 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Temporal Understanding in Video-LLMs through Stacked Temporal Attention in Vision Encoders
Oct 29, 2025Despite significant advances in Multimodal Large Language Models (MLLMs), understanding complex temporal dynamics in videos remains a major challenge. Our experiments show that current Video Large Language Model (Video-LLM) architectures have critical limitations in temporal understanding, struggling with tasks that require detailed comprehension of action sequences and temporal progression. In this work, we propose a Video-LLM architecture that introduces stacked temporal attention modules directly within the vision encoder. This design incorporates a temporal attention in vision encoder, enabling the model to better capture the progression of actions and the relationships between frames before passing visual tokens to the LLM. Our results show that this approach significantly improves temporal reasoning and outperforms existing models in video question answering tasks, specifically in action recognition. We improve on benchmarks including VITATECS, MVBench, and Video-MME by up to +5.5%. By enhancing the vision encoder with temporal structure, we address a critical gap in video understanding for Video-LLMs. Project page and code are available at: https://alirasekh.github.io/STAVEQ2/.
Multi-Rationale Explainable Object Recognition via Contrastive Conditional Inference
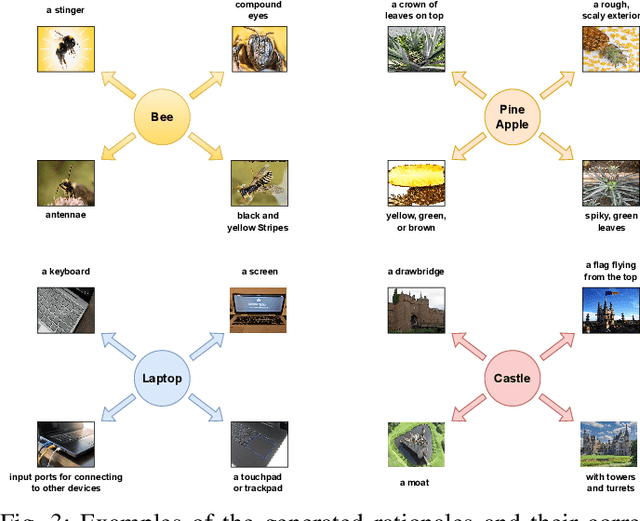
Aug 19, 2025Explainable object recognition using vision-language models such as CLIP involves predicting accurate category labels supported by rationales that justify the decision-making process. Existing methods typically rely on prompt-based conditioning, which suffers from limitations in CLIP's text encoder and provides weak conditioning on explanatory structures. Additionally, prior datasets are often restricted to single, and frequently noisy, rationales that fail to capture the full diversity of discriminative image features. In this work, we introduce a multi-rationale explainable object recognition benchmark comprising datasets in which each image is annotated with multiple ground-truth rationales, along with evaluation metrics designed to offer a more comprehensive representation of the task. To overcome the limitations of previous approaches, we propose a contrastive conditional inference (CCI) framework that explicitly models the probabilistic relationships among image embeddings, category labels, and rationales. Without requiring any training, our framework enables more effective conditioning on rationales to predict accurate object categories. Our approach achieves state-of-the-art results on the multi-rationale explainable object recognition benchmark, including strong zero-shot performance, and sets a new standard for both classification accuracy and rationale quality. Together with the benchmark, this work provides a more complete framework for evaluating future models in explainable object recognition. The code will be made available online.
Aligning Visual Contrastive learning models via Preference Optimization
Nov 12, 2024Contrastive learning models have demonstrated impressive abilities to capture semantic similarities by aligning representations in the embedding space. However, their performance can be limited by the quality of the training data and its inherent biases. While Reinforcement Learning from Human Feedback (RLHF) and Direct Preference Optimization (DPO) have been applied to generative models to align them with human preferences, their use in contrastive learning has yet to be explored. This paper introduces a novel method for training contrastive learning models using Preference Optimization (PO) to break down complex concepts. Our method systematically aligns model behavior with desired preferences, enhancing performance on the targeted task. In particular, we focus on enhancing model robustness against typographic attacks, commonly seen in contrastive models like CLIP. We further apply our method to disentangle gender understanding and mitigate gender biases, offering a more nuanced control over these sensitive attributes. Our experiments demonstrate that models trained using PO outperform standard contrastive learning techniques while retaining their ability to handle adversarial challenges and maintain accuracy on other downstream tasks. This makes our method well-suited for tasks requiring fairness, robustness, and alignment with specific preferences. We evaluate our method on several vision-language tasks, tackling challenges such as typographic attacks. Additionally, we explore the model's ability to disentangle gender concepts and mitigate gender bias, showcasing the versatility of our approach.
