 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFollow-Your-Emoji: Fine-Controllable and Expressive Freestyle Portrait Animation
Jun 04, 2024



We present Follow-Your-Emoji, a diffusion-based framework for portrait animation, which animates a reference portrait with target landmark sequences. The main challenge of portrait animation is to preserve the identity of the reference portrait and transfer the target expression to this portrait while maintaining temporal consistency and fidelity. To address these challenges, Follow-Your-Emoji equipped the powerful Stable Diffusion model with two well-designed technologies. Specifically, we first adopt a new explicit motion signal, namely expression-aware landmark, to guide the animation process. We discover this landmark can not only ensure the accurate motion alignment between the reference portrait and target motion during inference but also increase the ability to portray exaggerated expressions (i.e., large pupil movements) and avoid identity leakage. Then, we propose a facial fine-grained loss to improve the model's ability of subtle expression perception and reference portrait appearance reconstruction by using both expression and facial masks. Accordingly, our method demonstrates significant performance in controlling the expression of freestyle portraits, including real humans, cartoons, sculptures, and even animals. By leveraging a simple and effective progressive generation strategy, we extend our model to stable long-term animation, thus increasing its potential application value. To address the lack of a benchmark for this field, we introduce EmojiBench, a comprehensive benchmark comprising diverse portrait images, driving videos, and landmarks. We show extensive evaluations on EmojiBench to verify the superiority of Follow-Your-Emoji.
FedAnchor: Enhancing Federated Semi-Supervised Learning with Label Contrastive Loss for Unlabeled Clients
Feb 15, 2024Federated learning (FL) is a distributed learning paradigm that facilitates collaborative training of a shared global model across devices while keeping data localized. The deployment of FL in numerous real-world applications faces delays, primarily due to the prevalent reliance on supervised tasks. Generating detailed labels at edge devices, if feasible, is demanding, given resource constraints and the imperative for continuous data updates. In addressing these challenges, solutions such as federated semi-supervised learning (FSSL), which relies on unlabeled clients' data and a limited amount of labeled data on the server, become pivotal. In this paper, we propose FedAnchor, an innovative FSSL method that introduces a unique double-head structure, called anchor head, paired with the classification head trained exclusively on labeled anchor data on the server. The anchor head is empowered with a newly designed label contrastive loss based on the cosine similarity metric. Our approach mitigates the confirmation bias and overfitting issues associated with pseudo-labeling techniques based on high-confidence model prediction samples. Extensive experiments on CIFAR10/100 and SVHN datasets demonstrate that our method outperforms the state-of-the-art method by a significant margin in terms of convergence rate and model accuracy.
vFedSec: Efficient Secure Aggregation for Vertical Federated Learning via Secure Layer
May 26, 2023Most work in privacy-preserving federated learning (FL) has been focusing on horizontally partitioned datasets where clients share the same sets of features and can train complete models independently. However, in many interesting problems, individual data points are scattered across different clients/organizations in a vertical setting. Solutions for this type of FL require the exchange of intermediate outputs and gradients between participants, posing a potential risk of privacy leakage when privacy and security concerns are not considered. In this work, we present vFedSec - a novel design with an innovative Secure Layer for training vertical FL securely and efficiently using state-of-the-art security modules in secure aggregation. We theoretically demonstrate that our method does not impact the training performance while protecting private data effectively. Empirically results also show its applicability with extensive experiments that our design can achieve the protection with negligible computation and communication overhead. Also, our method can obtain 9.1e2 ~ 3.8e4 speedup compared to widely-adopted homomorphic encryption (HE) method.
Efficient Vertical Federated Learning with Secure Aggregation
May 18, 2023



The majority of work in privacy-preserving federated learning (FL) has been focusing on horizontally partitioned datasets where clients share the same sets of features and can train complete models independently. However, in many interesting problems, such as financial fraud detection and disease detection, individual data points are scattered across different clients/organizations in vertical federated learning. Solutions for this type of FL require the exchange of gradients between participants and rarely consider privacy and security concerns, posing a potential risk of privacy leakage. In this work, we present a novel design for training vertical FL securely and efficiently using state-of-the-art security modules for secure aggregation. We demonstrate empirically that our method does not impact training performance whilst obtaining 9.1e2 ~3.8e4 speedup compared to homomorphic encryption (HE).
Img2Vec: A Teacher of High Token-Diversity Helps Masked AutoEncoders
Apr 25, 2023We present a pipeline of Image to Vector (Img2Vec) for masked image modeling (MIM) with deep features. To study which type of deep features is appropriate for MIM as a learning target, we propose a simple MIM framework with serials of well-trained self-supervised models to convert an Image to a feature Vector as the learning target of MIM, where the feature extractor is also known as a teacher model. Surprisingly, we empirically find that an MIM model benefits more from image features generated by some lighter models (e.g., ResNet-50, 26M) than from those by a cumbersome teacher like Transformer-based models (e.g., ViT-Large, 307M). To analyze this remarkable phenomenon, we devise a novel attribute, token diversity, to evaluate the characteristics of generated features from different models. Token diversity measures the feature dissimilarity among different tokens. Through extensive experiments and visualizations, we hypothesize that beyond the acknowledgment that a large model can improve MIM, a high token-diversity of a teacher model is also crucial. Based on the above discussion, Img2Vec adopts a teacher model with high token-diversity to generate image features. Img2Vec pre-trained on ImageNet unlabeled data with ViT-B yields 85.1\% top-1 accuracy on fine-tuning. Moreover, we scale up Img2Vec on larger models, ViT-L and ViT-H, and get $86.7\%$ and $87.5\%$ accuracy respectively. It also achieves state-of-the-art results on other downstream tasks, e.g., 51.8\% mAP on COCO and 50.7\% mIoU on ADE20K. Img2Vec is a simple yet effective framework tailored to deep feature MIM learning, accomplishing superb comprehensive performance on representative vision tasks.
Attacking Adversarial Attacks as A Defense
Jun 09, 2021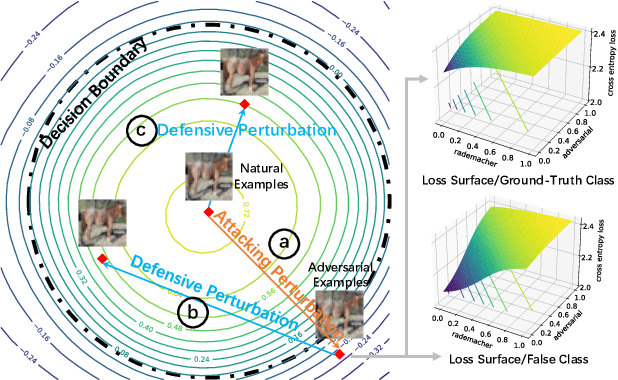

