 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMVU-Eval: Towards Multi-Video Understanding Evaluation for Multimodal LLMs
Nov 13, 2025
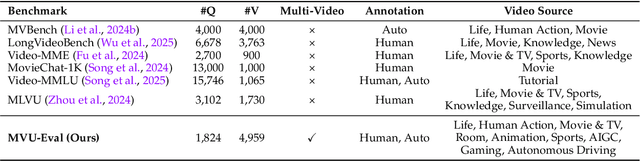
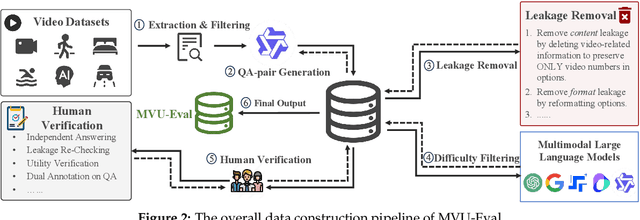

The advent of Multimodal Large Language Models (MLLMs) has expanded AI capabilities to visual modalities, yet existing evaluation benchmarks remain limited to single-video understanding, overlooking the critical need for multi-video understanding in real-world scenarios (e.g., sports analytics and autonomous driving). To address this significant gap, we introduce MVU-Eval, the first comprehensive benchmark for evaluating Multi-Video Understanding for MLLMs. Specifically, our MVU-Eval mainly assesses eight core competencies through 1,824 meticulously curated question-answer pairs spanning 4,959 videos from diverse domains, addressing both fundamental perception tasks and high-order reasoning tasks. These capabilities are rigorously aligned with real-world applications such as multi-sensor synthesis in autonomous systems and cross-angle sports analytics. Through extensive evaluation of state-of-the-art open-source and closed-source models, we reveal significant performance discrepancies and limitations in current MLLMs' ability to perform understanding across multiple videos. The benchmark will be made publicly available to foster future research.
Can Mixture-of-Experts Surpass Dense LLMs Under Strictly Equal Resources?
Jun 13, 2025Mixture-of-Experts (MoE) language models dramatically expand model capacity and achieve remarkable performance without increasing per-token compute. However, can MoEs surpass dense architectures under strictly equal resource constraints - that is, when the total parameter count, training compute, and data budget are identical? This question remains under-explored despite its significant practical value and potential. In this paper, we propose a novel perspective and methodological framework to study this question thoroughly. First, we comprehensively investigate the architecture of MoEs and achieve an optimal model design that maximizes the performance. Based on this, we subsequently find that an MoE model with activation rate in an optimal region is able to outperform its dense counterpart under the same total parameter, training compute and data resource. More importantly, this optimal region remains consistent across different model sizes. Although additional amount of data turns out to be a trade-off for the enhanced performance, we show that this can be resolved via reusing data. We validate our findings through extensive experiments, training nearly 200 language models at 2B scale and over 50 at 7B scale, cumulatively processing 50 trillion tokens. All models will be released publicly.
Farseer: A Refined Scaling Law in Large Language Models
Jun 12, 2025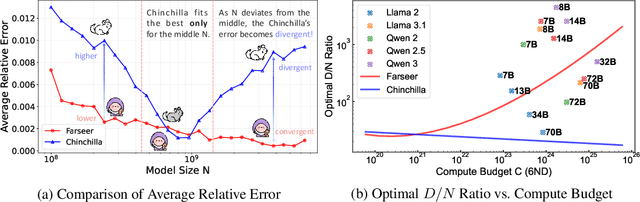
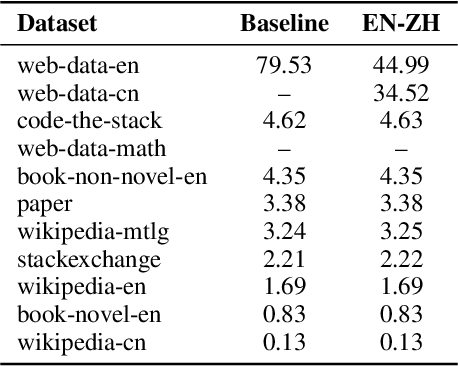
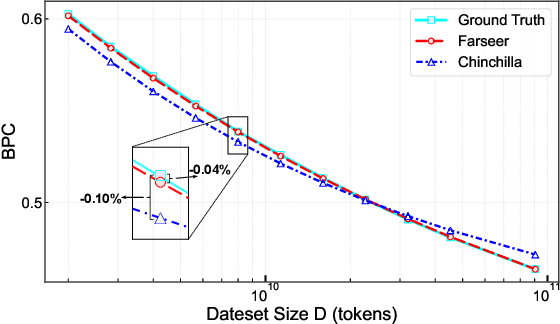

Training Large Language Models (LLMs) is prohibitively expensive, creating a critical scaling gap where insights from small-scale experiments often fail to transfer to resource-intensive production systems, thereby hindering efficient innovation. To bridge this, we introduce Farseer, a novel and refined scaling law offering enhanced predictive accuracy across scales. By systematically constructing a model loss surface $L(N,D)$, Farseer achieves a significantly better fit to empirical data than prior laws (e.g., Chinchilla's law). Our methodology yields accurate, robust, and highly generalizable predictions, demonstrating excellent extrapolation capabilities, improving upon Chinchilla's law by reducing extrapolation error by 433\%. This allows for the reliable evaluation of competing training strategies across all $(N,D)$ settings, enabling conclusions from small-scale ablation studies to be confidently extrapolated to predict large-scale performance. Furthermore, Farseer provides new insights into optimal compute allocation, better reflecting the nuanced demands of modern LLM training. To validate our approach, we trained an extensive suite of approximately 1,000 LLMs across diverse scales and configurations, consuming roughly 3 million NVIDIA H100 GPU hours. We are comprehensively open-sourcing all models, data, results, and logs at https://github.com/Farseer-Scaling-Law/Farseer to foster further research.
