 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKsurf-Drone: Attention Kalman Filter for Contextual Bandit Optimization in Cloud Resource Allocation
Nov 12, 2025Resource orchestration and configuration parameter search are key concerns for container-based infrastructure in cloud data centers. Large configuration search space and cloud uncertainties are often mitigated using contextual bandit techniques for resource orchestration including the state-of-the-art Drone orchestrator. Complexity in the cloud provider environment due to varying numbers of virtual machines introduces variability in workloads and resource metrics, making orchestration decisions less accurate due to increased nonlinearity and noise. Ksurf, a state-of-the-art variance-minimizing estimator method ideal for highly variable cloud data, enables optimal resource estimation under conditions of high cloud variability. This work evaluates the performance of Ksurf on estimation-based resource orchestration tasks involving highly variable workloads when employed as a contextual multi-armed bandit objective function model for cloud scenarios using Drone. Ksurf enables significantly lower latency variance of $41\%$ at p95 and $47\%$ at p99, demonstrates a $4\%$ reduction in CPU usage and 7 MB reduction in master node memory usage on Kubernetes, resulting in a $7\%$ cost savings in average worker pod count on VarBench Kubernetes benchmark.
GALA: Can Graph-Augmented Large Language Model Agentic Workflows Elevate Root Cause Analysis?
Aug 17, 2025Root cause analysis (RCA) in microservice systems is challenging, requiring on-call engineers to rapidly diagnose failures across heterogeneous telemetry such as metrics, logs, and traces. Traditional RCA methods often focus on single modalities or merely rank suspect services, falling short of providing actionable diagnostic insights with remediation guidance. This paper introduces GALA, a novel multi-modal framework that combines statistical causal inference with LLM-driven iterative reasoning for enhanced RCA. Evaluated on an open-source benchmark, GALA achieves substantial improvements over state-of-the-art methods of up to 42.22% accuracy. Our novel human-guided LLM evaluation score shows GALA generates significantly more causally sound and actionable diagnostic outputs than existing methods. Through comprehensive experiments and a case study, we show that GALA bridges the gap between automated failure diagnosis and practical incident resolution by providing both accurate root cause identification and human-interpretable remediation guidance.
Dynamically Learned Test-Time Model Routing in Language Model Zoos with Service Level Guarantees
May 26, 2025Open-weight LLM zoos provide access to numerous high-quality models, but selecting the appropriate model for specific tasks remains challenging and requires technical expertise. Most users simply want factually correct, safe, and satisfying responses without concerning themselves with model technicalities, while inference service providers prioritize minimizing operating costs. These competing interests are typically mediated through service level agreements (SLAs) that guarantee minimum service quality. We introduce MESS+, a stochastic optimization algorithm for cost-optimal LLM request routing while providing rigorous SLA compliance guarantees. MESS+ learns request satisfaction probabilities of LLMs in real-time as users interact with the system, based on which model selection decisions are made by solving a per-request optimization problem. Our algorithm includes a novel combination of virtual queues and request satisfaction prediction, along with a theoretical analysis of cost optimality and constraint satisfaction. Across a wide range of state-of-the-art LLM benchmarks, MESS+ achieves an average of 2x cost savings compared to existing LLM routing techniques.
A User-Tunable Machine Learning Framework for Step-Wise Synthesis Planning
Apr 03, 2025We introduce MHNpath, a machine learning-driven retrosynthetic tool designed for computer-aided synthesis planning. Leveraging modern Hopfield networks and novel comparative metrics, MHNpath efficiently prioritizes reaction templates, improving the scalability and accuracy of retrosynthetic predictions. The tool incorporates a tunable scoring system that allows users to prioritize pathways based on cost, reaction temperature, and toxicity, thereby facilitating the design of greener and cost-effective reaction routes. We demonstrate its effectiveness through case studies involving complex molecules from ChemByDesign, showcasing its ability to predict novel synthetic and enzymatic pathways. Furthermore, we benchmark MHNpath against existing frameworks, replicating experimentally validated "gold-standard" pathways from PaRoutes. Our case studies reveal that the tool can generate shorter, cheaper, moderate-temperature routes employing green solvents, as exemplified by compounds such as dronabinol, arformoterol, and lupinine.