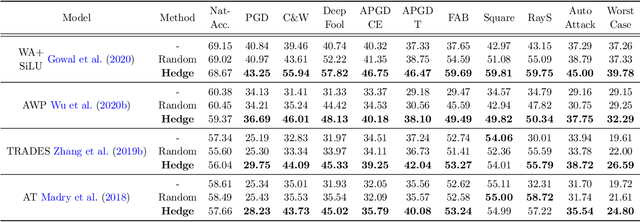
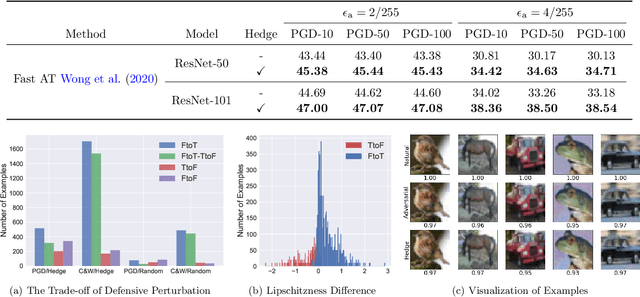
It is well known that adversarial attacks can fool deep neural networks with imperceptible perturbations. Although adversarial training significantly improves model robustness, failure cases of defense still broadly exist. In this work, we find that the adversarial attacks can also be vulnerable to small perturbations. Namely, on adversarially-trained models, perturbing adversarial examples with a small random noise may invalidate their misled predictions. After carefully examining state-of-the-art attacks of various kinds, we find that all these attacks have this deficiency to different extents. Enlightened by this finding, we propose to counter attacks by crafting more effective defensive perturbations. Our defensive perturbations leverage the advantage that adversarial training endows the ground-truth class with smaller local Lipschitzness. By simultaneously attacking all the classes, the misled predictions with larger Lipschitzness can be flipped into correct ones. We verify our defensive perturbation with both empirical experiments and theoretical analyses on a linear model. On CIFAR10, it boosts the state-of-the-art model from 66.16% to 72.66% against the four attacks of AutoAttack, including 71.76% to 83.30% against the Square attack. On ImageNet, the top-1 robust accuracy of FastAT is improved from 33.18% to 38.54% under the 100-step PGD attack.
Cloud Removal for Remote Sensing Imagery via Spatial Attention Generative Adversarial Network
Sep 28, 2020
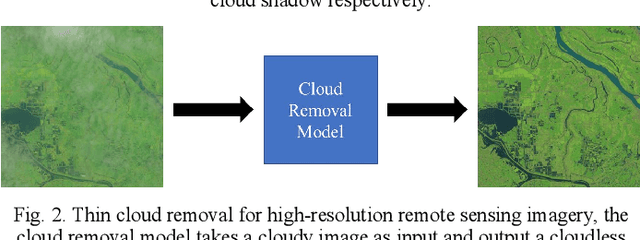
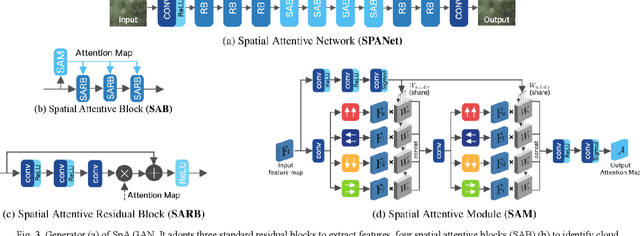

Optical remote sensing imagery has been widely used in many fields due to its high resolution and stable geometric properties. However, remote sensing imagery is inevitably affected by climate, especially clouds. Removing the cloud in the high-resolution remote sensing satellite image is an indispensable pre-processing step before analyzing it. For the sake of large-scale training data, neural networks have been successful in many image processing tasks, but the use of neural networks to remove cloud in remote sensing imagery is still relatively small. We adopt generative adversarial network to solve this task and introduce the spatial attention mechanism into the remote sensing imagery cloud removal task, proposes a model named spatial attention generative adversarial network (SpA GAN), which imitates the human visual mechanism, and recognizes and focuses the cloud area with local-to-global spatial attention, thereby enhancing the information recovery of these areas and generating cloudless images with better quality...