Is Compression Really Linear with Code Intelligence?
May 16, 2025



Understanding the relationship between data compression and the capabilities of Large Language Models (LLMs) is crucial, especially in specialized domains like code intelligence. Prior work posited a linear relationship between compression and general intelligence. However, it overlooked the multifaceted nature of code that encompasses diverse programming languages and tasks, and struggled with fair evaluation of modern Code LLMs. We address this by evaluating a diverse array of open-source Code LLMs on comprehensive multi-language, multi-task code benchmarks. To address the challenge of efficient and fair evaluation of pre-trained LLMs' code intelligence, we introduce \textit{Format Annealing}, a lightweight, transparent training methodology designed to assess the intrinsic capabilities of these pre-trained models equitably. Compression efficacy, measured as bits-per-character (BPC), is determined using a novel, large-scale, and previously unseen code validation set derived from GitHub. Our empirical results reveal a fundamental logarithmic relationship between measured code intelligence and BPC. This finding refines prior hypotheses of linearity, which we suggest are likely observations of the logarithmic curve's tail under specific, limited conditions. Our work provides a more nuanced understanding of compression's role in developing code intelligence and contributes a robust evaluation framework in the code domain.
Predictable Scale: Part I -- Optimal Hyperparameter Scaling Law in Large Language Model Pretraining
Mar 06, 2025The impressive capabilities of Large Language Models (LLMs) across diverse tasks are now well-established, yet their effective deployment necessitates careful hyperparameter optimization. Through extensive empirical studies involving grid searches across diverse configurations, we discover universal scaling laws governing these hyperparameters: optimal learning rate follows a power-law relationship with both model parameters and data sizes, while optimal batch size scales primarily with data sizes. Our analysis reveals a convex optimization landscape for hyperparameters under fixed models and data size conditions. This convexity implies an optimal hyperparameter plateau. We contribute a universal, plug-and-play optimal hyperparameter tool for the community. Its estimated values on the test set are merely 0.07\% away from the globally optimal LLM performance found via an exhaustive search. These laws demonstrate remarkable robustness across variations in model sparsity, training data distribution, and model shape. To our best known, this is the first work that unifies different model shapes and structures, such as Mixture-of-Experts models and dense transformers, as well as establishes optimal hyperparameter scaling laws across diverse data distributions. This exhaustive optimization process demands substantial computational resources, utilizing nearly one million NVIDIA H800 GPU hours to train 3,700 LLMs of varying sizes and hyperparameters from scratch and consuming approximately 100 trillion tokens in total. To facilitate reproducibility and further research, we will progressively release all loss measurements and model checkpoints through our designated repository https://step-law.github.io/
Multi-matrix Factorization Attention
Dec 26, 2024



We propose novel attention architectures, Multi-matrix Factorization Attention (MFA) and MFA-Key-Reuse (MFA-KR). Existing variants for standard Multi-Head Attention (MHA), including SOTA methods like MLA, fail to maintain as strong performance under stringent Key-Value cache (KV cache) constraints. MFA enhances model capacity by efficiently scaling up both the number and dimension of attention heads through low-rank matrix factorization in the Query-Key (QK) circuit. Extending MFA, MFA-KR further reduces memory requirements by repurposing the key cache as value through value projection re-parameterization. MFA's design enables strong model capacity when working under tight KV cache budget, while MFA-KR is suitable for even harsher KV cache limits with minor performance trade-off. Notably, in our extensive and large-scale experiments, the proposed architecture outperforms MLA and performs comparably to MHA, while reducing KV cache usage by up to 56% and 93.7%, respectively.
