 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComputational Compliance for AI Regulation: Blueprint for a New Research Domain
Jan 08, 2026The era of AI regulation (AIR) is upon us. But AI systems, we argue, will not be able to comply with these regulations at the necessary speed and scale by continuing to rely on traditional, analogue methods of compliance. Instead, we posit that compliance with these regulations will only realistically be achieved computationally: that is, with algorithms that run across the life cycle of an AI system, automatically steering it toward AIR compliance in the face of dynamic conditions. Yet despite their (we would argue) inevitability, the research community has yet to specify exactly how these algorithms for computational AIR compliance should behave - or how we should benchmark their performance. To fill these gaps, we specify a set of design goals for such algorithms. In addition, we specify a benchmark dataset that can be used to quantitatively measure whether individual algorithms satisfy these design goals. By delivering this blueprint, we hope to give shape to an important but uncrystallized new domain of research - and, in doing so, incite necessary investment in it.
AIReg-Bench: Benchmarking Language Models That Assess AI Regulation Compliance
Oct 01, 2025As governments move to regulate AI, there is growing interest in using Large Language Models (LLMs) to assess whether or not an AI system complies with a given AI Regulation (AIR). However, there is presently no way to benchmark the performance of LLMs at this task. To fill this void, we introduce AIReg-Bench: the first benchmark dataset designed to test how well LLMs can assess compliance with the EU AI Act (AIA). We created this dataset through a two-step process: (1) by prompting an LLM with carefully structured instructions, we generated 120 technical documentation excerpts (samples), each depicting a fictional, albeit plausible, AI system - of the kind an AI provider might produce to demonstrate their compliance with AIR; (2) legal experts then reviewed and annotated each sample to indicate whether, and in what way, the AI system described therein violates specific Articles of the AIA. The resulting dataset, together with our evaluation of whether frontier LLMs can reproduce the experts' compliance labels, provides a starting point to understand the opportunities and limitations of LLM-based AIR compliance assessment tools and establishes a benchmark against which subsequent LLMs can be compared. The dataset and evaluation code are available at https://github.com/camlsys/aireg-bench.
Bridge the Gaps between Machine Unlearning and AI Regulation
Feb 18, 2025The "right to be forgotten" and the data privacy laws that encode it have motivated machine unlearning since its earliest days. Now, an inbound wave of artificial intelligence regulations - like the European Union's Artificial Intelligence Act (AIA) - potentially offer important new use cases for machine unlearning. However, this position paper argues, this opportunity will only be realized if researchers, aided by policymakers, proactively bridge the (sometimes sizable) gaps between machine unlearning's state of the art and its potential applications to AI regulation. To demonstrate this point, we use the AIA as an example. Specifically, we deliver a "state of the union" as regards machine unlearning's current potential for aiding compliance with the AIA. This starts with a precise cataloging of the potential applications of machine unlearning to AIA compliance. For each, we flag any legal ambiguities clouding the potential application and, moreover, flag the technical gaps that exist between the potential application and the state of the art of machine unlearning. Finally, we end with a call to action: for both machine learning researchers and policymakers, to, respectively, solve the open technical and legal questions that will unlock machine unlearning's potential to assist compliance with the AIA - and other AI regulation like it.
Photon: Federated LLM Pre-Training
Nov 05, 2024



Scaling large language models (LLMs) demands extensive data and computing resources, which are traditionally constrained to data centers by the high-bandwidth requirements of distributed training. Low-bandwidth methods like federated learning (FL) could enable collaborative training of larger models across weakly-connected GPUs if they can effectively be used for pre-training. To achieve this, we introduce Photon, the first complete system for federated end-to-end LLM training, leveraging cross-silo FL for global-scale training with minimal communication overheads. Using Photon, we train the first federated family of decoder-only LLMs from scratch. We show that: (1) Photon can train model sizes up to 7B in a federated fashion while reaching an even better perplexity than centralized pre-training; (2) Photon model training time decreases with available compute, achieving a similar compute-time trade-off to centralized; and (3) Photon outperforms the wall-time of baseline distributed training methods by 35% via communicating 64x-512xless. Our proposal is robust to data heterogeneity and converges twice as fast as previous methods like DiLoCo. This surprising data efficiency stems from a unique approach combining small client batch sizes with extremely high learning rates, enabled by federated averaging's robustness to hyperparameters. Photon thus represents the first economical system for global internet-wide LLM pre-training.
Compliance Cards: Computational Artifacts for Automated AI Regulation Compliance
Jun 20, 2024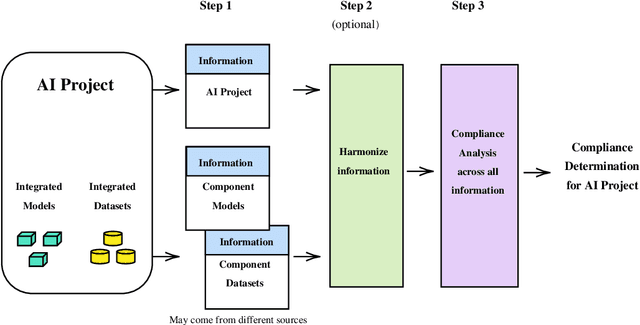