Towards Precision Healthcare: Robust Fusion of Time Series and Image Data
May 24, 2024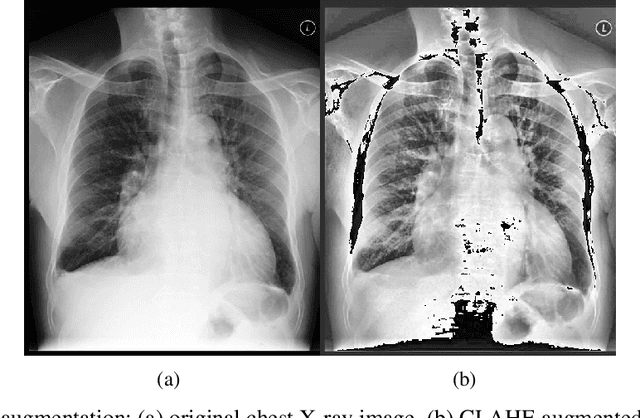
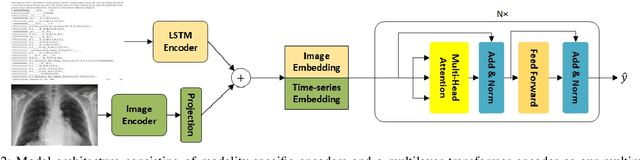
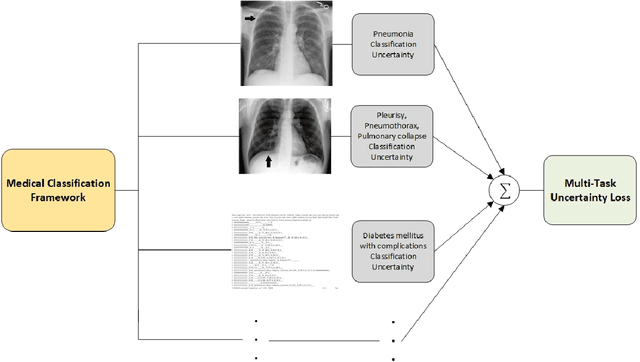
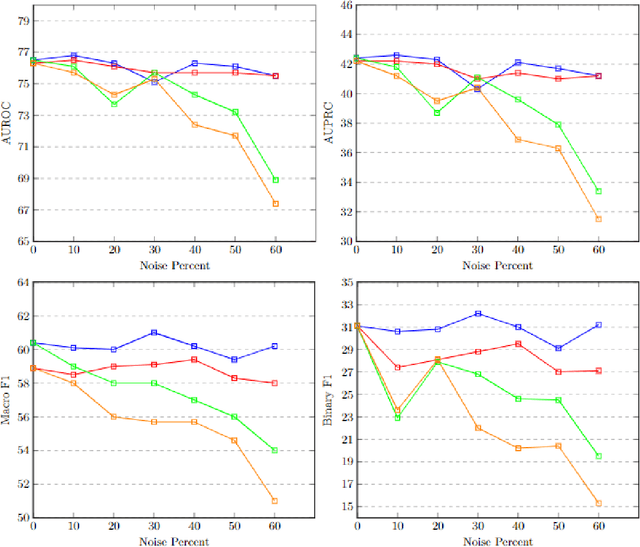
With the increasing availability of diverse data types, particularly images and time series data from medical experiments, there is a growing demand for techniques designed to combine various modalities of data effectively. Our motivation comes from the important areas of predicting mortality and phenotyping where using different modalities of data could significantly improve our ability to predict. To tackle this challenge, we introduce a new method that uses two separate encoders, one for each type of data, allowing the model to understand complex patterns in both visual and time-based information. Apart from the technical challenges, our goal is to make the predictive model more robust in noisy conditions and perform better than current methods. We also deal with imbalanced datasets and use an uncertainty loss function, yielding improved results while simultaneously providing a principled means of modeling uncertainty. Additionally, we include attention mechanisms to fuse different modalities, allowing the model to focus on what's important for each task. We tested our approach using the comprehensive multimodal MIMIC dataset, combining MIMIC-IV and MIMIC-CXR datasets. Our experiments show that our method is effective in improving multimodal deep learning for clinical applications. The code will be made available online.