M3GIA: A Cognition Inspired Multilingual and Multimodal General Intelligence Ability Benchmark
Jun 08, 2024

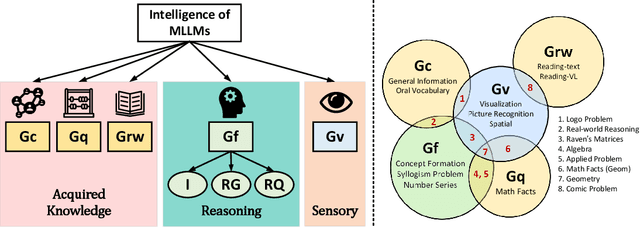

As recent multi-modality large language models (MLLMs) have shown formidable proficiency on various complex tasks, there has been increasing attention on debating whether these models could eventually mirror human intelligence. However, existing benchmarks mainly focus on evaluating solely on task performance, such as the accuracy of identifying the attribute of an object. Combining well-developed cognitive science to understand the intelligence of MLLMs beyond superficial achievements remains largely unexplored. To this end, we introduce the first cognitive-driven multi-lingual and multi-modal benchmark to evaluate the general intelligence ability of MLLMs, dubbed M3GIA. Specifically, we identify five key cognitive factors based on the well-recognized Cattell-Horn-Carrol (CHC) model of intelligence and propose a novel evaluation metric. In addition, since most MLLMs are trained to perform in different languages, a natural question arises: is language a key factor influencing the cognitive ability of MLLMs? As such, we go beyond English to encompass other languages based on their popularity, including Chinese, French, Spanish, Portuguese and Korean, to construct our M3GIA. We make sure all the data relevant to the cultural backgrounds are collected from their native context to avoid English-centric bias. We collected a significant corpus of data from human participants, revealing that the most advanced MLLM reaches the lower boundary of human intelligence in English. Yet, there remains a pronounced disparity in the other five languages assessed. We also reveals an interesting winner takes all phenomenon that are aligned with the discovery in cognitive studies. Our benchmark will be open-sourced, with the aspiration of facilitating the enhancement of cognitive capabilities in MLLMs.
GIPA++: A General Information Propagation Algorithm for Graph Learning
Jan 19, 2023Graph neural networks (GNNs) have been widely used in graph-structured data computation, showing promising performance in various applications such as node classification, link prediction, and network recommendation. Existing works mainly focus on node-wise correlation when doing weighted aggregation of neighboring nodes based on attention, such as dot product by the dense vectors of two nodes. This may cause conflicting noise in nodes to be propagated when doing information propagation. To solve this problem, we propose a General Information Propagation Algorithm (GIPA in short), which exploits more fine-grained information fusion including bit-wise and feature-wise correlations based on edge features in their propagation. Specifically, the bit-wise correlation calculates the element-wise attention weight through a multi-layer perceptron (MLP) based on the dense representations of two nodes and their edge; The feature-wise correlation is based on the one-hot representations of node attribute features for feature selection. We evaluate the performance of GIPA on the Open Graph Benchmark proteins (OGBN-proteins for short) dataset and the Alipay dataset of Alibaba. Experimental results reveal that GIPA outperforms the state-of-the-art models in terms of prediction accuracy, e.g., GIPA achieves an average ROC-AUC of $0.8901\pm 0.0011$, which is better than that of all the existing methods listed in the OGBN-proteins leaderboard.
