 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTuneShift-KD: Knowledge Distillation and Transfer for Fine-tuned Models
Mar 25, 2026To embed domain-specific or specialized knowledge into pre-trained foundation models, fine-tuning using techniques such as parameter efficient fine-tuning (e.g. LoRA) is a common practice. However, as new LLM architectures and pre-trained models emerge, transferring this specialized knowledge to newer models becomes an important task. In many scenarios, the original specialized data may be unavailable due to privacy or commercial restrictions, necessitating distillation and transfer of this specialized knowledge from the fine-tuned base model to a different pre-trained model. We present TuneShift-KD, a novel approach that automatically distills specialized knowledge from a fine-tuned model to a target model using only a few examples representative of the specialized information. Our key insight is that specialized knowledge can be identified through perplexity differences between base and fine-tuned models: prompts where the fine-tuned model responds confidently (low perplexity), but the base model struggles (high perplexity), indicate queries corresponding to the specialized knowledge learned by the fine-tuned model. TuneShift-KD leverages this insight to create a synthetic training dataset to transfer the specialized knowledge. Using an iterative process, TuneShift-KD generates more prompts similar to those that generated responses with specialized knowledge. TuneShift-KD does not require training discriminators or access to training datasets. It is an automated approach that only requires the initial fine-tuned and base models and a few representative prompts. Our experiments demonstrate that models fine-tuned using TuneShift-KD achieve higher accuracy than prior approaches, enabling ease of deployment and more effective transfer of the specialized knowledge.
MERG3R: A Divide-and-Conquer Approach to Large-Scale Neural Visual Geometry
Mar 02, 2026Recent advancements in neural visual geometry, including transformer-based models such as VGGT and Pi3, have achieved impressive accuracy on 3D reconstruction tasks. However, their reliance on full attention makes them fundamentally limited by GPU memory capacity, preventing them from scaling to large, unordered image collections. We introduce MERG3R, a training-free divide-and-conquer framework that enables geometric foundation models to operate far beyond their native memory limits. MERG3R first reorders and partitions unordered images into overlapping, geometrically diverse subsets that can be reconstructed independently. It then merges the resulting local reconstructions through an efficient global alignment and confidence-weighted bundle adjustment procedure, producing a globally consistent 3D model. Our framework is model-agnostic and can be paired with existing neural geometry models. Across large-scale datasets, including 7-Scenes, NRGBD, Tanks & Temples, and Cambridge Landmarks, MERG3R consistently improves reconstruction accuracy, memory efficiency, and scalability, enabling high-quality reconstruction when the dataset exceeds memory capacity limits.
ContraGS: Codebook-Condensed and Trainable Gaussian Splatting for Fast, Memory-Efficient Reconstruction
Sep 03, 20253D Gaussian Splatting (3DGS) is a state-of-art technique to model real-world scenes with high quality and real-time rendering. Typically, a higher quality representation can be achieved by using a large number of 3D Gaussians. However, using large 3D Gaussian counts significantly increases the GPU device memory for storing model parameters. A large model thus requires powerful GPUs with high memory capacities for training and has slower training/rendering latencies due to the inefficiencies of memory access and data movement. In this work, we introduce ContraGS, a method to enable training directly on compressed 3DGS representations without reducing the Gaussian Counts, and thus with a little loss in model quality. ContraGS leverages codebooks to compactly store a set of Gaussian parameter vectors throughout the training process, thereby significantly reducing memory consumption. While codebooks have been demonstrated to be highly effective at compressing fully trained 3DGS models, directly training using codebook representations is an unsolved challenge. ContraGS solves the problem of learning non-differentiable parameters in codebook-compressed representations by posing parameter estimation as a Bayesian inference problem. To this end, ContraGS provides a framework that effectively uses MCMC sampling to sample over a posterior distribution of these compressed representations. With ContraGS, we demonstrate that ContraGS significantly reduces the peak memory during training (on average 3.49X) and accelerated training and rendering (1.36X and 1.88X on average, respectively), while retraining close to state-of-art quality.
Squeeze3D: Your 3D Generation Model is Secretly an Extreme Neural Compressor
Jun 09, 2025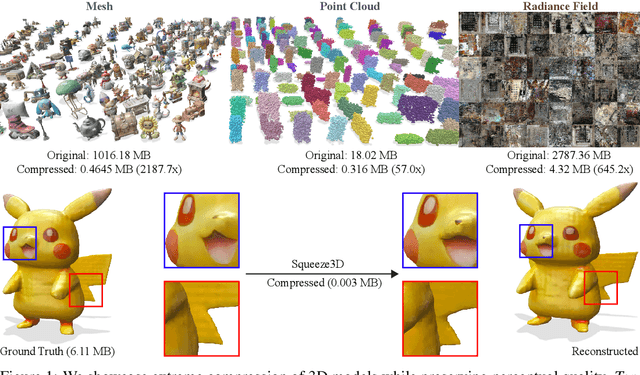


