 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask-Centric Personalized Federated Fine-Tuning of Language Models
Mar 30, 2026Federated Learning (FL) has emerged as a promising technique for training language models on distributed and private datasets of diverse tasks. However, aggregating models trained on heterogeneous tasks often degrades the overall performance of individual clients. To address this issue, Personalized FL (pFL) aims to create models tailored for each client's data distribution. Although these approaches improve local performance, they usually lack robustness in two aspects: (i) generalization: when clients must make predictions on unseen tasks, or face changes in their data distributions, and (ii) intra-client tasks interference: when a single client's data contains multiple distributions that may interfere with each other during local training. To tackle these two challenges, we propose FedRouter, a clustering-based pFL that builds specialized models for each task rather than for each client. FedRouter uses adapters to personalize models by employing two clustering mechanisms to associate adapters with specific tasks. A local clustering that associate adapters with task data samples and a global one that associates similar adapters from different clients to construct task-centric personalized models. Additionally, we propose an evaluation router mechanism that routes test samples to the best adapter based on the created clusters. Experiments comparing our method with existing approaches across a multitask dataset, FedRouter demonstrate strong resilience in these challenging scenarios performing up to 6.1% relatively better under tasks interference and up to 136% relative improvement under generalization evaluation.
$f$-FUM: Federated Unlearning via min--max and $f$-divergence
Feb 05, 2026Federated Learning (FL) has emerged as a powerful paradigm for collaborative machine learning across decentralized data sources, preserving privacy by keeping data local. However, increasing legal and ethical demands, such as the "right to be forgotten", and the need to mitigate data poisoning attacks have underscored the urgent necessity for principled data unlearning in FL. Unlike centralized settings, the distributed nature of FL complicates the removal of individual data contributions. In this paper, we propose a novel federated unlearning framework formulated as a min-max optimization problem, where the objective is to maximize an $f$-divergence between the model trained with all data and the model retrained without specific data points, while minimizing the degradation on retained data. Our framework could act like a plugin and be added to almost any federated setup, unlike SOTA methods like (\cite{10269017} which requires model degradation in server, or \cite{khalil2025notfederatedunlearningweight} which requires to involve model architecture and model weights). This formulation allows for efficient approximation of data removal effects in a federated setting. We provide empirical evaluations to show that our method achieves significant speedups over naive retraining, with minimal impact on utility.
DES-LOC: Desynced Low Communication Adaptive Optimizers for Training Foundation Models
May 28, 2025Scaling foundation model training with Distributed Data Parallel (DDP) methods is bandwidth-limited. Existing infrequent communication methods like Local SGD were designed to synchronize only model parameters and cannot be trivially applied to adaptive optimizers due to additional optimizer states. Current approaches extending Local SGD either lack convergence guarantees or require synchronizing all optimizer states, tripling communication costs. We propose Desynced Low Communication Adaptive Optimizers (DES-LOC), a family of optimizers assigning independent synchronization periods to parameters and momenta, enabling lower communication costs while preserving convergence. Through extensive experiments on language models of up to 1.7B, we show that DES-LOC can communicate 170x less than DDP and 2x less than the previous state-of-the-art Local ADAM. Furthermore, unlike previous heuristic approaches, DES-LOC is suited for practical training scenarios prone to system failures. DES-LOC offers a scalable, bandwidth-efficient, and fault-tolerant solution for foundation model training.
Editing as Unlearning: Are Knowledge Editing Methods Strong Baselines for Large Language Model Unlearning?
May 26, 2025Large language Model (LLM) unlearning, i.e., selectively removing information from LLMs, is vital for responsible model deployment. Differently, LLM knowledge editing aims to modify LLM knowledge instead of removing it. Though editing and unlearning seem to be two distinct tasks, we find there is a tight connection between them. In this paper, we conceptualize unlearning as a special case of editing where information is modified to a refusal or "empty set" $\emptyset$ response, signifying its removal. This paper thus investigates if knowledge editing techniques are strong baselines for LLM unlearning. We evaluate state-of-the-art (SOTA) editing methods (e.g., ROME, MEMIT, GRACE, WISE, and AlphaEdit) against existing unlearning approaches on pretrained and finetuned knowledge. Results show certain editing methods, notably WISE and AlphaEdit, are effective unlearning baselines, especially for pretrained knowledge, and excel in generating human-aligned refusal answers. To better adapt editing methods for unlearning applications, we propose practical recipes including self-improvement and query merging. The former leverages the LLM's own in-context learning ability to craft a more human-aligned unlearning target, and the latter enables ROME and MEMIT to perform well in unlearning longer sample sequences. We advocate for the unlearning community to adopt SOTA editing methods as baselines and explore unlearning from an editing perspective for more holistic LLM memory control.