Path-based Deep Network for Candidate Item Matching in Recommenders
May 18, 2021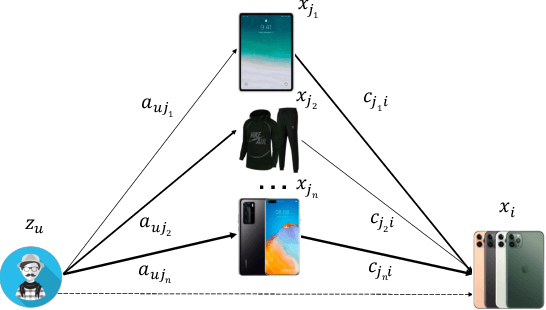
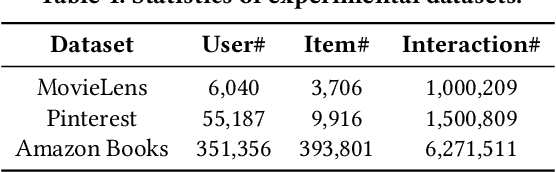
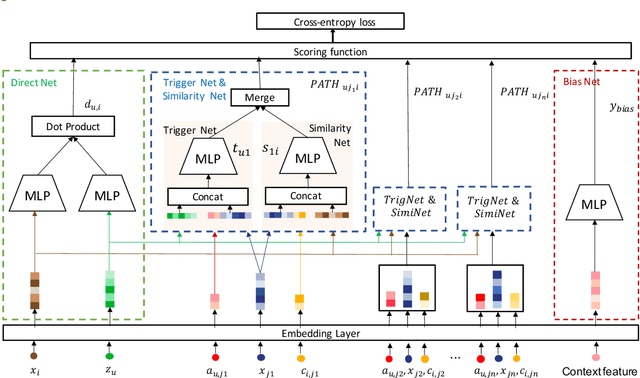
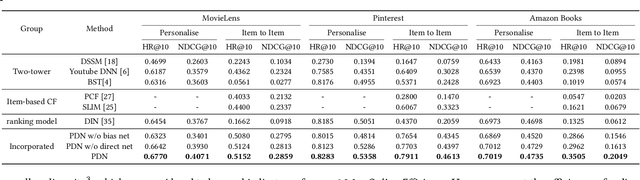
The large-scale recommender system mainly consists of two stages: matching and ranking. The matching stage (also known as the retrieval step) identifies a small fraction of relevant items from billion-scale item corpus in low latency and computational cost. Item-to-item collaborative filter (item-based CF) and embedding-based retrieval (EBR) have been long used in the industrial matching stage owing to its efficiency. However, item-based CF is hard to meet personalization, while EBR has difficulty in satisfying diversity. In this paper, we propose a novel matching architecture, Path-based Deep Network (named PDN), which can incorporate both personalization and diversity to enhance matching performance. Specifically, PDN is comprised of two modules: Trigger Net and Similarity Net. PDN utilizes Trigger Net to capture the user's interest in each of his/her interacted item, and Similarity Net to evaluate the similarity between each interacted item and the target item based on these items' profile and CF information. The final relevance between the user and the target item is calculated by explicitly considering user's diverse interests, \ie aggregating the relevance weights of the related two-hop paths (one hop of a path corresponds to user-item interaction and the other to item-item relevance). Furthermore, we describe the architecture design of a matching system with the proposed PDN in a leading real-world E-Commerce service (Mobile Taobao App). Based on offline evaluations and online A/B test, we show that PDN outperforms the existing solutions for the same task. The online results also demonstrate that PDN can retrieve more personalized and more diverse relevant items to significantly improve user engagement. Currently, PDN system has been successfully deployed at Mobile Taobao App and handling major online traffic.
GIPA: General Information Propagation Algorithm for Graph Learning
May 13, 2021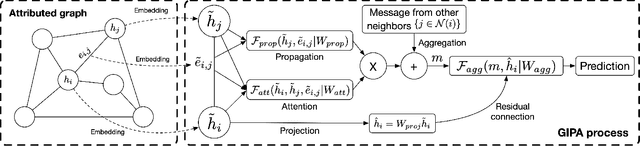
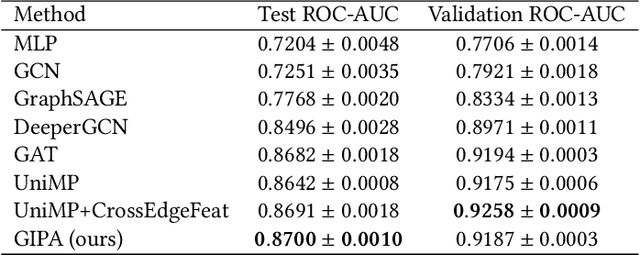
Graph neural networks (GNNs) have been popularly used in analyzing graph-structured data, showing promising results in various applications such as node classification, link prediction and network recommendation. In this paper, we present a new graph attention neural network, namely GIPA, for attributed graph data learning. GIPA consists of three key components: attention, feature propagation and aggregation. Specifically, the attention component introduces a new multi-layer perceptron based multi-head to generate better non-linear feature mapping and representation than conventional implementations such as dot-product. The propagation component considers not only node features but also edge features, which differs from existing GNNs that merely consider node features. The aggregation component uses a residual connection to generate the final embedding. We evaluate the performance of GIPA using the Open Graph Benchmark proteins (ogbn-proteins for short) dataset. The experimental results reveal that GIPA can beat the state-of-the-art models in terms of prediction accuracy, e.g., GIPA achieves an average ROC-AUC of $0.8700\pm 0.0010$ and outperforms all the previous methods listed in the ogbn-proteins leaderboard.