 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIt's All Connected: Topology-Aware Structural Graph Encoding Improves Performance on Polymer Prediction
May 11, 2026Graph Neural Networks (GNNs) have achieved strong results in molecular property prediction, but polymers present distinct challenges: labeled datasets are scarce and small (typically in the order of hundreds of polymers) due to the need for expensive experimentation, and complex polymer chain distributions influence polymer properties. Established practice in polymer prediction represents polymers solely by graphs of their repeat units, discarding the chain-scale morphology that governs key properties such as the glass transition temperature ($T_g$). In this work, we propose a principled graph construction that addresses this gap. Given a polymer's molecular mass distribution (MMD), we sample representative chains from the Schulz-Zimm distribution and construct representative sets of large graphs encoding chain-scale topology directly, with atoms and bonds featurized using rich chemical descriptors. We further pretrain GNN encoders via masked graph modeling on 100,000 unlabeled PSMILES strings before fine-tuning on labeled data. On a dataset of 381 polymers (180 homopolymers and 201 copolymers), we show that graph construction and self-supervised pretraining are jointly necessary: without pretraining, the large graph method matches the repeat-unit baseline (28.40 K vs. 28.36 K RMSE); with pretraining, it achieves 24.76 K +/- 3.30 K, a 5.1% reduction in mean error over the pretrained repeat-unit baseline (26.08 K +/- 4.20 K, p < 0.001, 30 runs). An ablation removing chemical features degrades performance to 36.65 K, confirming both components are essential. Results are architecture-agnostic, holding for both GINE and GATv2 encoders.
EmbedPart: Embedding-Driven Graph Partitioning for Scalable Graph Neural Network Training
Apr 01, 2026Graph Neural Networks (GNNs) are widely used for learning on graph-structured data, but scaling GNN training to massive graphs remains challenging. To enable scalable distributed training, graphs are divided into smaller partitions that are distributed across multiple machines such that inter-machine communication is minimized and computational load is balanced. In practice, existing partitioning approaches face a fundamental trade-off between partitioning overhead and partitioning quality. We propose EmbedPart, an embedding-driven partitioning approach that achieves both speed and quality. Instead of operating directly on irregular graph structures, EmbedPart leverages node embeddings produced during the actual GNN training workload and clusters these dense embeddings to derive a partitioning. EmbedPart achieves more than 100x speedup over Metis while maintaining competitive partitioning quality and accelerating distributed GNN training. Moreover, EmbedPart naturally supports graph updates and fast repartitioning, and can be applied to graph reordering to improve data locality and accelerate single-machine GNN training. By shifting partitioning from irregular graph structures to dense embeddings, EmbedPart enables scalable and high-quality graph data optimization.
Position: Federated Foundation Language Model Post-Training Should Focus on Open-Source Models
May 29, 2025
Post-training of foundation language models has emerged as a promising research domain in federated learning (FL) with the goal to enable privacy-preserving model improvements and adaptations to user's downstream tasks. Recent advances in this area adopt centralized post-training approaches that build upon black-box foundation language models where there is no access to model weights and architecture details. Although the use of black-box models has been successful in centralized post-training, their blind replication in FL raises several concerns. Our position is that using black-box models in FL contradicts the core principles of federation such as data privacy and autonomy. In this position paper, we critically analyze the usage of black-box models in federated post-training, and provide a detailed account of various aspects of openness and their implications for FL.
Comparing Methods for Bias Mitigation in Graph Neural Networks
Mar 28, 2025This paper examines the critical role of Graph Neural Networks (GNNs) in data preparation for generative artificial intelligence (GenAI) systems, with a particular focus on addressing and mitigating biases. We present a comparative analysis of three distinct methods for bias mitigation: data sparsification, feature modification, and synthetic data augmentation. Through experimental analysis using the german credit dataset, we evaluate these approaches using multiple fairness metrics, including statistical parity, equality of opportunity, and false positive rates. Our research demonstrates that while all methods improve fairness metrics compared to the original dataset, stratified sampling and synthetic data augmentation using GraphSAGE prove particularly effective in balancing demographic representation while maintaining model performance. The results provide practical insights for developing more equitable AI systems while maintaining model performance.