We propose Squeeze3D, a novel framework that leverages implicit prior knowledge learnt by existing pre-trained 3D generative models to compress 3D data at extremely high compression ratios. Our approach bridges the latent spaces between a pre-trained encoder and a pre-trained generation model through trainable mapping networks. Any 3D model represented as a mesh, point cloud, or a radiance field is first encoded by the pre-trained encoder and then transformed (i.e. compressed) into a highly compact latent code. This latent code can effectively be used as an extremely compressed representation of the mesh or point cloud. A mapping network transforms the compressed latent code into the latent space of a powerful generative model, which is then conditioned to recreate the original 3D model (i.e. decompression). Squeeze3D is trained entirely on generated synthetic data and does not require any 3D datasets. The Squeeze3D architecture can be flexibly used with existing pre-trained 3D encoders and existing generative models. It can flexibly support different formats, including meshes, point clouds, and radiance fields. Our experiments demonstrate that Squeeze3D achieves compression ratios of up to 2187x for textured meshes, 55x for point clouds, and 619x for radiance fields while maintaining visual quality comparable to many existing methods. Squeeze3D only incurs a small compression and decompression latency since it does not involve training object-specific networks to compress an object.
INRet: A General Framework for Accurate Retrieval of INRs for Shapes
Jan 27, 2025



Implicit neural representations (INRs) have become an important method for encoding various data types, such as 3D objects or scenes, images, and videos. They have proven to be particularly effective at representing 3D content, e.g., 3D scene reconstruction from 2D images, novel 3D content creation, as well as the representation, interpolation, and completion of 3D shapes. With the widespread generation of 3D data in an INR format, there is a need to support effective organization and retrieval of INRs saved in a data store. A key aspect of retrieval and clustering of INRs in a data store is the formulation of similarity between INRs that would, for example, enable retrieval of similar INRs using a query INR. In this work, we propose INRet, a method for determining similarity between INRs that represent shapes, thus enabling accurate retrieval of similar shape INRs from an INR data store. INRet flexibly supports different INR architectures such as INRs with octree grids, triplanes, and hash grids, as well as different implicit functions including signed/unsigned distance function and occupancy field. We demonstrate that our method is more general and accurate than the existing INR retrieval method, which only supports simple MLP INRs and requires the same architecture between the query and stored INRs. Furthermore, compared to converting INRs to other representations (e.g., point clouds or multi-view images) for 3D shape retrieval, INRet achieves higher accuracy while avoiding the conversion overhead.
EvConv: Fast CNN Inference on Event Camera Inputs For High-Speed Robot Perception
Mar 08, 2023



Event cameras capture visual information with a high temporal resolution and a wide dynamic range. This enables capturing visual information at fine time granularities (e.g., microseconds) in rapidly changing environments. This makes event cameras highly useful for high-speed robotics tasks involving rapid motion, such as high-speed perception, object tracking, and control. However, convolutional neural network inference on event camera streams cannot currently perform real-time inference at the high speeds at which event cameras operate - current CNN inference times are typically closer in order of magnitude to the frame rates of regular frame-based cameras. Real-time inference at event camera rates is necessary to fully leverage the high frequency and high temporal resolution that event cameras offer. This paper presents EvConv, a new approach to enable fast inference on CNNs for inputs from event cameras. We observe that consecutive inputs to the CNN from an event camera have only small differences between them. Thus, we propose to perform inference on the difference between consecutive input tensors, or the increment. This enables a significant reduction in the number of floating-point operations required (and thus the inference latency) because increments are very sparse. We design EvConv to leverage the irregular sparsity in increments from event cameras and to retain the sparsity of these increments across all layers of the network. We demonstrate a reduction in the number of floating operations required in the forward pass by up to 98%. We also demonstrate a speedup of up to 1.6X for inference using CNNs for tasks such as depth estimation, object recognition, and optical flow estimation, with almost no loss in accuracy.
End to End ASR System with Automatic Punctuation Insertion
Dec 03, 2020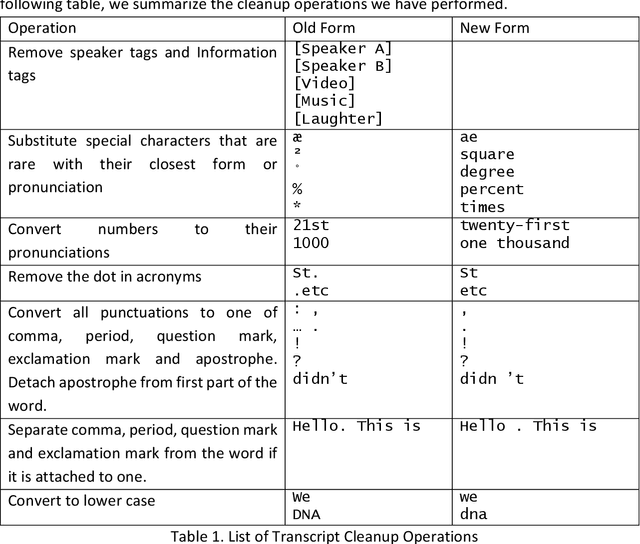


Recent Automatic Speech Recognition systems have been moving towards end-to-end systems that can be trained together. Numerous techniques that have been proposed recently enabled this trend, including feature extraction with CNNs, context capturing and acoustic feature modeling with RNNs, automatic alignment of input and output sequences using Connectionist Temporal Classifications, as well as replacing traditional n-gram language models with RNN Language Models. Historically, there has been a lot of interest in automatic punctuation in textual or speech to text context. However, there seems to be little interest in incorporating automatic punctuation into the emerging neural network based end-to-end speech recognition systems, partially due to the lack of English speech corpus with punctuated transcripts. In this study, we propose a method to generate punctuated transcript for the TEDLIUM dataset using transcripts available from ted.com. We also propose an end-to-end ASR system that outputs words and punctuations concurrently from speech signals. Combining Damerau Levenshtein Distance and slot error rate into DLev-SER, we enable measurement of punctuation error rate when the hypothesis text is not perfectly aligned with the reference. Compared with previous methods, our model reduces slot error rate from 0.497 to 0.341.