WaveGAS: Waveform Relaxation for Scaling Graph Neural Networks
Feb 27, 2025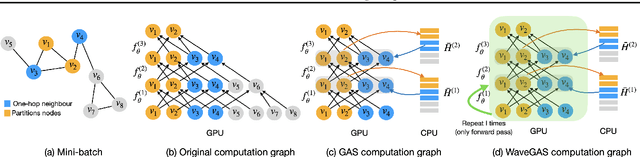
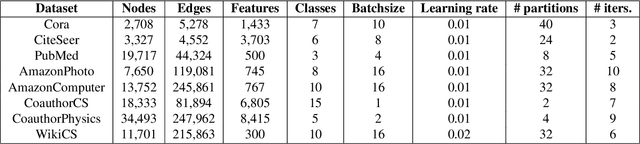
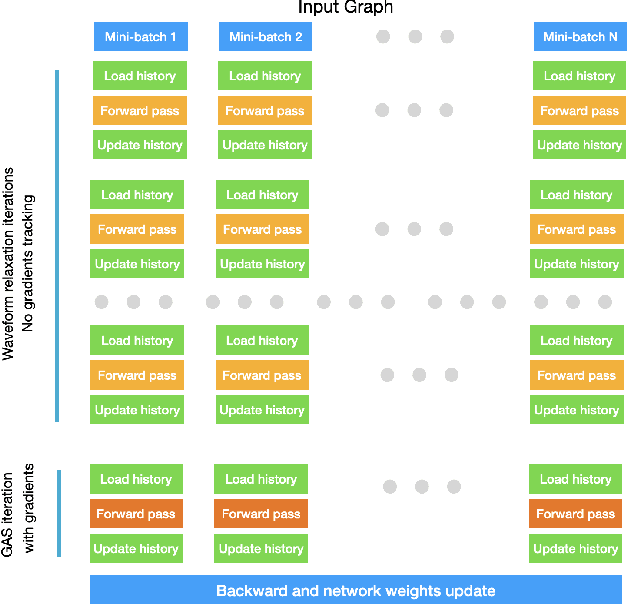
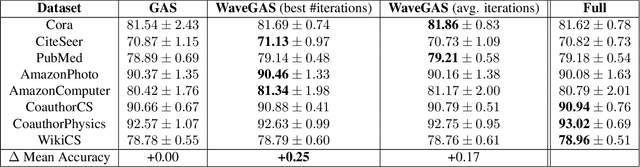
With the ever-growing size of real-world graphs, numerous techniques to overcome resource limitations when training Graph Neural Networks (GNNs) have been developed. One such approach, GNNAutoScale (GAS), uses graph partitioning to enable training under constrained GPU memory. GAS also stores historical embedding vectors, which are retrieved from one-hop neighbors in other partitions, ensuring critical information is captured across partition boundaries. The historical embeddings which come from the previous training iteration are stale compared to the GAS estimated embeddings, resulting in approximation errors of the training algorithm. Furthermore, these errors accumulate over multiple layers, leading to suboptimal node embeddings. To address this shortcoming, we propose two enhancements: first, WaveGAS, inspired by waveform relaxation, performs multiple forward passes within GAS before the backward pass, refining the approximation of historical embeddings and gradients to improve accuracy; second, a gradient-tracking method that stores and utilizes more accurate historical gradients during training. Empirical results show that WaveGAS enhances GAS and achieves better accuracy, even outperforming methods that train on full graphs, thanks to its robust estimation of node embeddings.
Dynamic Loss-Based Sample Reweighting for Improved Large Language Model Pretraining
Feb 10, 2025



Pretraining large language models (LLMs) on vast and heterogeneous datasets is crucial for achieving state-of-the-art performance across diverse downstream tasks. However, current training paradigms treat all samples equally, overlooking the importance or relevance of individual samples throughout the training process. Existing reweighting strategies, which primarily focus on group-level data importance, fail to leverage fine-grained instance-level information and do not adapt dynamically to individual sample importance as training progresses. In this paper, we introduce novel algorithms for dynamic, instance-level data reweighting aimed at improving both the efficiency and effectiveness of LLM pretraining. Our methods adjust the weight of each training sample based on its loss value in an online fashion, allowing the model to dynamically focus on more informative or important samples at the current training stage. In particular, our framework allows us to systematically devise reweighting strategies deprioritizing redundant or uninformative data, which we find tend to work best. Furthermore, we develop a new theoretical framework for analyzing the impact of loss-based reweighting on the convergence of gradient-based optimization, providing the first formal characterization of how these strategies affect convergence bounds. We empirically validate our approach across a spectrum of tasks, from pretraining 7B and 1.4B parameter LLMs to smaller-scale language models and linear regression problems, demonstrating that our loss-based reweighting approach can lead to faster convergence and significantly improved performance.
