 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSqueeze3D: Your 3D Generation Model is Secretly an Extreme Neural Compressor
Jun 09, 2025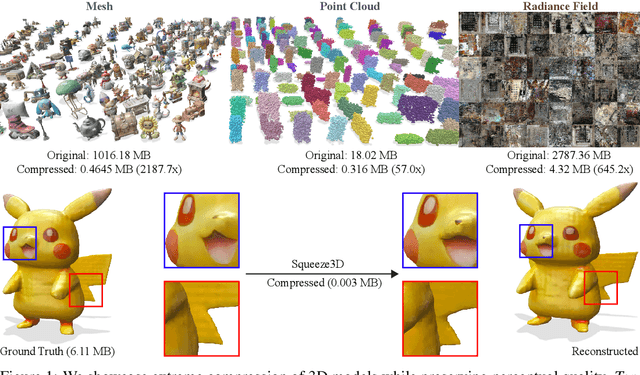


We propose Squeeze3D, a novel framework that leverages implicit prior knowledge learnt by existing pre-trained 3D generative models to compress 3D data at extremely high compression ratios. Our approach bridges the latent spaces between a pre-trained encoder and a pre-trained generation model through trainable mapping networks. Any 3D model represented as a mesh, point cloud, or a radiance field is first encoded by the pre-trained encoder and then transformed (i.e. compressed) into a highly compact latent code. This latent code can effectively be used as an extremely compressed representation of the mesh or point cloud. A mapping network transforms the compressed latent code into the latent space of a powerful generative model, which is then conditioned to recreate the original 3D model (i.e. decompression). Squeeze3D is trained entirely on generated synthetic data and does not require any 3D datasets. The Squeeze3D architecture can be flexibly used with existing pre-trained 3D encoders and existing generative models. It can flexibly support different formats, including meshes, point clouds, and radiance fields. Our experiments demonstrate that Squeeze3D achieves compression ratios of up to 2187x for textured meshes, 55x for point clouds, and 619x for radiance fields while maintaining visual quality comparable to many existing methods. Squeeze3D only incurs a small compression and decompression latency since it does not involve training object-specific networks to compress an object.
Humanity's Last Exam
Jan 24, 2025Benchmarks are important tools for tracking the rapid advancements in large language model (LLM) capabilities. However, benchmarks are not keeping pace in difficulty: LLMs now achieve over 90\% accuracy on popular benchmarks like MMLU, limiting informed measurement of state-of-the-art LLM capabilities. In response, we introduce Humanity's Last Exam (HLE), a multi-modal benchmark at the frontier of human knowledge, designed to be the final closed-ended academic benchmark of its kind with broad subject coverage. HLE consists of 3,000 questions across dozens of subjects, including mathematics, humanities, and the natural sciences. HLE is developed globally by subject-matter experts and consists of multiple-choice and short-answer questions suitable for automated grading. Each question has a known solution that is unambiguous and easily verifiable, but cannot be quickly answered via internet retrieval. State-of-the-art LLMs demonstrate low accuracy and calibration on HLE, highlighting a significant gap between current LLM capabilities and the expert human frontier on closed-ended academic questions. To inform research and policymaking upon a clear understanding of model capabilities, we publicly release HLE at https://lastexam.ai.
M$^3$Face: A Unified Multi-Modal Multilingual Framework for Human Face Generation and Editing
Feb 04, 2024Human face generation and editing represent an essential task in the era of computer vision and the digital world. Recent studies have shown remarkable progress in multi-modal face generation and editing, for instance, using face segmentation to guide image generation. However, it may be challenging for some users to create these conditioning modalities manually. Thus, we introduce M3Face, a unified multi-modal multilingual framework for controllable face generation and editing. This framework enables users to utilize only text input to generate controlling modalities automatically, for instance, semantic segmentation or facial landmarks, and subsequently generate face images. We conduct extensive qualitative and quantitative experiments to showcase our frameworks face generation and editing capabilities. Additionally, we propose the M3CelebA Dataset, a large-scale multi-modal and multilingual face dataset containing high-quality images, semantic segmentations, facial landmarks, and different captions for each image in multiple languages. The code and the dataset will be released upon publication.
Benchmarking Robustness to Text-Guided Corruptions
Apr 06, 2023



