 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLossless and Privacy-Preserving Graph Convolution Network for Federated Item Recommendation
Dec 02, 2024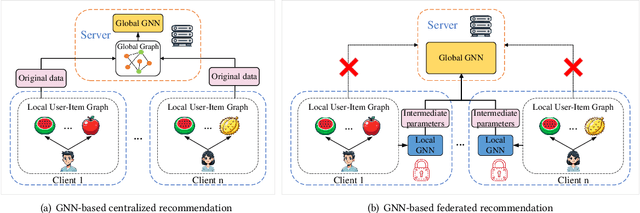


Graph neural network (GNN) has emerged as a state-of-the-art solution for item recommendation. However, existing GNN-based recommendation methods rely on a centralized storage of fragmented user-item interaction sub-graphs and training on an aggregated global graph, which will lead to privacy concerns. As a response, some recent works develop GNN-based federated recommendation methods by exploiting decentralized and fragmented user-item sub-graphs in order to preserve user privacy. However, due to privacy constraints, the graph convolution process in existing federated recommendation methods is incomplete compared with the centralized counterpart, causing a degradation of the recommendation performance. In this paper, we propose a novel lossless and privacy-preserving graph convolution network (LP-GCN), which fully completes the graph convolution process with decentralized user-item interaction sub-graphs while ensuring privacy. It is worth mentioning that its performance is equivalent to that of the non-federated (i.e., centralized) counterpart. Moreover, we validate its effectiveness through both theoretical analysis and empirical studies. Extensive experiments on three real-world datasets show that our LP-GCN outperforms the existing federated recommendation methods. The code will be publicly available once the paper is accepted.
Why Perturbing Symbolic Music is Necessary: Fitting the Distribution of Never-used Notes through a Joint Probabilistic Diffusion Model
Aug 04, 2024Existing music generation models are mostly language-based, neglecting the frequency continuity property of notes, resulting in inadequate fitting of rare or never-used notes and thus reducing the diversity of generated samples. We argue that the distribution of notes can be modeled by translational invariance and periodicity, especially using diffusion models to generalize notes by injecting frequency-domain Gaussian noise. However, due to the low-density nature of music symbols, estimating the distribution of notes latent in the high-density solution space poses significant challenges. To address this problem, we introduce the Music-Diff architecture, which fits a joint distribution of notes and accompanying semantic information to generate symbolic music conditionally. We first enhance the fragmentation module for extracting semantics by using event-based notations and the structural similarity index, thereby preventing boundary blurring. As a prerequisite for multivariate perturbation, we introduce a joint pre-training method to construct the progressions between notes and musical semantics while avoiding direct modeling of low-density notes. Finally, we recover the perturbed notes by a multi-branch denoiser that fits multiple noise objectives via Pareto optimization. Our experiments suggest that in contrast to language models, joint probability diffusion models perturbing at both note and semantic levels can provide more sample diversity and compositional regularity. The case study highlights the rhythmic advantages of our model over language- and DDPMs-based models by analyzing the hierarchical structure expressed in the self-similarity metrics.
M3GIA: A Cognition Inspired Multilingual and Multimodal General Intelligence Ability Benchmark
Jun 08, 2024