Can Graph Reordering Speed Up Graph Neural Network Training? An Experimental Study
Sep 17, 2024Graph neural networks (GNNs) are a type of neural network capable of learning on graph-structured data. However, training GNNs on large-scale graphs is challenging due to iterative aggregations of high-dimensional features from neighboring vertices within sparse graph structures combined with neural network operations. The sparsity of graphs frequently results in suboptimal memory access patterns and longer training time. Graph reordering is an optimization strategy aiming to improve the graph data layout. It has shown to be effective to speed up graph analytics workloads, but its effect on the performance of GNN training has not been investigated yet. The generalization of reordering to GNN performance is nontrivial, as multiple aspects must be considered: GNN hyper-parameters such as the number of layers, the number of hidden dimensions, and the feature size used in the GNN model, neural network operations, large intermediate vertex states, and GPU acceleration. In our work, we close this gap by performing an empirical evaluation of 12 reordering strategies in two state-of-the-art GNN systems, PyTorch Geometric and Deep Graph Library. Our results show that graph reordering is effective in reducing training time for CPU- and GPU-based training, respectively. Further, we find that GNN hyper-parameters influence the effectiveness of reordering, that reordering metrics play an important role in selecting a reordering strategy, that lightweight reordering performs better for GPU-based than for CPU-based training, and that invested reordering time can in many cases be amortized.
Federated Learning and AI Regulation in the European Union: Who is liable? An Interdisciplinary Analysis
Jul 11, 2024The European Union Artificial Intelligence Act mandates clear stakeholder responsibilities in developing and deploying machine learning applications to avoid substantial fines, prioritizing private and secure data processing with data remaining at its origin. Federated Learning (FL) enables the training of generative AI Models across data siloes, sharing only model parameters while improving data security. Since FL is a cooperative learning paradigm, clients and servers naturally share legal responsibility in the FL pipeline. Our work contributes to clarifying the roles of both parties, explains strategies for shifting responsibilities to the server operator, and points out open technical challenges that we must solve to improve FL's practical applicability under the EU AI Act.
Federated Computing -- Survey on Building Blocks, Extensions and Systems
Apr 03, 2024In response to the increasing volume and sensitivity of data, traditional centralized computing models face challenges, such as data security breaches and regulatory hurdles. Federated Computing (FC) addresses these concerns by enabling collaborative processing without compromising individual data privacy. This is achieved through a decentralized network of devices, each retaining control over its data, while participating in collective computations. The motivation behind FC extends beyond technical considerations to encompass societal implications. As the need for responsible AI and ethical data practices intensifies, FC aligns with the principles of user empowerment and data sovereignty. FC comprises of Federated Learning (FL) and Federated Analytics (FA). FC systems became more complex over time and they currently lack a clear definition and taxonomy describing its moving pieces. Current surveys capture domain-specific FL use cases, describe individual components in an FC pipeline individually or decoupled from each other, or provide a quantitative overview of the number of published papers. This work surveys more than 150 papers to distill the underlying structure of FC systems with their basic building blocks, extensions, architecture, environment, and motivation. We capture FL and FA systems individually and point out unique difference between those two.
Federated Learning Priorities Under the European Union Artificial Intelligence Act
Feb 05, 2024



The age of AI regulation is upon us, with the European Union Artificial Intelligence Act (AI Act) leading the way. Our key inquiry is how this will affect Federated Learning (FL), whose starting point of prioritizing data privacy while performing ML fundamentally differs from that of centralized learning. We believe the AI Act and future regulations could be the missing catalyst that pushes FL toward mainstream adoption. However, this can only occur if the FL community reprioritizes its research focus. In our position paper, we perform a first-of-its-kind interdisciplinary analysis (legal and ML) of the impact the AI Act may have on FL and make a series of observations supporting our primary position through quantitative and qualitative analysis. We explore data governance issues and the concern for privacy. We establish new challenges regarding performance and energy efficiency within lifecycle monitoring. Taken together, our analysis suggests there is a sizable opportunity for FL to become a crucial component of AI Act-compliant ML systems and for the new regulation to drive the adoption of FL techniques in general. Most noteworthy are the opportunities to defend against data bias and enhance private and secure computation