This study investigates the robustness of image classifiers to text-guided corruptions. We utilize diffusion models to edit images to different domains. Unlike other works that use synthetic or hand-picked data for benchmarking, we use diffusion models as they are generative models capable of learning to edit images while preserving their semantic content. Thus, the corruptions will be more realistic and the comparison will be more informative. Also, there is no need for manual labeling and we can create large-scale benchmarks with less effort. We define a prompt hierarchy based on the original ImageNet hierarchy to apply edits in different domains. As well as introducing a new benchmark we try to investigate the robustness of different vision models. The results of this study demonstrate that the performance of image classifiers decreases significantly in different language-based corruptions and edit domains. We also observe that convolutional models are more robust than transformer architectures. Additionally, we see that common data augmentation techniques can improve the performance on both the original data and the edited images. The findings of this research can help improve the design of image classifiers and contribute to the development of more robust machine learning systems. The code for generating the benchmark will be made available online upon publication.
A generic diffusion-based approach for 3D human pose prediction in the wild
Oct 11, 2022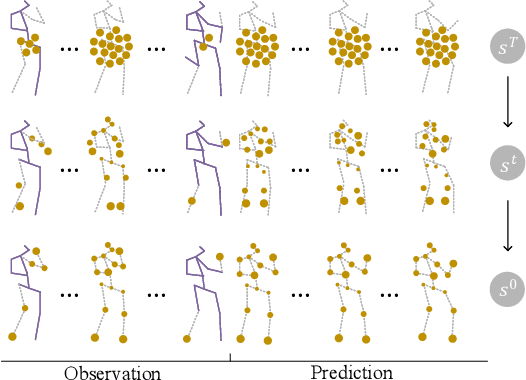
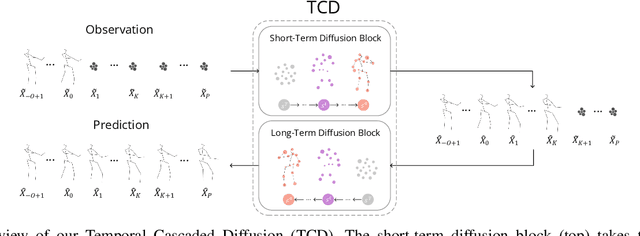

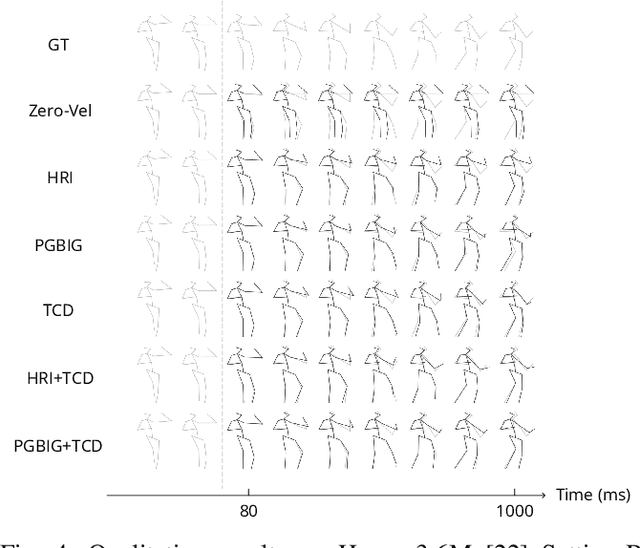
3D human pose forecasting, i.e., predicting a sequence of future human 3D poses given a sequence of past observed ones, is a challenging spatio-temporal task. It can be more challenging in real-world applications where occlusions will inevitably happen, and estimated 3D coordinates of joints would contain some noise. We provide a unified formulation in which incomplete elements (no matter in the prediction or observation) are treated as noise and propose a conditional diffusion model that denoises them and forecasts plausible poses. Instead of naively predicting all future frames at once, our model consists of two cascaded sub-models, each specialized for modeling short and long horizon distributions. We also propose a generic framework to improve any 3D pose forecasting model by leveraging our diffusion model in two additional steps: a pre-processing step to repair the inputs and a post-processing step to refine the outputs. We investigate our findings on four standard datasets (Human3.6M, HumanEva-I, AMASS, and 3DPW) and obtain significant improvements over the state-of-the-art. The code will be made available online.