 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoRDO: Distributed Low-Rank Optimization with Infrequent Communication
Feb 04, 2026Distributed training of foundation models via $\texttt{DDP}$ is limited by interconnect bandwidth. While infrequent communication strategies reduce synchronization frequency, they remain bottlenecked by the memory and communication requirements of optimizer states. Low-rank optimizers can alleviate these constraints; however, in the local-update regime, workers lack access to the full-batch gradients required to compute low-rank projections, which degrades performance. We propose $\texttt{LoRDO}$, a principled framework unifying low-rank optimization with infrequent synchronization. We first demonstrate that, while global projections based on pseudo-gradients are theoretically superior, they permanently restrict the optimization trajectory to a low-rank subspace. To restore subspace exploration, we introduce a full-rank quasi-hyperbolic update. $\texttt{LoRDO}$ achieves near-parity with low-rank $\texttt{DDP}$ in language modeling and downstream tasks at model scales of $125$M--$720$M, while reducing communication by $\approx 10 \times$. Finally, we show that $\texttt{LoRDO}$ improves performance even more in very low-memory settings with small rank/batch size.
DES-LOC: Desynced Low Communication Adaptive Optimizers for Training Foundation Models
May 28, 2025Scaling foundation model training with Distributed Data Parallel (DDP) methods is bandwidth-limited. Existing infrequent communication methods like Local SGD were designed to synchronize only model parameters and cannot be trivially applied to adaptive optimizers due to additional optimizer states. Current approaches extending Local SGD either lack convergence guarantees or require synchronizing all optimizer states, tripling communication costs. We propose Desynced Low Communication Adaptive Optimizers (DES-LOC), a family of optimizers assigning independent synchronization periods to parameters and momenta, enabling lower communication costs while preserving convergence. Through extensive experiments on language models of up to 1.7B, we show that DES-LOC can communicate 170x less than DDP and 2x less than the previous state-of-the-art Local ADAM. Furthermore, unlike previous heuristic approaches, DES-LOC is suited for practical training scenarios prone to system failures. DES-LOC offers a scalable, bandwidth-efficient, and fault-tolerant solution for foundation model training.
SparsyFed: Sparse Adaptive Federated Training
Apr 07, 2025Sparse training is often adopted in cross-device federated learning (FL) environments where constrained devices collaboratively train a machine learning model on private data by exchanging pseudo-gradients across heterogeneous networks. Although sparse training methods can reduce communication overhead and computational burden in FL, they are often not used in practice for the following key reasons: (1) data heterogeneity makes it harder for clients to reach consensus on sparse models compared to dense ones, requiring longer training; (2) methods for obtaining sparse masks lack adaptivity to accommodate very heterogeneous data distributions, crucial in cross-device FL; and (3) additional hyperparameters are required, which are notably challenging to tune in FL. This paper presents SparsyFed, a practical federated sparse training method that critically addresses the problems above. Previous works have only solved one or two of these challenges at the expense of introducing new trade-offs, such as clients' consensus on masks versus sparsity pattern adaptivity. We show that SparsyFed simultaneously (1) can produce 95% sparse models, with negligible degradation in accuracy, while only needing a single hyperparameter, (2) achieves a per-round weight regrowth 200 times smaller than previous methods, and (3) allows the sparse masks to adapt to highly heterogeneous data distributions and outperform all baselines under such conditions.
LUNAR: LLM Unlearning via Neural Activation Redirection
Feb 11, 2025Large Language Models (LLMs) benefit from training on ever larger amounts of textual data, but as a result, they increasingly incur the risk of leaking private information. The ability to selectively remove knowledge from LLMs is, therefore, a highly desirable capability. In this paper, we propose LUNAR, a novel unlearning methodology grounded in the Linear Representation Hypothesis. LUNAR operates by redirecting the representations of unlearned data to regions that trigger the model's inherent ability to express its inability to answer. LUNAR achieves state-of-the-art unlearning performance while significantly enhancing the controllability of the unlearned model during inference. Specifically, LUNAR achieves between 2.9x to 11.7x improvements on combined "unlearning efficacy" and "model utility" score ("Deviation Score") on the PISTOL dataset across various base models. We also demonstrate, through quantitative analysis and qualitative examples, LUNAR's superior controllability in generating coherent and contextually aware responses, mitigating undesired side effects of existing methods. Moreover, we demonstrate that LUNAR is robust against white-box adversarial attacks and versatile in handling real-world scenarios, such as processing sequential unlearning requests.
Photon: Federated LLM Pre-Training
Nov 05, 2024



