 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSEE-2-SOUND: Zero-Shot Spatial Environment-to-Spatial Sound
Jun 06, 2024
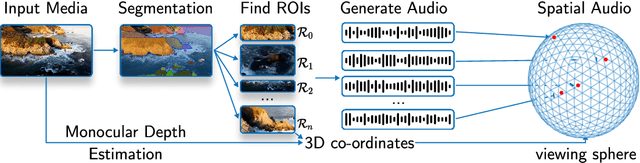
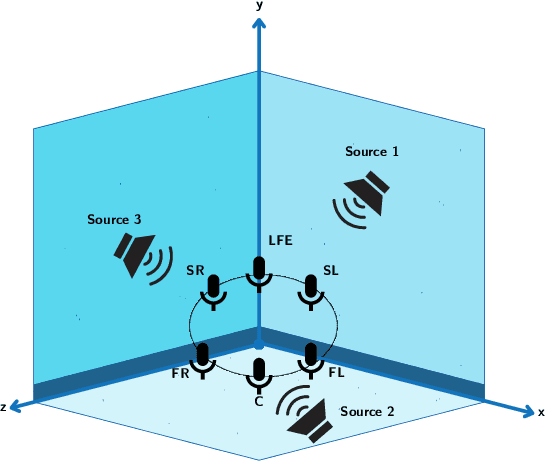
Generating combined visual and auditory sensory experiences is critical for the consumption of immersive content. Recent advances in neural generative models have enabled the creation of high-resolution content across multiple modalities such as images, text, speech, and videos. Despite these successes, there remains a significant gap in the generation of high-quality spatial audio that complements generated visual content. Furthermore, current audio generation models excel in either generating natural audio or speech or music but fall short in integrating spatial audio cues necessary for immersive experiences. In this work, we introduce SEE-2-SOUND, a zero-shot approach that decomposes the task into (1) identifying visual regions of interest; (2) locating these elements in 3D space; (3) generating mono-audio for each; and (4) integrating them into spatial audio. Using our framework, we demonstrate compelling results for generating spatial audio for high-quality videos, images, and dynamic images from the internet, as well as media generated by learned approaches.
Tuning In: Analysis of Audio Classifier Performance in Clinical Settings with Limited Data
Feb 19, 2024This study assesses deep learning models for audio classification in a clinical setting with the constraint of small datasets reflecting real-world prospective data collection. We analyze CNNs, including DenseNet and ConvNeXt, alongside transformer models like ViT, SWIN, and AST, and compare them against pre-trained audio models such as YAMNet and VGGish. Our method highlights the benefits of pre-training on large datasets before fine-tuning on specific clinical data. We prospectively collected two first-of-their-kind patient audio datasets from stroke patients. We investigated various preprocessing techniques, finding that RGB and grayscale spectrogram transformations affect model performance differently based on the priors they learn from pre-training. Our findings indicate CNNs can match or exceed transformer models in small dataset contexts, with DenseNet-Contrastive and AST models showing notable performance. This study highlights the significance of incremental marginal gains through model selection, pre-training, and preprocessing in sound classification; this offers valuable insights for clinical diagnostics that rely on audio classification.