties than leveraging raw images in an end-to-end network. To study domain adaptation, we create LOOK: a large-scale dataset for eye contact detection in the wild, which focuses on diverse and unconstrained scenarios for real-world generalization. The source code and the LOOK dataset are publicly shared towards an open science mission.
Detecting 32 Pedestrian Attributes for Autonomous Vehicles
Dec 04, 2020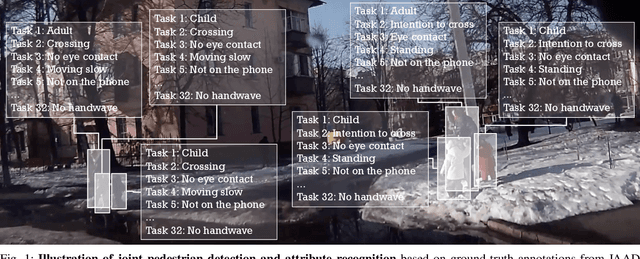
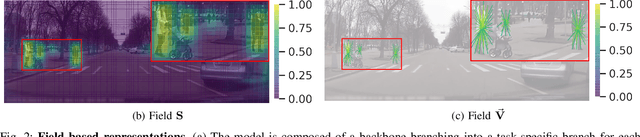
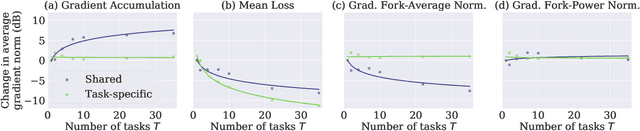

Pedestrians are arguably one of the most safety-critical road users to consider for autonomous vehicles in urban areas. In this paper, we address the problem of jointly detecting pedestrians and recognizing 32 pedestrian attributes. These encompass visual appearance and behavior, and also include the forecasting of road crossing, which is a main safety concern. For this, we introduce a Multi-Task Learning (MTL) model relying on a composite field framework, which achieves both goals in an efficient way. Each field spatially locates pedestrian instances and aggregates attribute predictions over them. This formulation naturally leverages spatial context, making it well suited to low resolution scenarios such as autonomous driving. By increasing the number of attributes jointly learned, we highlight an issue related to the scales of gradients, which arises in MTL with numerous tasks. We solve it by normalizing the gradients coming from different objective functions when they join at the fork in the network architecture during the backward pass, referred to as fork-normalization. Experimental validation is performed on JAAD, a dataset providing numerous attributes for pedestrian analysis from autonomous vehicles, and shows competitive detection and attribute recognition results, as well as a more stable MTL training.
MonStereo: When Monocular and Stereo Meet at the Tail of 3D Human Localization
Aug 25, 2020

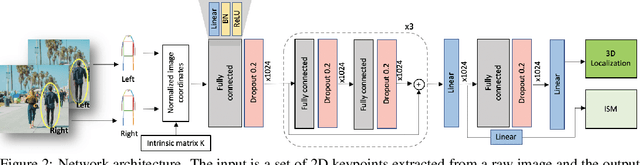

Monocular and stereo vision are cost-effective solutions for 3D human localization in the context of self-driving cars or social robots. However, they are usually developed independently and have their respective strengths and limitations. We propose a novel unified learning framework that leverages the strengths of both monocular and stereo cues for 3D human localization. Our method jointly (i) associates humans in left-right images, (ii) deals with occluded and distant cases in stereo settings by relying on the robustness of monocular cues, and (iii) tackles the intrinsic ambiguity of monocular perspective projection by exploiting prior knowledge of human height distribution. We achieve state-of-the-art quantitative results for the 3D localization task on KITTI dataset and estimate confidence intervals that account for challenging instances. We show qualitative examples for the long tail challenges such as occluded, far-away, and children instances.
Deformable Part-based Fully Convolutional Network for Object Detection
Jul 19, 2017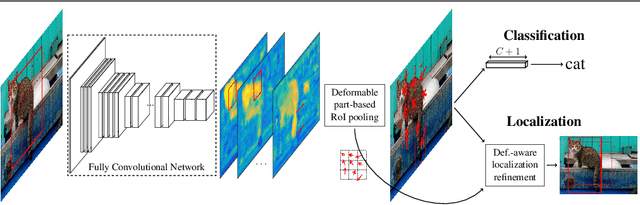
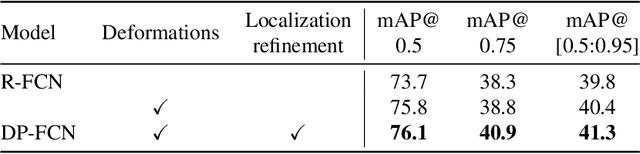
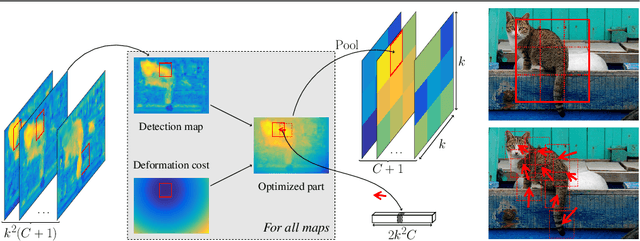
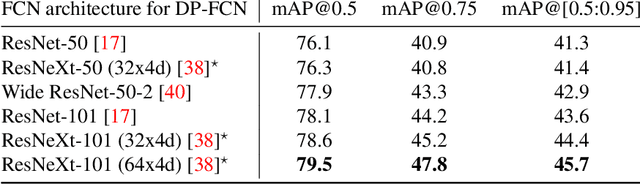
Existing region-based object detectors are limited to regions with fixed box geometry to represent objects, even if those are highly non-rectangular. In this paper we introduce DP-FCN, a deep model for object detection which explicitly adapts to shapes of objects with deformable parts. Without additional annotations, it learns to focus on discriminative elements and to align them, and simultaneously brings more invariance for classification and geometric information to refine localization. DP-FCN is composed of three main modules: a Fully Convolutional Network to efficiently maintain spatial resolution, a deformable part-based RoI pooling layer to optimize positions of parts and build invariance, and a deformation-aware localization module explicitly exploiting displacements of parts to improve accuracy of bounding box regression. We experimentally validate our model and show significant gains. DP-FCN achieves state-of-the-art performances of 83.1% and 80.9% on PASCAL VOC 2007 and 2012 with VOC data only.