ECOR: Explainable CLIP for Object Recognition
Apr 19, 2024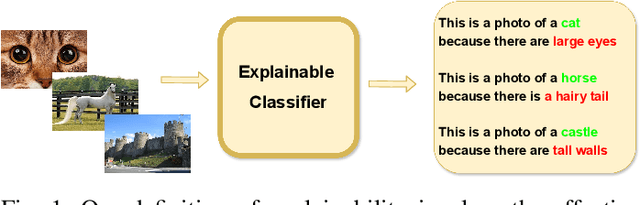
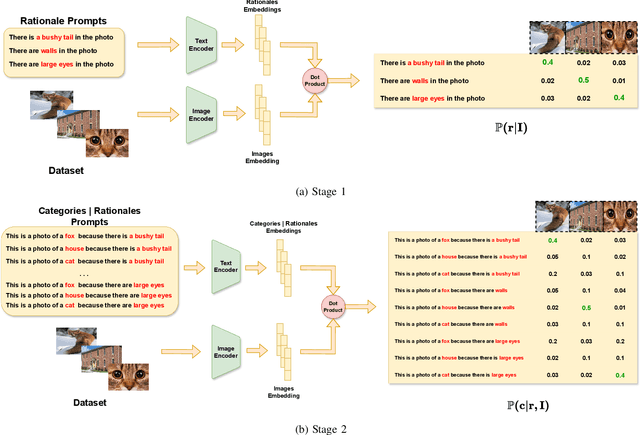

Large Vision Language Models (VLMs), such as CLIP, have significantly contributed to various computer vision tasks, including object recognition and object detection. Their open vocabulary feature enhances their value. However, their black-box nature and lack of explainability in predictions make them less trustworthy in critical domains. Recently, some work has been done to force VLMs to provide reasonable rationales for object recognition, but this often comes at the expense of classification accuracy. In this paper, we first propose a mathematical definition of explainability in the object recognition task based on the joint probability distribution of categories and rationales, then leverage this definition to fine-tune CLIP in an explainable manner. Through evaluations of different datasets, our method demonstrates state-of-the-art performance in explainable classification. Notably, it excels in zero-shot settings, showcasing its adaptability. This advancement improves explainable object recognition, enhancing trust across diverse applications. The code will be made available online upon publication.
A generic diffusion-based approach for 3D human pose prediction in the wild
Oct 11, 2022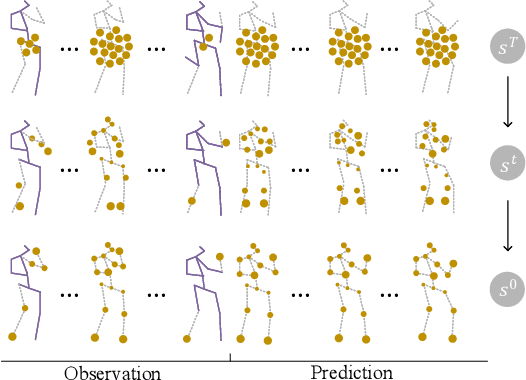
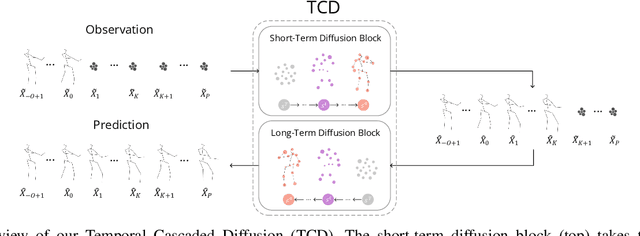

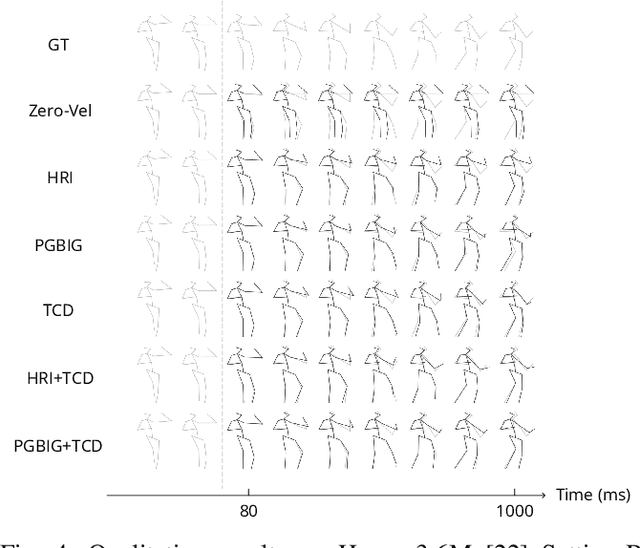
3D human pose forecasting, i.e., predicting a sequence of future human 3D poses given a sequence of past observed ones, is a challenging spatio-temporal task. It can be more challenging in real-world applications where occlusions will inevitably happen, and estimated 3D coordinates of joints would contain some noise. We provide a unified formulation in which incomplete elements (no matter in the prediction or observation) are treated as noise and propose a conditional diffusion model that denoises them and forecasts plausible poses. Instead of naively predicting all future frames at once, our model consists of two cascaded sub-models, each specialized for modeling short and long horizon distributions. We also propose a generic framework to improve any 3D pose forecasting model by leveraging our diffusion model in two additional steps: a pre-processing step to repair the inputs and a post-processing step to refine the outputs. We investigate our findings on four standard datasets (Human3.6M, HumanEva-I, AMASS, and 3DPW) and obtain significant improvements over the state-of-the-art. The code will be made available online.