Scaling large language models (LLMs) demands extensive data and computing resources, which are traditionally constrained to data centers by the high-bandwidth requirements of distributed training. Low-bandwidth methods like federated learning (FL) could enable collaborative training of larger models across weakly-connected GPUs if they can effectively be used for pre-training. To achieve this, we introduce Photon, the first complete system for federated end-to-end LLM training, leveraging cross-silo FL for global-scale training with minimal communication overheads. Using Photon, we train the first federated family of decoder-only LLMs from scratch. We show that: (1) Photon can train model sizes up to 7B in a federated fashion while reaching an even better perplexity than centralized pre-training; (2) Photon model training time decreases with available compute, achieving a similar compute-time trade-off to centralized; and (3) Photon outperforms the wall-time of baseline distributed training methods by 35% via communicating 64x-512xless. Our proposal is robust to data heterogeneity and converges twice as fast as previous methods like DiLoCo. This surprising data efficiency stems from a unique approach combining small client batch sizes with extremely high learning rates, enabled by federated averaging's robustness to hyperparameters. Photon thus represents the first economical system for global internet-wide LLM pre-training.
DEPT: Decoupled Embeddings for Pre-training Language Models
Oct 07, 2024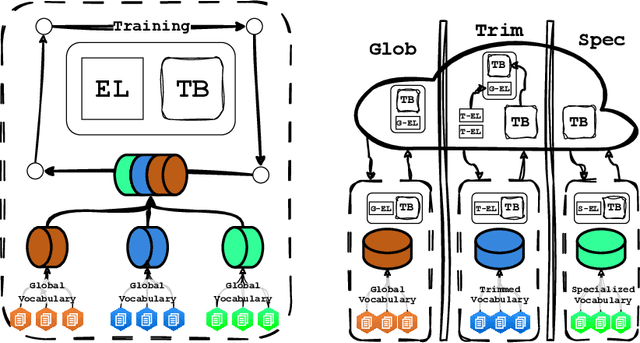
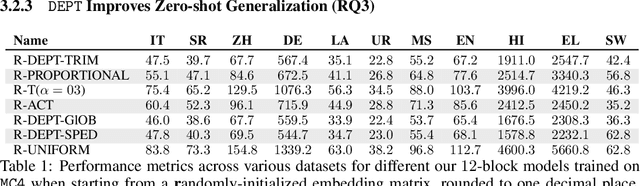


Language Model pre-training benefits from a broader data mixture to enhance performance across domains and languages. However, training on such heterogeneous text corpora is complex, requiring extensive and cost-intensive efforts. Since these data sources vary in lexical, syntactic, and semantic aspects, they cause negative interference or the "curse of multilinguality". We propose a novel pre-training framework to alleviate this curse. Our method, DEPT, decouples the embedding layers from the transformer body while simultaneously training the latter in multiple contexts. DEPT enables the model to train without being bound to a shared global vocabulary. DEPT: (1) can train robustly and effectively under significant data heterogeneity, (2) reduces the parameter count of the token embeddings by up to 80% and the communication costs by 675x for billion-scale models (3) enhances model generalization and plasticity in adapting to new languages and domains, and (4) allows training with custom optimized vocabulary per data source. We prove DEPT's potential by performing the first vocabulary-agnostic federated multilingual pre-training of a 1.3 billion-parameter model across high and low-resource languages, reducing its parameter count by 409 million.
Worldwide Federated Training of Language Models
May 23, 2024



