 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStep 3.5 Flash: Open Frontier-Level Intelligence with 11B Active Parameters
Feb 11, 2026We introduce Step 3.5 Flash, a sparse Mixture-of-Experts (MoE) model that bridges frontier-level agentic intelligence and computational efficiency. We focus on what matters most when building agents: sharp reasoning and fast, reliable execution. Step 3.5 Flash pairs a 196B-parameter foundation with 11B active parameters for efficient inference. It is optimized with interleaved 3:1 sliding-window/full attention and Multi-Token Prediction (MTP-3) to reduce the latency and cost of multi-round agentic interactions. To reach frontier-level intelligence, we design a scalable reinforcement learning framework that combines verifiable signals with preference feedback, while remaining stable under large-scale off-policy training, enabling consistent self-improvement across mathematics, code, and tool use. Step 3.5 Flash demonstrates strong performance across agent, coding, and math tasks, achieving 85.4% on IMO-AnswerBench, 86.4% on LiveCodeBench-v6 (2024.08-2025.05), 88.2% on tau2-Bench, 69.0% on BrowseComp (with context management), and 51.0% on Terminal-Bench 2.0, comparable to frontier models such as GPT-5.2 xHigh and Gemini 3.0 Pro. By redefining the efficiency frontier, Step 3.5 Flash provides a high-density foundation for deploying sophisticated agents in real-world industrial environments.
SWE-AGI: Benchmarking Specification-Driven Software Construction with MoonBit in the Era of Autonomous Agents
Feb 11, 2026Although large language models (LLMs) have demonstrated impressive coding capabilities, their ability to autonomously build production-scale software from explicit specifications remains an open question. We introduce SWE-AGI, an open-source benchmark for evaluating end-to-end, specification-driven construction of software systems written in MoonBit. SWE-AGI tasks require LLM-based agents to implement parsers, interpreters, binary decoders, and SAT solvers strictly from authoritative standards and RFCs under a fixed API scaffold. Each task involves implementing 1,000-10,000 lines of core logic, corresponding to weeks or months of engineering effort for an experienced human developer. By leveraging the nascent MoonBit ecosystem, SWE-AGI minimizes data leakage, forcing agents to rely on long-horizon architectural reasoning rather than code retrieval. Across frontier models, gpt-5.3-codex achieves the best overall performance (solving 19/22 tasks, 86.4%), outperforming claude-opus-4.6 (15/22, 68.2%), and kimi-2.5 exhibits the strongest performance among open-source models. Performance degrades sharply with increasing task difficulty, particularly on hard, specification-intensive systems. Behavioral analysis further reveals that as codebases scale, code reading, rather than writing, becomes the dominant bottleneck in AI-assisted development. Overall, while specification-driven autonomous software engineering is increasingly viable, substantial challenges remain before it can reliably support production-scale development.
PaCoRe: Learning to Scale Test-Time Compute with Parallel Coordinated Reasoning
Jan 09, 2026We introduce Parallel Coordinated Reasoning (PaCoRe), a training-and-inference framework designed to overcome a central limitation of contemporary language models: their inability to scale test-time compute (TTC) far beyond sequential reasoning under a fixed context window. PaCoRe departs from the traditional sequential paradigm by driving TTC through massive parallel exploration coordinated via a message-passing architecture in multiple rounds. Each round launches many parallel reasoning trajectories, compacts their findings into context-bounded messages, and synthesizes these messages to guide the next round and ultimately produce the final answer. Trained end-to-end with large-scale, outcome-based reinforcement learning, the model masters the synthesis abilities required by PaCoRe and scales to multi-million-token effective TTC without exceeding context limits. The approach yields strong improvements across diverse domains, and notably pushes reasoning beyond frontier systems in mathematics: an 8B model reaches 94.5% on HMMT 2025, surpassing GPT-5's 93.2% by scaling effective TTC to roughly two million tokens. We open-source model checkpoints, training data, and the full inference pipeline to accelerate follow-up work.
