 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoMP: Predicting Volumetric Mechanical Property Fields
Oct 27, 2025Physical simulation relies on spatially-varying mechanical properties, often laboriously hand-crafted. VoMP is a feed-forward method trained to predict Young's modulus ($E$), Poisson's ratio ($\nu$), and density ($\rho$) throughout the volume of 3D objects, in any representation that can be rendered and voxelized. VoMP aggregates per-voxel multi-view features and passes them to our trained Geometry Transformer to predict per-voxel material latent codes. These latents reside on a manifold of physically plausible materials, which we learn from a real-world dataset, guaranteeing the validity of decoded per-voxel materials. To obtain object-level training data, we propose an annotation pipeline combining knowledge from segmented 3D datasets, material databases, and a vision-language model, along with a new benchmark. Experiments show that VoMP estimates accurate volumetric properties, far outperforming prior art in accuracy and speed.
Squeeze3D: Your 3D Generation Model is Secretly an Extreme Neural Compressor
Jun 09, 2025We propose Squeeze3D, a novel framework that leverages implicit prior knowledge learnt by existing pre-trained 3D generative models to compress 3D data at extremely high compression ratios. Our approach bridges the latent spaces between a pre-trained encoder and a pre-trained generation model through trainable mapping networks. Any 3D model represented as a mesh, point cloud, or a radiance field is first encoded by the pre-trained encoder and then transformed (i.e. compressed) into a highly compact latent code. This latent code can effectively be used as an extremely compressed representation of the mesh or point cloud. A mapping network transforms the compressed latent code into the latent space of a powerful generative model, which is then conditioned to recreate the original 3D model (i.e. decompression). Squeeze3D is trained entirely on generated synthetic data and does not require any 3D datasets. The Squeeze3D architecture can be flexibly used with existing pre-trained 3D encoders and existing generative models. It can flexibly support different formats, including meshes, point clouds, and radiance fields. Our experiments demonstrate that Squeeze3D achieves compression ratios of up to 2187x for textured meshes, 55x for point clouds, and 619x for radiance fields while maintaining visual quality comparable to many existing methods. Squeeze3D only incurs a small compression and decompression latency since it does not involve training object-specific networks to compress an object.
Can Vision-Language Models Answer Face to Face Questions in the Real-World?
Mar 25, 2025AI models have made significant strides in recent years in their ability to describe and answer questions about real-world images. They have also made progress in the ability to converse with users in real-time using audio input. This raises the question: have we reached the point where AI models, connected to a camera and microphone, can converse with users in real-time about scenes and events that are unfolding live in front of the camera? This has been a long-standing goal in AI and is a prerequisite for real-world AI assistants and humanoid robots to interact with humans in everyday situations. In this work, we introduce a new dataset and benchmark, the Qualcomm Interactive Video Dataset (IVD), which allows us to assess the extent to which existing models can support these abilities, and to what degree these capabilities can be instilled through fine-tuning. The dataset is based on a simple question-answering setup, where users ask questions that the system has to answer, in real-time, based on the camera and audio input. We show that existing models fall far behind human performance on this task, and we identify the main sources for the performance gap. However, we also show that for many of the required perceptual skills, fine-tuning on this form of data can significantly reduce this gap.
AirLetters: An Open Video Dataset of Characters Drawn in the Air
Oct 03, 2024
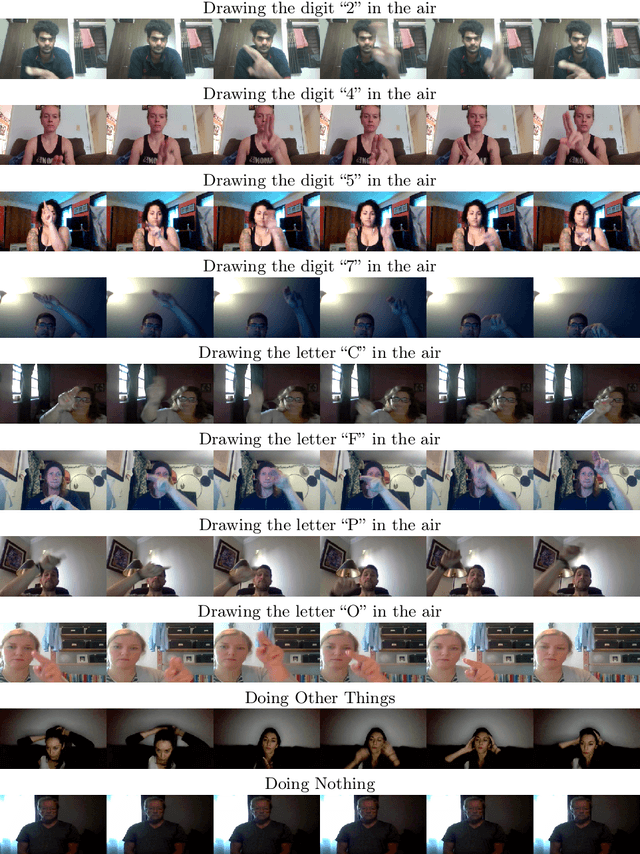


We introduce AirLetters, a new video dataset consisting of real-world videos of human-generated, articulated motions. Specifically, our dataset requires a vision model to predict letters that humans draw in the air. Unlike existing video datasets, accurate classification predictions for AirLetters rely critically on discerning motion patterns and on integrating long-range information in the video over time. An extensive evaluation of state-of-the-art image and video understanding models on AirLetters shows that these methods perform poorly and fall far behind a human baseline. Our work shows that, despite recent progress in end-to-end video understanding, accurate representations of complex articulated motions -- a task that is trivial for humans -- remains an open problem for end-to-end learning.