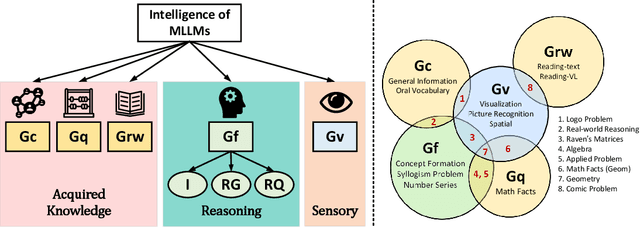

As recent multi-modality large language models (MLLMs) have shown formidable proficiency on various complex tasks, there has been increasing attention on debating whether these models could eventually mirror human intelligence. However, existing benchmarks mainly focus on evaluating solely on task performance, such as the accuracy of identifying the attribute of an object. Combining well-developed cognitive science to understand the intelligence of MLLMs beyond superficial achievements remains largely unexplored. To this end, we introduce the first cognitive-driven multi-lingual and multi-modal benchmark to evaluate the general intelligence ability of MLLMs, dubbed M3GIA. Specifically, we identify five key cognitive factors based on the well-recognized Cattell-Horn-Carrol (CHC) model of intelligence and propose a novel evaluation metric. In addition, since most MLLMs are trained to perform in different languages, a natural question arises: is language a key factor influencing the cognitive ability of MLLMs? As such, we go beyond English to encompass other languages based on their popularity, including Chinese, French, Spanish, Portuguese and Korean, to construct our M3GIA. We make sure all the data relevant to the cultural backgrounds are collected from their native context to avoid English-centric bias. We collected a significant corpus of data from human participants, revealing that the most advanced MLLM reaches the lower boundary of human intelligence in English. Yet, there remains a pronounced disparity in the other five languages assessed. We also reveals an interesting winner takes all phenomenon that are aligned with the discovery in cognitive studies. Our benchmark will be open-sourced, with the aspiration of facilitating the enhancement of cognitive capabilities in MLLMs.
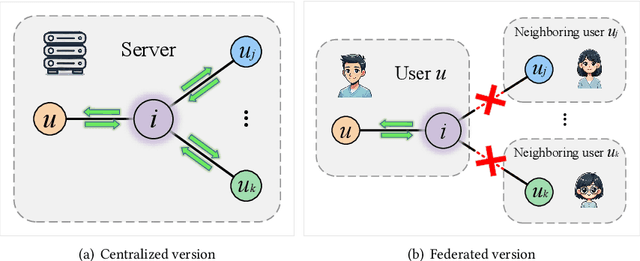
GNN4FR: A Lossless GNN-based Federated Recommendation Framework
Jul 25, 2023



Graph neural networks (GNNs) have gained wide popularity in recommender systems due to their capability to capture higher-order structure information among the nodes of users and items. However, these methods need to collect personal interaction data between a user and the corresponding items and then model them in a central server, which would break the privacy laws such as GDPR. So far, no existing work can construct a global graph without leaking each user's private interaction data (i.e., his or her subgraph). In this paper, we are the first to design a novel lossless federated recommendation framework based on GNN, which achieves full-graph training with complete high-order structure information, enabling the training process to be equivalent to the corresponding un-federated counterpart. In addition, we use LightGCN to instantiate an example of our framework and show its equivalence.
More Perspectives Mean Better: Underwater Target Recognition and Localization with Multimodal Data via Symbiotic Transformer and Multiview Regression
May 22, 2023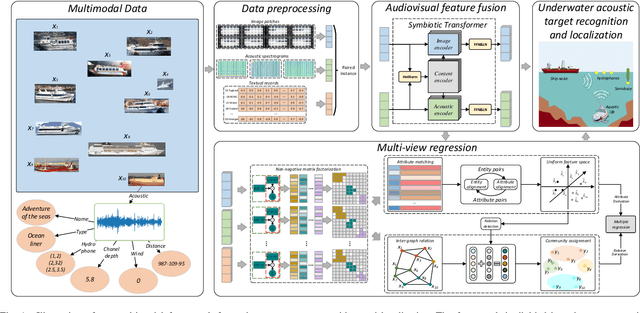

