 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA User-Tunable Machine Learning Framework for Step-Wise Synthesis Planning
Apr 03, 2025We introduce MHNpath, a machine learning-driven retrosynthetic tool designed for computer-aided synthesis planning. Leveraging modern Hopfield networks and novel comparative metrics, MHNpath efficiently prioritizes reaction templates, improving the scalability and accuracy of retrosynthetic predictions. The tool incorporates a tunable scoring system that allows users to prioritize pathways based on cost, reaction temperature, and toxicity, thereby facilitating the design of greener and cost-effective reaction routes. We demonstrate its effectiveness through case studies involving complex molecules from ChemByDesign, showcasing its ability to predict novel synthetic and enzymatic pathways. Furthermore, we benchmark MHNpath against existing frameworks, replicating experimentally validated "gold-standard" pathways from PaRoutes. Our case studies reveal that the tool can generate shorter, cheaper, moderate-temperature routes employing green solvents, as exemplified by compounds such as dronabinol, arformoterol, and lupinine.
Efficient Training of Transformers for Molecule Property Prediction on Small-scale Datasets
Sep 07, 2024

The blood-brain barrier (BBB) serves as a protective barrier that separates the brain from the circulatory system, regulating the passage of substances into the central nervous system. Assessing the BBB permeability of potential drugs is crucial for effective drug targeting. However, traditional experimental methods for measuring BBB permeability are challenging and impractical for large-scale screening. Consequently, there is a need to develop computational approaches to predict BBB permeability. This paper proposes a GPS Transformer architecture augmented with Self Attention, designed to perform well in the low-data regime. The proposed approach achieved a state-of-the-art performance on the BBB permeability prediction task using the BBBP dataset, surpassing existing models. With a ROC-AUC of 78.8%, the approach sets a state-of-the-art by 5.5%. We demonstrate that standard Self Attention coupled with GPS transformer performs better than other variants of attention coupled with GPS Transformer.
Beyond the Visible: Jointly Attending to Spectral and Spatial Dimensions with HSI-Diffusion for the FINCH Spacecraft
Jun 15, 2024Satellite remote sensing missions have gained popularity over the past fifteen years due to their ability to cover large swaths of land at regular intervals, making them ideal for monitoring environmental trends. The FINCH mission, a 3U+ CubeSat equipped with a hyperspectral camera, aims to monitor crop residue cover in agricultural fields. Although hyperspectral imaging captures both spectral and spatial information, it is prone to various types of noise, including random noise, stripe noise, and dead pixels. Effective denoising of these images is crucial for downstream scientific tasks. Traditional methods, including hand-crafted techniques encoding strong priors, learned 2D image denoising methods applied across different hyperspectral bands, or diffusion generative models applied independently on bands, often struggle with varying noise strengths across spectral bands, leading to significant spectral distortion. This paper presents a novel approach to hyperspectral image denoising using latent diffusion models that integrate spatial and spectral information. We particularly do so by building a 3D diffusion model and presenting a 3-stage training approach on real and synthetically crafted datasets. The proposed method preserves image structure while reducing noise. Evaluations on both popular hyperspectral denoising datasets and synthetically crafted datasets for the FINCH mission demonstrate the effectiveness of this approach.
SEE-2-SOUND: Zero-Shot Spatial Environment-to-Spatial Sound
Jun 06, 2024
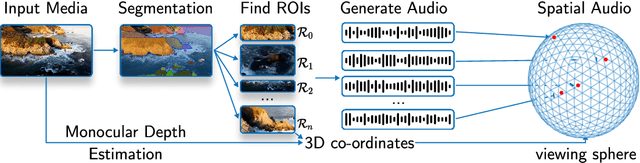
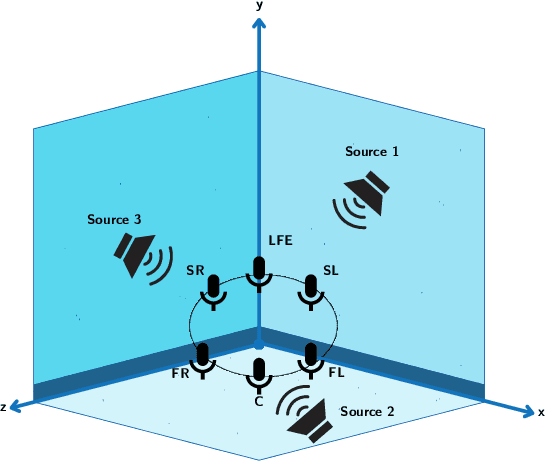
Generating combined visual and auditory sensory experiences is critical for the consumption of immersive content. Recent advances in neural generative models have enabled the creation of high-resolution content across multiple modalities such as images, text, speech, and videos. Despite these successes, there remains a significant gap in the generation of high-quality spatial audio that complements generated visual content. Furthermore, current audio generation models excel in either generating natural audio or speech or music but fall short in integrating spatial audio cues necessary for immersive experiences. In this work, we introduce SEE-2-SOUND, a zero-shot approach that decomposes the task into (1) identifying visual regions of interest; (2) locating these elements in 3D space; (3) generating mono-audio for each; and (4) integrating them into spatial audio. Using our framework, we demonstrate compelling results for generating spatial audio for high-quality videos, images, and dynamic images from the internet, as well as media generated by learned approaches.