WaveGAS: Waveform Relaxation for Scaling Graph Neural Networks
Feb 27, 2025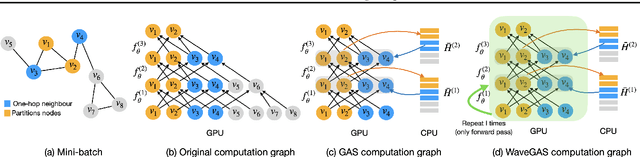
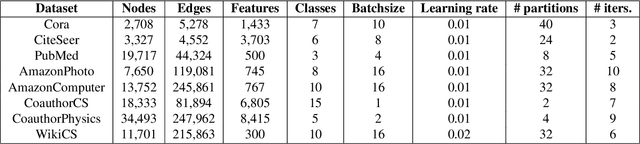
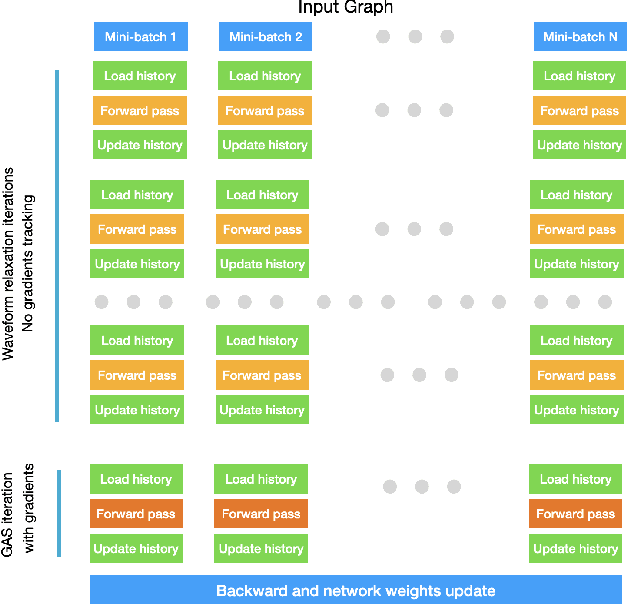
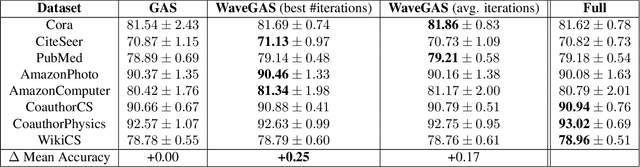
With the ever-growing size of real-world graphs, numerous techniques to overcome resource limitations when training Graph Neural Networks (GNNs) have been developed. One such approach, GNNAutoScale (GAS), uses graph partitioning to enable training under constrained GPU memory. GAS also stores historical embedding vectors, which are retrieved from one-hop neighbors in other partitions, ensuring critical information is captured across partition boundaries. The historical embeddings which come from the previous training iteration are stale compared to the GAS estimated embeddings, resulting in approximation errors of the training algorithm. Furthermore, these errors accumulate over multiple layers, leading to suboptimal node embeddings. To address this shortcoming, we propose two enhancements: first, WaveGAS, inspired by waveform relaxation, performs multiple forward passes within GAS before the backward pass, refining the approximation of historical embeddings and gradients to improve accuracy; second, a gradient-tracking method that stores and utilizes more accurate historical gradients during training. Empirical results show that WaveGAS enhances GAS and achieves better accuracy, even outperforming methods that train on full graphs, thanks to its robust estimation of node embeddings.
Vision Paper: Designing Graph Neural Networks in Compliance with the European Artificial Intelligence Act
Oct 29, 2024The European Union's Artificial Intelligence Act (AI Act) introduces comprehensive guidelines for the development and oversight of Artificial Intelligence (AI) and Machine Learning (ML) systems, with significant implications for Graph Neural Networks (GNNs). This paper addresses the unique challenges posed by the AI Act for GNNs, which operate on complex graph-structured data. The legislation's requirements for data management, data governance, robustness, human oversight, and privacy necessitate tailored strategies for GNNs. Our study explores the impact of these requirements on GNN training and proposes methods to ensure compliance. We provide an in-depth analysis of bias, robustness, explainability, and privacy in the context of GNNs, highlighting the need for fair sampling strategies and effective interpretability techniques. Our contributions fill the research gap by offering specific guidance for GNNs under the new legislative framework and identifying open questions and future research directions.