Qwen-Image-Layered: Towards Inherent Editability via Layer Decomposition
Dec 17, 2025Recent visual generative models often struggle with consistency during image editing due to the entangled nature of raster images, where all visual content is fused into a single canvas. In contrast, professional design tools employ layered representations, allowing isolated edits while preserving consistency. Motivated by this, we propose \textbf{Qwen-Image-Layered}, an end-to-end diffusion model that decomposes a single RGB image into multiple semantically disentangled RGBA layers, enabling \textbf{inherent editability}, where each RGBA layer can be independently manipulated without affecting other content. To support variable-length decomposition, we introduce three key components: (1) an RGBA-VAE to unify the latent representations of RGB and RGBA images; (2) a VLD-MMDiT (Variable Layers Decomposition MMDiT) architecture capable of decomposing a variable number of image layers; and (3) a Multi-stage Training strategy to adapt a pretrained image generation model into a multilayer image decomposer. Furthermore, to address the scarcity of high-quality multilayer training images, we build a pipeline to extract and annotate multilayer images from Photoshop documents (PSD). Experiments demonstrate that our method significantly surpasses existing approaches in decomposition quality and establishes a new paradigm for consistent image editing. Our code and models are released on \href{https://github.com/QwenLM/Qwen-Image-Layered}{https://github.com/QwenLM/Qwen-Image-Layered}
Training-Free Text-Guided Color Editing with Multi-Modal Diffusion Transformer
Aug 12, 2025

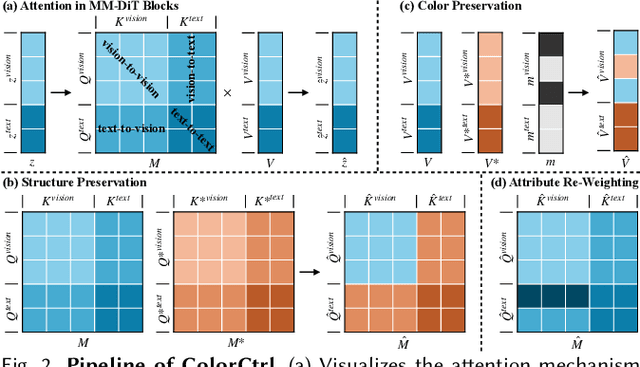
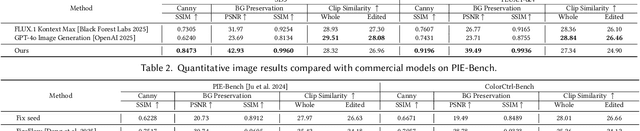
Text-guided color editing in images and videos is a fundamental yet unsolved problem, requiring fine-grained manipulation of color attributes, including albedo, light source color, and ambient lighting, while preserving physical consistency in geometry, material properties, and light-matter interactions. Existing training-free methods offer broad applicability across editing tasks but struggle with precise color control and often introduce visual inconsistency in both edited and non-edited regions. In this work, we present ColorCtrl, a training-free color editing method that leverages the attention mechanisms of modern Multi-Modal Diffusion Transformers (MM-DiT). By disentangling structure and color through targeted manipulation of attention maps and value tokens, our method enables accurate and consistent color editing, along with word-level control of attribute intensity. Our method modifies only the intended regions specified by the prompt, leaving unrelated areas untouched. Extensive experiments on both SD3 and FLUX.1-dev demonstrate that ColorCtrl outperforms existing training-free approaches and achieves state-of-the-art performances in both edit quality and consistency. Furthermore, our method surpasses strong commercial models such as FLUX.1 Kontext Max and GPT-4o Image Generation in terms of consistency. When extended to video models like CogVideoX, our approach exhibits greater advantages, particularly in maintaining temporal coherence and editing stability. Finally, our method also generalizes to instruction-based editing diffusion models such as Step1X-Edit and FLUX.1 Kontext dev, further demonstrating its versatility.
Step-Audio 2 Technical Report
Jul 24, 2025



This paper presents Step-Audio 2, an end-to-end multi-modal large language model designed for industry-strength audio understanding and speech conversation. By integrating a latent audio encoder and reasoning-centric reinforcement learning (RL), Step-Audio 2 achieves promising performance in automatic speech recognition (ASR) and audio understanding. To facilitate genuine end-to-end speech conversation, Step-Audio 2 incorporates the generation of discrete audio tokens into language modeling, significantly enhancing its responsiveness to paralinguistic information such as speaking styles and emotions. To effectively leverage the rich textual and acoustic knowledge in real-world data, Step-Audio 2 integrates retrieval-augmented generation (RAG) and is able to call external tools such as web search to mitigate hallucination and audio search to switch timbres. Trained on millions of hours of speech and audio data, Step-Audio 2 delivers intelligence and expressiveness across diverse conversational scenarios. Evaluation results demonstrate that Step-Audio 2 achieves state-of-the-art performance on various audio understanding and conversational benchmarks compared to other open-source and commercial solutions. Please visit https://github.com/stepfun-ai/Step-Audio2 for more information.