The reliance of language model training on massive amounts of computation and vast datasets scraped from potentially low-quality, copyrighted, or sensitive data has come into question practically, legally, and ethically. Federated learning provides a plausible alternative by enabling previously untapped data to be voluntarily gathered from collaborating organizations. However, when scaled globally, federated learning requires collaboration across heterogeneous legal, security, and privacy regimes while accounting for the inherent locality of language data; this further exacerbates the established challenge of federated statistical heterogeneity. We propose a Worldwide Federated Language Model Training~(WorldLM) system based on federations of federations, where each federation has the autonomy to account for factors such as its industry, operating jurisdiction, or competitive environment. WorldLM enables such autonomy in the presence of statistical heterogeneity via partial model localization by allowing sub-federations to attentively aggregate key layers from their constituents. Furthermore, it can adaptively share information across federations via residual layer embeddings. Evaluations of language modeling on naturally heterogeneous datasets show that WorldLM outperforms standard federations by up to $1.91\times$, approaches the personalized performance of fully local models, and maintains these advantages under privacy-enhancing techniques.
The Future of Large Language Model Pre-training is Federated
May 17, 2024



Generative pre-trained large language models (LLMs) have demonstrated impressive performance over a wide range of tasks, thanks to the unprecedented amount of data they have been trained on. As established scaling laws indicate, LLMs' future performance improvement depends on the amount of computing and data sources we can leverage for pre-training. Federated learning (FL) has the potential to unleash the majority of the planet's data and computational resources, which are underutilized by the data-center-focused training methodology of current LLM practice. Our work presents a robust, flexible, reproducible FL approach that enables large-scale collaboration across institutions to train LLMs. This would mobilize more computational and data resources while matching or potentially exceeding centralized performance. We further show the effectiveness of the federated training scales with model size and present our approach for training a billion-scale federated LLM using limited resources. This will help data-rich actors to become the protagonists of LLMs pre-training instead of leaving the stage to compute-rich actors alone.
FedAnchor: Enhancing Federated Semi-Supervised Learning with Label Contrastive Loss for Unlabeled Clients
Feb 15, 2024Federated learning (FL) is a distributed learning paradigm that facilitates collaborative training of a shared global model across devices while keeping data localized. The deployment of FL in numerous real-world applications faces delays, primarily due to the prevalent reliance on supervised tasks. Generating detailed labels at edge devices, if feasible, is demanding, given resource constraints and the imperative for continuous data updates. In addressing these challenges, solutions such as federated semi-supervised learning (FSSL), which relies on unlabeled clients' data and a limited amount of labeled data on the server, become pivotal. In this paper, we propose FedAnchor, an innovative FSSL method that introduces a unique double-head structure, called anchor head, paired with the classification head trained exclusively on labeled anchor data on the server. The anchor head is empowered with a newly designed label contrastive loss based on the cosine similarity metric. Our approach mitigates the confirmation bias and overfitting issues associated with pseudo-labeling techniques based on high-confidence model prediction samples. Extensive experiments on CIFAR10/100 and SVHN datasets demonstrate that our method outperforms the state-of-the-art method by a significant margin in terms of convergence rate and model accuracy.
Privacy in Multimodal Federated Human Activity Recognition
May 20, 2023



Human Activity Recognition (HAR) training data is often privacy-sensitive or held by non-cooperative entities. Federated Learning (FL) addresses such concerns by training ML models on edge clients. This work studies the impact of privacy in federated HAR at a user, environment, and sensor level. We show that the performance of FL for HAR depends on the assumed privacy level of the FL system and primarily upon the colocation of data from different sensors. By avoiding data sharing and assuming privacy at the human or environment level, as prior works have done, the accuracy decreases by 5-7%. However, extending this to the modality level and strictly separating sensor data between multiple clients may decrease the accuracy by 19-42%. As this form of privacy is necessary for the ethical utilisation of passive sensing methods in HAR, we implement a system where clients mutually train both a general FL model and a group-level one per modality. Our evaluation shows that this method leads to only a 7-13% decrease in accuracy, making it possible to build HAR systems with diverse hardware.