Bridge the Gaps between Machine Unlearning and AI Regulation
Feb 18, 2025The "right to be forgotten" and the data privacy laws that encode it have motivated machine unlearning since its earliest days. Now, an inbound wave of artificial intelligence regulations - like the European Union's Artificial Intelligence Act (AIA) - potentially offer important new use cases for machine unlearning. However, this position paper argues, this opportunity will only be realized if researchers, aided by policymakers, proactively bridge the (sometimes sizable) gaps between machine unlearning's state of the art and its potential applications to AI regulation. To demonstrate this point, we use the AIA as an example. Specifically, we deliver a "state of the union" as regards machine unlearning's current potential for aiding compliance with the AIA. This starts with a precise cataloging of the potential applications of machine unlearning to AIA compliance. For each, we flag any legal ambiguities clouding the potential application and, moreover, flag the technical gaps that exist between the potential application and the state of the art of machine unlearning. Finally, we end with a call to action: for both machine learning researchers and policymakers, to, respectively, solve the open technical and legal questions that will unlock machine unlearning's potential to assist compliance with the AIA - and other AI regulation like it.
LUNAR: LLM Unlearning via Neural Activation Redirection
Feb 11, 2025Large Language Models (LLMs) benefit from training on ever larger amounts of textual data, but as a result, they increasingly incur the risk of leaking private information. The ability to selectively remove knowledge from LLMs is, therefore, a highly desirable capability. In this paper, we propose LUNAR, a novel unlearning methodology grounded in the Linear Representation Hypothesis. LUNAR operates by redirecting the representations of unlearned data to regions that trigger the model's inherent ability to express its inability to answer. LUNAR achieves state-of-the-art unlearning performance while significantly enhancing the controllability of the unlearned model during inference. Specifically, LUNAR achieves between 2.9x to 11.7x improvements on combined "unlearning efficacy" and "model utility" score ("Deviation Score") on the PISTOL dataset across various base models. We also demonstrate, through quantitative analysis and qualitative examples, LUNAR's superior controllability in generating coherent and contextually aware responses, mitigating undesired side effects of existing methods. Moreover, we demonstrate that LUNAR is robust against white-box adversarial attacks and versatile in handling real-world scenarios, such as processing sequential unlearning requests.
DEPT: Decoupled Embeddings for Pre-training Language Models
Oct 07, 2024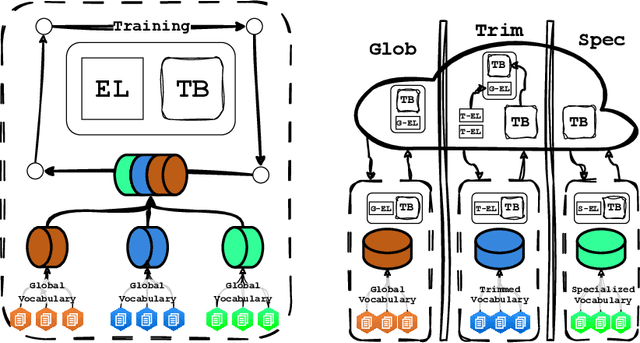
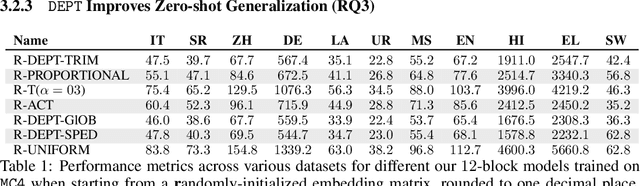


Language Model pre-training benefits from a broader data mixture to enhance performance across domains and languages. However, training on such heterogeneous text corpora is complex, requiring extensive and cost-intensive efforts. Since these data sources vary in lexical, syntactic, and semantic aspects, they cause negative interference or the "curse of multilinguality". We propose a novel pre-training framework to alleviate this curse. Our method, DEPT, decouples the embedding layers from the transformer body while simultaneously training the latter in multiple contexts. DEPT enables the model to train without being bound to a shared global vocabulary. DEPT: (1) can train robustly and effectively under significant data heterogeneity, (2) reduces the parameter count of the token embeddings by up to 80% and the communication costs by 675x for billion-scale models (3) enhances model generalization and plasticity in adapting to new languages and domains, and (4) allows training with custom optimized vocabulary per data source. We prove DEPT's potential by performing the first vocabulary-agnostic federated multilingual pre-training of a 1.3 billion-parameter model across high and low-resource languages, reducing its parameter count by 409 million.