Step-Audio-AQAA: a Fully End-to-End Expressive Large Audio Language Model
Jun 10, 2025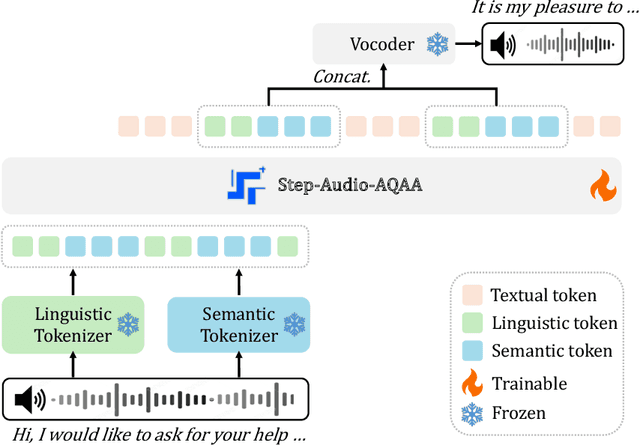
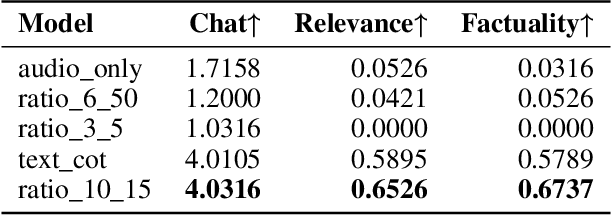
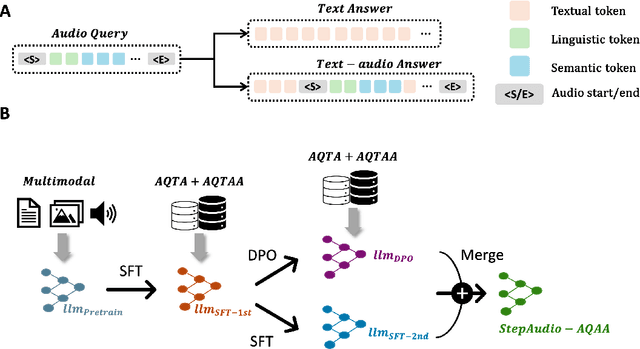

Large Audio-Language Models (LALMs) have significantly advanced intelligent human-computer interaction, yet their reliance on text-based outputs limits their ability to generate natural speech responses directly, hindering seamless audio interactions. To address this, we introduce Step-Audio-AQAA, a fully end-to-end LALM designed for Audio Query-Audio Answer (AQAA) tasks. The model integrates a dual-codebook audio tokenizer for linguistic and semantic feature extraction, a 130-billion-parameter backbone LLM and a neural vocoder for high-fidelity speech synthesis. Our post-training approach employs interleaved token-output of text and audio to enhance semantic coherence and combines Direct Preference Optimization (DPO) with model merge to improve performance. Evaluations on the StepEval-Audio-360 benchmark demonstrate that Step-Audio-AQAA excels especially in speech control, outperforming the state-of-art LALMs in key areas. This work contributes a promising solution for end-to-end LALMs and highlights the critical role of token-based vocoder in enhancing overall performance for AQAA tasks.
Open-Reasoner-Zero: An Open Source Approach to Scaling Up Reinforcement Learning on the Base Model
Mar 31, 2025



We introduce Open-Reasoner-Zero, the first open source implementation of large-scale reasoning-oriented RL training focusing on scalability, simplicity and accessibility. Through extensive experiments, we demonstrate that a minimalist approach, vanilla PPO with GAE ($\lambda=1$, $\gamma=1$) and straightforward rule-based rewards, without any KL regularization, is sufficient to scale up both response length and benchmark performance, similar to the phenomenon observed in DeepSeek-R1-Zero. Using the same base model as DeepSeek-R1-Zero-Qwen-32B, our implementation achieves superior performance on AIME2024, MATH500, and the GPQA Diamond benchmark while demonstrating remarkable efficiency -- requiring only a tenth of the training steps, compared to DeepSeek-R1-Zero pipeline. In the spirit of open source, we release our source code, parameter settings, training data, and model weights across various sizes.
Step-Video-TI2V Technical Report: A State-of-the-Art Text-Driven Image-to-Video Generation Model
Mar 14, 2025We present Step-Video-TI2V, a state-of-the-art text-driven image-to-video generation model with 30B parameters, capable of generating videos up to 102 frames based on both text and image inputs. We build Step-Video-TI2V-Eval as a new benchmark for the text-driven image-to-video task and compare Step-Video-TI2V with open-source and commercial TI2V engines using this dataset. Experimental results demonstrate the state-of-the-art performance of Step-Video-TI2V in the image-to-video generation task. Both Step-Video-TI2V and Step-Video-TI2V-Eval are available at https://github.com/stepfun-ai/Step-Video-TI2V.
Step-Audio: Unified Understanding and Generation in Intelligent Speech Interaction
Feb 18, 2025Real-time speech interaction, serving as a fundamental interface for human-machine collaboration, holds immense potential. However, current open-source models face limitations such as high costs in voice data collection, weakness in dynamic control, and limited intelligence. To address these challenges, this paper introduces Step-Audio, the first production-ready open-source solution. Key contributions include: 1) a 130B-parameter unified speech-text multi-modal model that achieves unified understanding and generation, with the Step-Audio-Chat version open-sourced; 2) a generative speech data engine that establishes an affordable voice cloning framework and produces the open-sourced lightweight Step-Audio-TTS-3B model through distillation; 3) an instruction-driven fine control system enabling dynamic adjustments across dialects, emotions, singing, and RAP; 4) an enhanced cognitive architecture augmented with tool calling and role-playing abilities to manage complex tasks effectively. Based on our new StepEval-Audio-360 evaluation benchmark, Step-Audio achieves state-of-the-art performance in human evaluations, especially in terms of instruction following. On open-source benchmarks like LLaMA Question, shows 9.3% average performance improvement, demonstrating our commitment to advancing the development of open-source multi-modal language technologies. Our code and models are available at https://github.com/stepfun-ai/Step-Audio.