NeRF-US: Removing Ultrasound Imaging Artifacts from Neural Radiance Fields in the Wild
Aug 21, 2024



Current methods for performing 3D reconstruction and novel view synthesis (NVS) in ultrasound imaging data often face severe artifacts when training NeRF-based approaches. The artifacts produced by current approaches differ from NeRF floaters in general scenes because of the unique nature of ultrasound capture. Furthermore, existing models fail to produce reasonable 3D reconstructions when ultrasound data is captured or obtained casually in uncontrolled environments, which is common in clinical settings. Consequently, existing reconstruction and NVS methods struggle to handle ultrasound motion, fail to capture intricate details, and cannot model transparent and reflective surfaces. In this work, we introduced NeRF-US, which incorporates 3D-geometry guidance for border probability and scattering density into NeRF training, while also utilizing ultrasound-specific rendering over traditional volume rendering. These 3D priors are learned through a diffusion model. Through experiments conducted on our new "Ultrasound in the Wild" dataset, we observed accurate, clinically plausible, artifact-free reconstructions.
Beyond the Visible: Jointly Attending to Spectral and Spatial Dimensions with HSI-Diffusion for the FINCH Spacecraft
Jun 15, 2024Satellite remote sensing missions have gained popularity over the past fifteen years due to their ability to cover large swaths of land at regular intervals, making them ideal for monitoring environmental trends. The FINCH mission, a 3U+ CubeSat equipped with a hyperspectral camera, aims to monitor crop residue cover in agricultural fields. Although hyperspectral imaging captures both spectral and spatial information, it is prone to various types of noise, including random noise, stripe noise, and dead pixels. Effective denoising of these images is crucial for downstream scientific tasks. Traditional methods, including hand-crafted techniques encoding strong priors, learned 2D image denoising methods applied across different hyperspectral bands, or diffusion generative models applied independently on bands, often struggle with varying noise strengths across spectral bands, leading to significant spectral distortion. This paper presents a novel approach to hyperspectral image denoising using latent diffusion models that integrate spatial and spectral information. We particularly do so by building a 3D diffusion model and presenting a 3-stage training approach on real and synthetically crafted datasets. The proposed method preserves image structure while reducing noise. Evaluations on both popular hyperspectral denoising datasets and synthetically crafted datasets for the FINCH mission demonstrate the effectiveness of this approach.
SEE-2-SOUND: Zero-Shot Spatial Environment-to-Spatial Sound
Jun 06, 2024
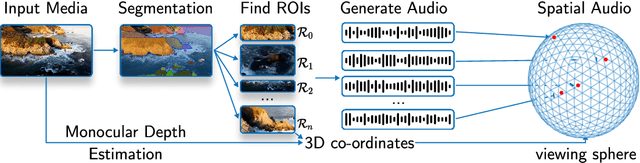
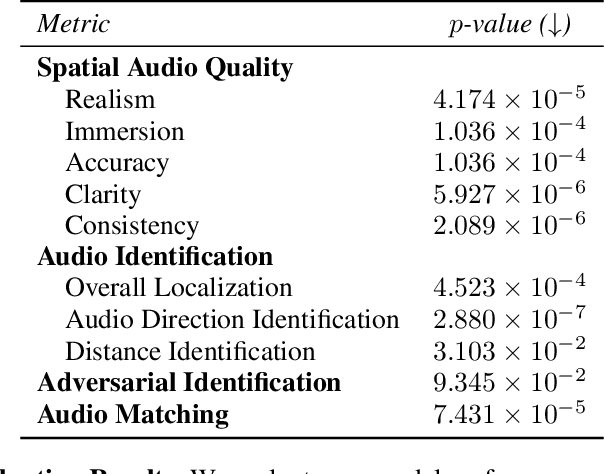
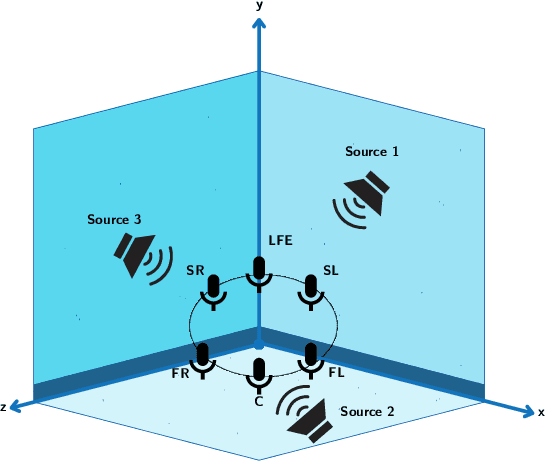
Generating combined visual and auditory sensory experiences is critical for the consumption of immersive content. Recent advances in neural generative models have enabled the creation of high-resolution content across multiple modalities such as images, text, speech, and videos. Despite these successes, there remains a significant gap in the generation of high-quality spatial audio that complements generated visual content. Furthermore, current audio generation models excel in either generating natural audio or speech or music but fall short in integrating spatial audio cues necessary for immersive experiences. In this work, we introduce SEE-2-SOUND, a zero-shot approach that decomposes the task into (1) identifying visual regions of interest; (2) locating these elements in 3D space; (3) generating mono-audio for each; and (4) integrating them into spatial audio. Using our framework, we demonstrate compelling results for generating spatial audio for high-quality videos, images, and dynamic images from the internet, as well as media generated by learned approaches.