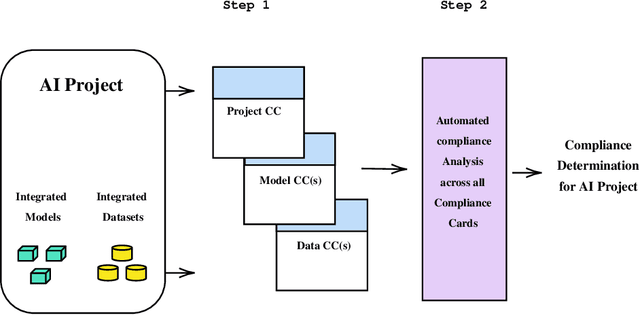
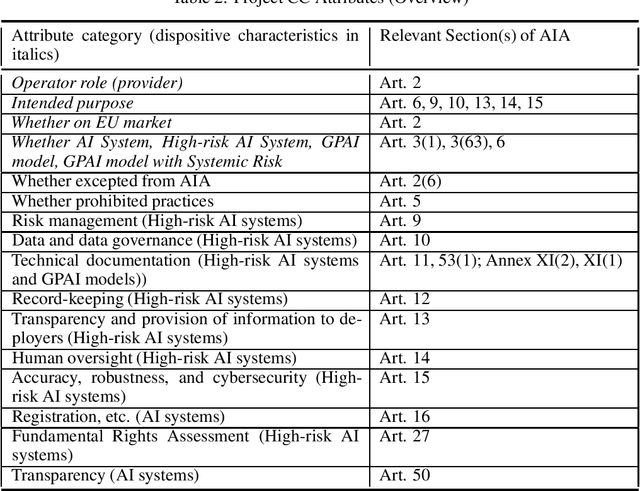
As the artificial intelligence (AI) supply chain grows more complex, AI systems and models are increasingly likely to incorporate externally-sourced ingredients such as datasets and other models. In such cases, determining whether or not an AI system or model complies with the EU AI Act will require gathering compliance-related metadata about both the AI system or model at-large as well as those externally-supplied ingredients. There must then be an analysis that looks across all of this metadata to render a prediction about the compliance of the overall AI system or model. Up until now, this process has not been automated. Thus, it has not been possible to make real-time compliance determinations in scenarios where doing so would be advantageous, such as the iterative workflows of today's AI developers, search and acquisition of AI ingredients on communities like Hugging Face, federated and continuous learning, and more. To address this shortcoming, we introduce a highly automated system for AI Act compliance analysis. This system has two key elements. First is an interlocking set of computational artifacts that capture compliance-related metadata about both: (1) the AI system or model at-large; (2) any constituent ingredients such as datasets and models. Second is an automated analysis algorithm that operates across those computational artifacts to render a run-time prediction about whether or not the overall AI system or model complies with the AI Act. Working together, these elements promise to enhance and accelerate AI Act compliance assessments.
Worldwide Federated Training of Language Models
May 23, 2024



The reliance of language model training on massive amounts of computation and vast datasets scraped from potentially low-quality, copyrighted, or sensitive data has come into question practically, legally, and ethically. Federated learning provides a plausible alternative by enabling previously untapped data to be voluntarily gathered from collaborating organizations. However, when scaled globally, federated learning requires collaboration across heterogeneous legal, security, and privacy regimes while accounting for the inherent locality of language data; this further exacerbates the established challenge of federated statistical heterogeneity. We propose a Worldwide Federated Language Model Training~(WorldLM) system based on federations of federations, where each federation has the autonomy to account for factors such as its industry, operating jurisdiction, or competitive environment. WorldLM enables such autonomy in the presence of statistical heterogeneity via partial model localization by allowing sub-federations to attentively aggregate key layers from their constituents. Furthermore, it can adaptively share information across federations via residual layer embeddings. Evaluations of language modeling on naturally heterogeneous datasets show that WorldLM outperforms standard federations by up to $1.91\times$, approaches the personalized performance of fully local models, and maintains these advantages under privacy-enhancing techniques.
The Future of Large Language Model Pre-training is Federated
May 17, 2024



Generative pre-trained large language models (LLMs) have demonstrated impressive performance over a wide range of tasks, thanks to the unprecedented amount of data they have been trained on. As established scaling laws indicate, LLMs' future performance improvement depends on the amount of computing and data sources we can leverage for pre-training. Federated learning (FL) has the potential to unleash the majority of the planet's data and computational resources, which are underutilized by the data-center-focused training methodology of current LLM practice. Our work presents a robust, flexible, reproducible FL approach that enables large-scale collaboration across institutions to train LLMs. This would mobilize more computational and data resources while matching or potentially exceeding centralized performance. We further show the effectiveness of the federated training scales with model size and present our approach for training a billion-scale federated LLM using limited resources. This will help data-rich actors to become the protagonists of LLMs pre-training instead of leaving the stage to compute-rich actors alone.
Federated Learning Priorities Under the European Union Artificial Intelligence Act
Feb 05, 2024



The age of AI regulation is upon us, with the European Union Artificial Intelligence Act (AI Act) leading the way. Our key inquiry is how this will affect Federated Learning (FL), whose starting point of prioritizing data privacy while performing ML fundamentally differs from that of centralized learning. We believe the AI Act and future regulations could be the missing catalyst that pushes FL toward mainstream adoption. However, this can only occur if the FL community reprioritizes its research focus. In our position paper, we perform a first-of-its-kind interdisciplinary analysis (legal and ML) of the impact the AI Act may have on FL and make a series of observations supporting our primary position through quantitative and qualitative analysis. We explore data governance issues and the concern for privacy. We establish new challenges regarding performance and energy efficiency within lifecycle monitoring. Taken together, our analysis suggests there is a sizable opportunity for FL to become a crucial component of AI Act-compliant ML systems and for the new regulation to drive the adoption of FL techniques in general. Most noteworthy are the opportunities to defend against data bias and enhance private and secure computation