Can Graph Reordering Speed Up Graph Neural Network Training? An Experimental Study
Sep 17, 2024Graph neural networks (GNNs) are a type of neural network capable of learning on graph-structured data. However, training GNNs on large-scale graphs is challenging due to iterative aggregations of high-dimensional features from neighboring vertices within sparse graph structures combined with neural network operations. The sparsity of graphs frequently results in suboptimal memory access patterns and longer training time. Graph reordering is an optimization strategy aiming to improve the graph data layout. It has shown to be effective to speed up graph analytics workloads, but its effect on the performance of GNN training has not been investigated yet. The generalization of reordering to GNN performance is nontrivial, as multiple aspects must be considered: GNN hyper-parameters such as the number of layers, the number of hidden dimensions, and the feature size used in the GNN model, neural network operations, large intermediate vertex states, and GPU acceleration. In our work, we close this gap by performing an empirical evaluation of 12 reordering strategies in two state-of-the-art GNN systems, PyTorch Geometric and Deep Graph Library. Our results show that graph reordering is effective in reducing training time for CPU- and GPU-based training, respectively. Further, we find that GNN hyper-parameters influence the effectiveness of reordering, that reordering metrics play an important role in selecting a reordering strategy, that lightweight reordering performs better for GPU-based than for CPU-based training, and that invested reordering time can in many cases be amortized.
Federated Learning and AI Regulation in the European Union: Who is liable? An Interdisciplinary Analysis
Jul 11, 2024The European Union Artificial Intelligence Act mandates clear stakeholder responsibilities in developing and deploying machine learning applications to avoid substantial fines, prioritizing private and secure data processing with data remaining at its origin. Federated Learning (FL) enables the training of generative AI Models across data siloes, sharing only model parameters while improving data security. Since FL is a cooperative learning paradigm, clients and servers naturally share legal responsibility in the FL pipeline. Our work contributes to clarifying the roles of both parties, explains strategies for shifting responsibilities to the server operator, and points out open technical challenges that we must solve to improve FL's practical applicability under the EU AI Act.
Federated Computing -- Survey on Building Blocks, Extensions and Systems
Apr 03, 2024In response to the increasing volume and sensitivity of data, traditional centralized computing models face challenges, such as data security breaches and regulatory hurdles. Federated Computing (FC) addresses these concerns by enabling collaborative processing without compromising individual data privacy. This is achieved through a decentralized network of devices, each retaining control over its data, while participating in collective computations. The motivation behind FC extends beyond technical considerations to encompass societal implications. As the need for responsible AI and ethical data practices intensifies, FC aligns with the principles of user empowerment and data sovereignty. FC comprises of Federated Learning (FL) and Federated Analytics (FA). FC systems became more complex over time and they currently lack a clear definition and taxonomy describing its moving pieces. Current surveys capture domain-specific FL use cases, describe individual components in an FC pipeline individually or decoupled from each other, or provide a quantitative overview of the number of published papers. This work surveys more than 150 papers to distill the underlying structure of FC systems with their basic building blocks, extensions, architecture, environment, and motivation. We capture FL and FA systems individually and point out unique difference between those two.
Federated Learning Priorities Under the European Union Artificial Intelligence Act
Feb 05, 2024



The age of AI regulation is upon us, with the European Union Artificial Intelligence Act (AI Act) leading the way. Our key inquiry is how this will affect Federated Learning (FL), whose starting point of prioritizing data privacy while performing ML fundamentally differs from that of centralized learning. We believe the AI Act and future regulations could be the missing catalyst that pushes FL toward mainstream adoption. However, this can only occur if the FL community reprioritizes its research focus. In our position paper, we perform a first-of-its-kind interdisciplinary analysis (legal and ML) of the impact the AI Act may have on FL and make a series of observations supporting our primary position through quantitative and qualitative analysis. We explore data governance issues and the concern for privacy. We establish new challenges regarding performance and energy efficiency within lifecycle monitoring. Taken together, our analysis suggests there is a sizable opportunity for FL to become a crucial component of AI Act-compliant ML systems and for the new regulation to drive the adoption of FL techniques in general. Most noteworthy are the opportunities to defend against data bias and enhance private and secure computation