Tuning In: Analysis of Audio Classifier Performance in Clinical Settings with Limited Data
Feb 19, 2024This study assesses deep learning models for audio classification in a clinical setting with the constraint of small datasets reflecting real-world prospective data collection. We analyze CNNs, including DenseNet and ConvNeXt, alongside transformer models like ViT, SWIN, and AST, and compare them against pre-trained audio models such as YAMNet and VGGish. Our method highlights the benefits of pre-training on large datasets before fine-tuning on specific clinical data. We prospectively collected two first-of-their-kind patient audio datasets from stroke patients. We investigated various preprocessing techniques, finding that RGB and grayscale spectrogram transformations affect model performance differently based on the priors they learn from pre-training. Our findings indicate CNNs can match or exceed transformer models in small dataset contexts, with DenseNet-Contrastive and AST models showing notable performance. This study highlights the significance of incremental marginal gains through model selection, pre-training, and preprocessing in sound classification; this offers valuable insights for clinical diagnostics that rely on audio classification.
Astroformer: More Data Might not be all you need for Classification
Apr 26, 2023


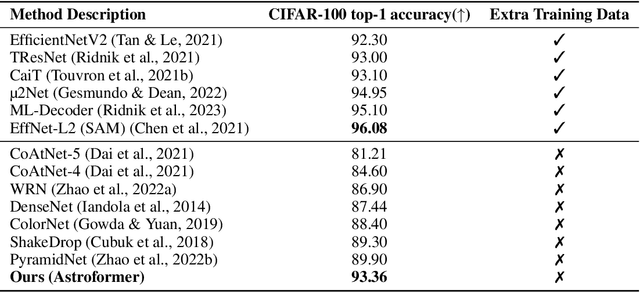
Recent advancements in areas such as natural language processing and computer vision rely on intricate and massive models that have been trained using vast amounts of unlabelled or partly labeled data and training or deploying these state-of-the-art methods to resource constraint environments has been a challenge. Galaxy morphologies are crucial to understanding the processes by which galaxies form and evolve. Efficient methods to classify galaxy morphologies are required to extract physical information from modern-day astronomy surveys. In this paper, we introduce Astroformer, a method to learn from less amount of data. We propose using a hybrid transformer-convolutional architecture drawing much inspiration from the success of CoAtNet and MaxViT. Concretely, we use the transformer-convolutional hybrid with a new stack design for the network, a different way of creating a relative self-attention layer, and pair it with a careful selection of data augmentation and regularization techniques. Our approach sets a new state-of-the-art on predicting galaxy morphologies from images on the Galaxy10 DECals dataset, a science objective, which consists of 17736 labeled images achieving 94.86% top-$1$ accuracy, beating the current state-of-the-art for this task by 4.62%. Furthermore, this approach also sets a new state-of-the-art on CIFAR-100 and Tiny ImageNet. We also find that models and training methods used for larger datasets would often not work very well in the low-data regime.
CPPE-5: Medical Personal Protective Equipment Dataset
Dec 15, 2021



We present a new challenging dataset, CPPE - 5 (Medical Personal Protective Equipment), with the goal to allow the study of subordinate categorization of medical personal protective equipments, which is not possible with other popular data sets that focus on broad level categories (such as PASCAL VOC, ImageNet, Microsoft COCO, OpenImages, etc). To make it easy for models trained on this dataset to be used in practical scenarios in complex scenes, our dataset mainly contains images that show complex scenes with several objects in each scene in their natural context. The image collection for this dataset focusing on: obtaining as many non-iconic images as possible and making sure all the images are real-life images unlike other existing datasets in this area. Our dataset includes 5 object categories (coveralls, face shield, gloves, mask, and goggles) and each image is annotated with a set of bounding boxes and positive labels. We present a detailed analysis of the dataset in comparison to other popular broad category datasets as well as datasets focusing on personal protective equipments, we also find that at present there exist no such publicly available datasets. Finally we also analyze performance and compare model complexities on baseline and state-of-the-art models for bounding box results. Our code, data, and trained models are available at https://git.io/cppe5-dataset .