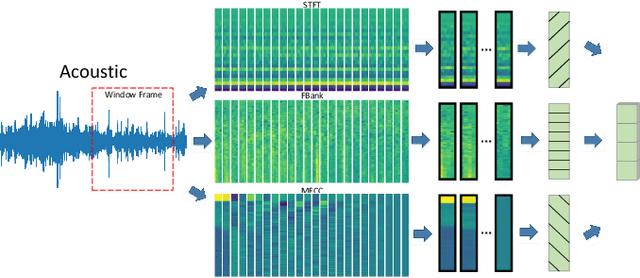
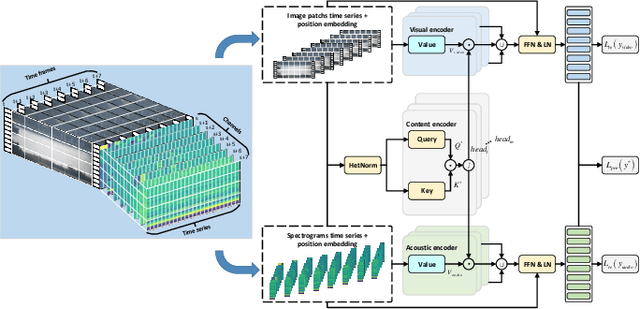
Underwater acoustic target recognition (UATR) and localization (UATL) play important roles in marine exploration. The highly noisy acoustic signal and time-frequency interference among various sources pose big challenges to this task. To tackle these issues, we propose a multimodal approach to extract and fuse audio-visual-textual information to recognize and localize underwater targets through the designed Symbiotic Transformer (Symb-Trans) and Multi-View Regression (MVR) method. The multimodal data were first preprocessed by a custom-designed HetNorm module to normalize the multi-source data in a common feature space. The Symb-Trans module embeds audiovisual features by co-training the preprocessed multimodal features through parallel branches and a content encoder with cross-attention. The audiovisual features are then used for underwater target recognition. Meanwhile, the text embedding combined with the audiovisual features is fed to an MVR module to predict the localization of the underwater targets through multi-view clustering and multiple regression. Since no off-the-shell multimodal dataset is available for UATR and UATL, we combined multiple public datasets, consisting of acoustic, and/or visual, and/or textural data, to obtain audio-visual-textual triplets for model training and validation. Experiments show that our model outperforms comparative methods in 91.7% (11 out of 12 metrics) and 100% (4 metrics) of the quantitative metrics for the recognition and localization tasks, respectively. In a case study, we demonstrate the advantages of multi-view models in establishing sample discriminability through visualization methods. For UATL, the proposed MVR method produces the relation graphs, which allow predictions based on records of underwater targets with similar conditions.
The Power of Reuse: A Multi-Scale Transformer Model for Structural Dynamic Segmentation in Symbolic Music Generation
May 17, 2022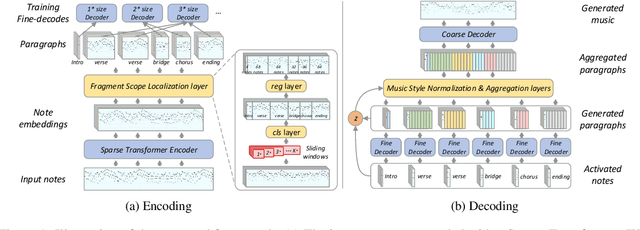
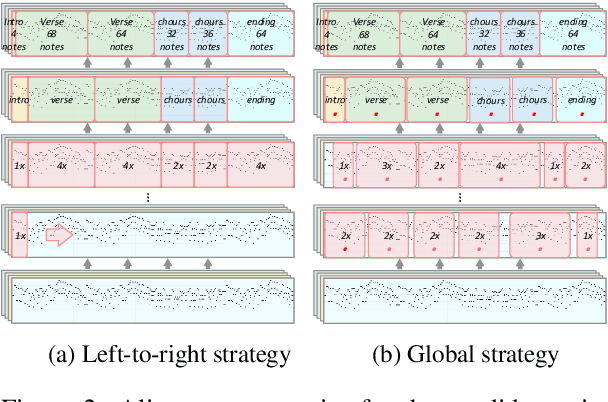
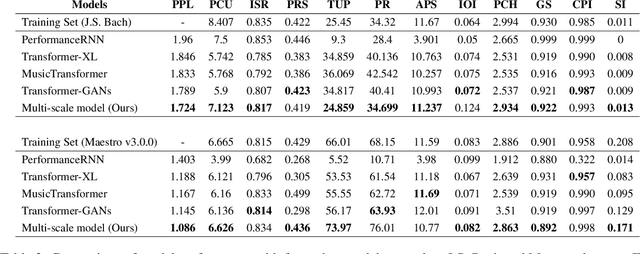
Symbolic Music Generation relies on the contextual representation capabilities of the generative model, where the most prevalent approach is the Transformer-based model. Not only that, the learning of long-term context is also related to the dynamic segmentation of musical structures, i.e. intro, verse and chorus, which is currently overlooked by the research community. In this paper, we propose a multi-scale Transformer, which uses coarse-decoder and fine-decoders to model the contexts at the global and section-level, respectively. Concretely, we designed a Fragment Scope Localization layer to syncopate the music into sections, which were later used to pre-train fine-decoders. After that, we designed a Music Style Normalization layer to transfer the style information from the original sections to the generated sections to achieve consistency in music style. The generated sections are combined in the aggregation layer and fine-tuned by the coarse decoder. Our model is evaluated on two open MIDI datasets, and experiments show that our model outperforms the best contemporary symbolic music generative models. More excitingly, visual evaluation shows that our model is superior in melody reuse, resulting in more realistic music.