Are we making progress in unlearning? Findings from the first NeurIPS unlearning competition
Jun 13, 2024



We present the findings of the first NeurIPS competition on unlearning, which sought to stimulate the development of novel algorithms and initiate discussions on formal and robust evaluation methodologies. The competition was highly successful: nearly 1,200 teams from across the world participated, and a wealth of novel, imaginative solutions with different characteristics were contributed. In this paper, we analyze top solutions and delve into discussions on benchmarking unlearning, which itself is a research problem. The evaluation methodology we developed for the competition measures forgetting quality according to a formal notion of unlearning, while incorporating model utility for a holistic evaluation. We analyze the effectiveness of different instantiations of this evaluation framework vis-a-vis the associated compute cost, and discuss implications for standardizing evaluation. We find that the ranking of leading methods remains stable under several variations of this framework, pointing to avenues for reducing the cost of evaluation. Overall, our findings indicate progress in unlearning, with top-performing competition entries surpassing existing algorithms under our evaluation framework. We analyze trade-offs made by different algorithms and strengths or weaknesses in terms of generalizability to new datasets, paving the way for advancing both benchmarking and algorithm development in this important area.
What makes unlearning hard and what to do about it
Jun 03, 2024Machine unlearning is the problem of removing the effect of a subset of training data (the ''forget set'') from a trained model without damaging the model's utility e.g. to comply with users' requests to delete their data, or remove mislabeled, poisoned or otherwise problematic data. With unlearning research still being at its infancy, many fundamental open questions exist: Are there interpretable characteristics of forget sets that substantially affect the difficulty of the problem? How do these characteristics affect different state-of-the-art algorithms? With this paper, we present the first investigation aiming to answer these questions. We identify two key factors affecting unlearning difficulty and the performance of unlearning algorithms. Evaluation on forget sets that isolate these identified factors reveals previously-unknown behaviours of state-of-the-art algorithms that don't materialize on random forget sets. Based on our insights, we develop a framework coined Refined-Unlearning Meta-algorithm (RUM) that encompasses: (i) refining the forget set into homogenized subsets, according to different characteristics; and (ii) a meta-algorithm that employs existing algorithms to unlearn each subset and finally delivers a model that has unlearned the overall forget set. We find that RUM substantially improves top-performing unlearning algorithms. Overall, we view our work as an important step in (i) deepening our scientific understanding of unlearning and (ii) revealing new pathways to improving the state-of-the-art.
Towards Unbounded Machine Unlearning
Feb 20, 2023Deep machine unlearning is the problem of removing the influence of a cohort of data from the weights of a trained deep model. This challenge is enjoying increasing attention due to the widespread use of neural networks in applications involving user data: allowing users to exercise their `right to be forgotten' necessitates an effective unlearning algorithm. However, deleting data from models is also of interest in practice for other applications where individual user privacy is not necessarily a consideration: removing biases, out-of-date examples, outliers, or noisy labels, and different such applications come with different desiderata. We propose a new unlearning algorithm (coined SCRUB) and conduct a comprehensive experimental evaluation against several previous state-of-the-art models. The results reveal that SCRUB is consistently a top performer across three different metrics for measuring unlearning quality, reflecting different application scenarios, while not degrading the model's performance.